Hello,
I’m trying to calculate the gradient of the output of a simple neural network with respect to the inputs. The result looks fine when I don’t use a BatchNorm layer. Once I do use it, the result doesn’t seem to make much sense. Below is a short example to reproduce the effect.
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
class Net(nn.Module):
def __init__(self, batch_norm):
super().__init__()
self.batch_norm = batch_norm
self.act_fn = nn.Tanh()
self.aff1 = nn.Linear(1, 10)
self.aff2 = nn.Linear(10, 1)
if batch_norm:
self.bn = nn.BatchNorm1d(10, affine=False) # False for simplicity
def forward(self, x):
x = self.aff1(x)
x = self.act_fn(x)
if self.batch_norm:
x = self.bn(x)
x = self.aff2(x)
return x
x_vals = torch.linspace(0, 1, 100)
x_vals.requires_grad = True
fig, axs = plt.subplots(ncols=2, figsize=(16, 5))
for seed, bn, ax1 in zip([11, 7], [False, True], axs): # different seeds for better illustration of effect
torch.manual_seed(seed)
net = Net(batch_norm=bn)
net.train()
pred = net(x_vals[:, None])
pred_dx = torch.autograd.grad(pred.sum(), x_vals, create_graph=True)[0]
# visualization
ax2 = ax1.twinx()
ax1.plot(x_vals.detach(), pred.detach())
ax2.plot(x_vals.detach(), pred_dx.detach(), linestyle='--', color='orange')
min_idx = torch.argmin((pred[1:]-pred[:-1])**2)
ax2.axvline(x_vals[min_idx].detach(), color='gray', linestyle='dotted')
ax2.axhline(0, color='gray', linestyle='dotted')
ax1.set_title(('With' if bn else 'Without') + ' Batch Norm')
plt.show()
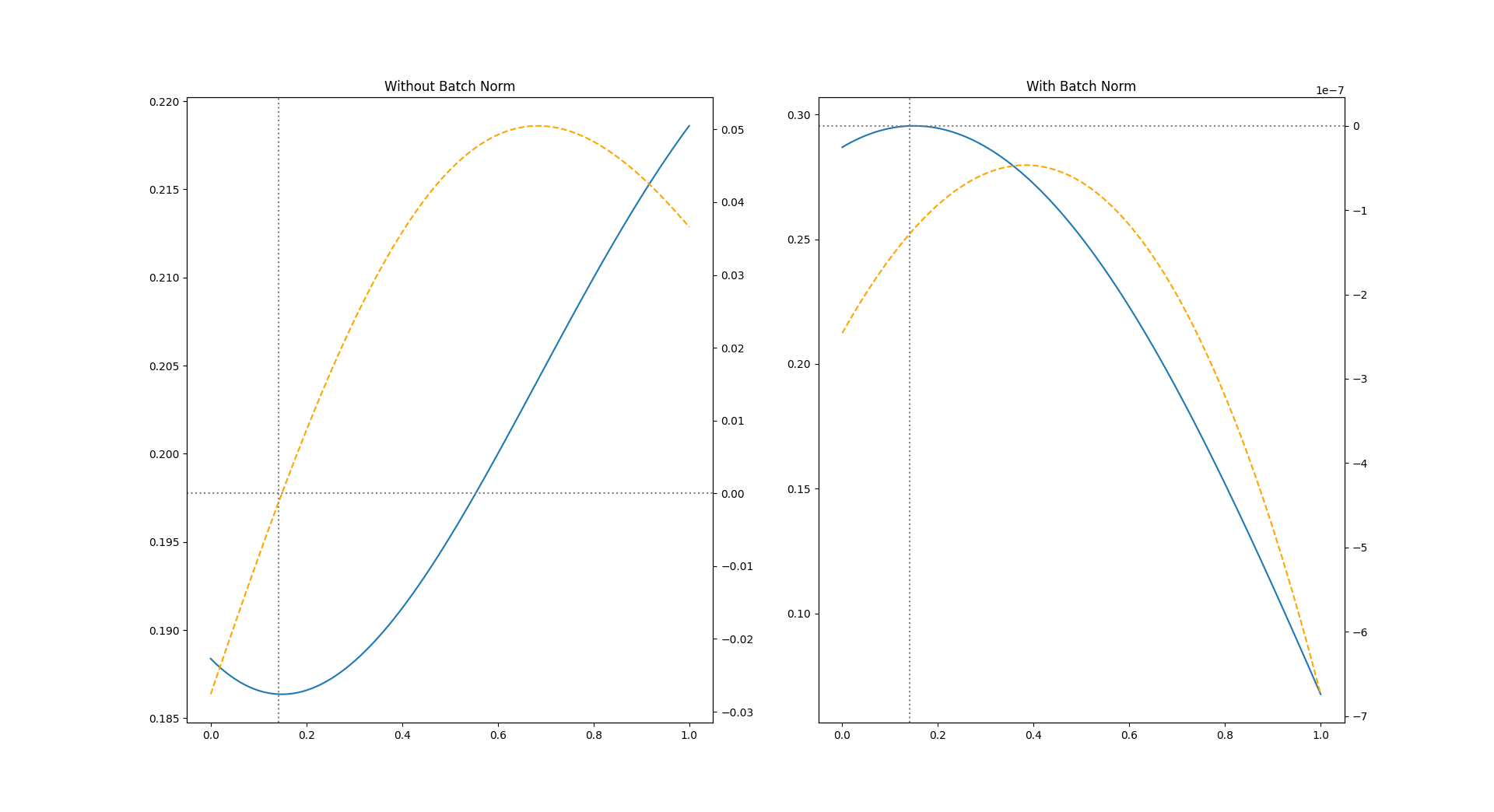
The result also seems to be fine when I use evaluation mode. Unfortunately I can’t just switch to eval() mode because the nature of my problem (PINNs) requires calculating these gradients during training.
This question is probably related to the post The gradients of BatchNorm layer at mode of model.train() and model.eval() to which there are no answers.
I’m using python version 3.9.5, pytorch version 1.9.0+cu102.
Thanks for your help!