Hi guys, I have bulid a simple network like
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.cnn = nn.Conv2d(1, 1, 4, 2, 1)
self.bn = nn.BatchNorm2d(1)
self.fc = nn.Linear(16, 2)
def forward(self,x):
x = self.cnn(x)
x = self.bn(x)
x = x.view(-1, 16)
x = self.fc(x)
return x
And I input a same random sample X to the network at model.train() and model.eval(). I know the ‘running_mean’ and the ‘running_var’ would change when forward propagation at model.train() but would’t change at model.eval(), so I have replace the values of mean and var at model.eval() as the values at model.train(). So the parameters and output is the same at both two mode.
output of two modes
out
train tensor([[-0.6198, 0.0471]], device=‘cuda:0’, grad_fn=)
eval tensor([[-0.6198, 0.0471]], device=‘cuda:0’, grad_fn=)
parameters of two modes
train Parameter containing:
tensor([[[[-0.1379, 0.0229, -0.0143, 0.0128],
[-0.0239, -0.0240, 0.0798, -0.0504],
[-0.2342, 0.1400, -0.2099, -0.1185],
[ 0.0443, 0.0067, -0.0232, -0.1900]]]], device=‘cuda:0’,
requires_grad=True)
eval Parameter containing:
tensor([[[[-0.1379, 0.0229, -0.0143, 0.0128],
[-0.0239, -0.0240, 0.0798, -0.0504],
[-0.2342, 0.1400, -0.2099, -0.1185],
[ 0.0443, 0.0067, -0.0232, -0.1900]]]], device=‘cuda:0’,
requires_grad=True)
However, when I calculate the gradients, I found the gradients of the layers before BatchNorm layer(Layer 0 1) are different at model.train() and model.eval()(the gradients of layers after BatchNorm(Layer 2 3 4 5) are still the same).
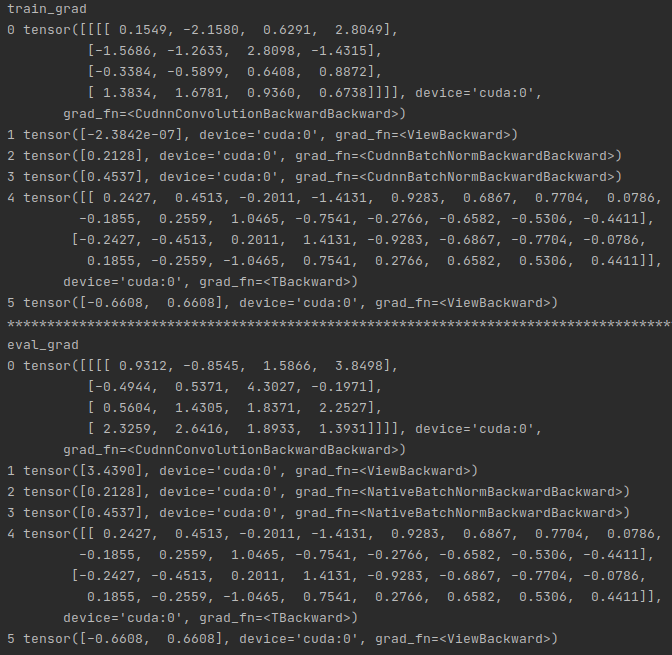
I think it’s because the different backpropagations of BatchNorm layer at model.train() and model.eval(). But I could’t understand it. Does anyone know the detail of BatchNorm backpropagation at these two modes? Or how can I freeze the ‘running_mean’ and ‘running_mean’ at the forward propagation at model.train()? Thank you so much!