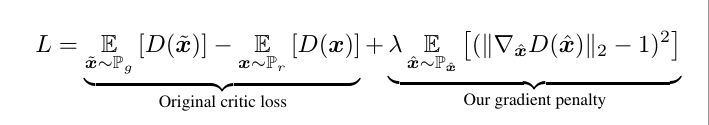I was reading Improved Training of Wasserstein GANs, and thinking how it could be implemented in PyTorch. It seems not so complex but how to handle gradient penalty in loss troubles me.
In the tensorflow’s implementation, the author use tf.gradients.
I wonder if there is an easy way to handle the gradient penalty.
here is my idea of implementing it, I don’t know whether it will work and work in the way I think:
For the moment, it’s not yet possible to have gradients of gradients in PyTorch, but there is a pending PR that will implement that and should be merged soon.
Thank you, I had a look into this but from what I see torch doesn’t have yet support for higher-order derivates of Non-linear functions present in the DCGAN model. Or am I wrong?
You are right, most function are still old-style which don’t support grad of grad.
There is a temporary fix: use difference rather than differential
x_1,x_2 are sampled from x_hat
idea from 郑华滨
Ajay and I discussed that a bit a while ago and there is a link to a blog post and Jupyter notebook doing the toy examples from the improved training article in pytorch:
thank you for the credit. I might be among the first to discuss this in detail in this specific context and with a pytorch implementation, but certainly the identification of 1-Lipschitz (in the classical definition) with unit sphere in $W_{1,\infty}$ in the Sobolev scale (which is the fancy mathematician talk for the gradient being bounded by 1) is very standard just as the approximation of the derivative by finite differences (actually, one could fancy-talk that into a different norm, but let’s not), so I would expect many other people to have the same idea independently, so I’d go for coincidence. (Actually sampling two points is a bit different to sampling the center and using the two side points as I did, too.)
What struck me as particularly curious in this case is why the authors of Improved Training chose to do a point-wise derivative test instead of testing the Lipschitz constant directly, but I have not asked them yet, so I don’t know.
I first find the idea from zhihu(Chinese Quora). The author seems to simply use the difference as an approximation of differential. But someone commented in the article that the difference is actually a better way for Kantorovich dual problem.
The blog from @tom seems both more insightful and more intuitive. Excellent work!
just a quick update:
A discussed in the SLOGAN blog post, the difference in the is generally not the gradient, but a projection onto x_hat. Thus it would seem to be more prudent to use a one-sided penalty in this formulation.