Hi I am currently working on some profiling of my model and I have some question about memory allocation with torch.
The code I am using is :
device=torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
torch.cuda.memory._record_memory_history(True,True,1000,True,device,True)
xQuery = torch.randn(1,259, 259,128).to(device)
xFocalMaps=[torch.randn(1, 259, 259, 128).to(device), torch.randn(1, 130, 130, 128).to(device), torch.randn(1,65, 65, 128).to(device)]
qkv=self.qkv(xQuery) # LINEAR(123,3*128)
s=torch.cuda.memory._snapshot()
with open("MySnapshot.pickle", "wb") as f:
pickle.dump(s, f)
I will describe it quickly
→ XQuery a float32 tensor (1,259,259,128) so allocated memory is 4*128*259*259 / 1024**2 = 32,8Mb.
→ XFocalMap 3 float 32 tensors of different shapes (I will give direct size result) of size [ 32,8Mb ; 8,3Mb ; 2,1Mb ].
→ self.qkv is Linear layer (as it is already initialized it is already allocated in memory)
→ thus self.qkv(XQuery) will give a (1,259,259,3*128) float32 tensor = 98.3Mb.
I use preforward and postforward hooks that print the cuda allocated memory in console, and I use memory snapshot as you can see in the code.
layer_idx call_idx layer_type exp hook_type mem_all mem_cached mem_all_diff mem_cached_diff
0 1 0 Linear baseline pre 81.884766 90.0 0.000000 0.0
1 1 1 Linear baseline fwd 188.272949 210.0 106.388184 120.0
This is the result given by the hooks preforward and post forward of self.qkv(XQuery) : the difference between Pre and post allocated cuda memory is 106,4Mb > 98.3Mb.
This means that the result of self.qkv(XQuery) produces a 98.3Mb tensor and… something else which is 8.1Mb.
Using the snapshot of the memory I get the following allocation scheme :
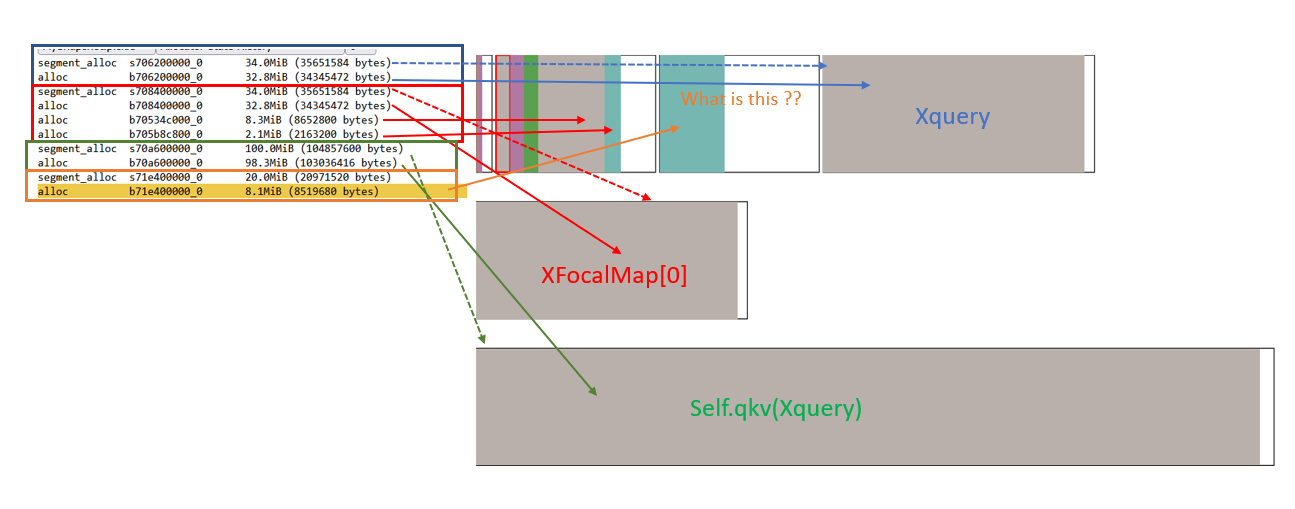
This picture shows the allocation of each XQuery, self.qkv(XQuery), XFocalMaps and my “somethingElseObject” of 8.1Mb in orange.
Do you have an idea of what it could be ? What else other than the output is saved in the memory during the forward operation ?
Thank you for help