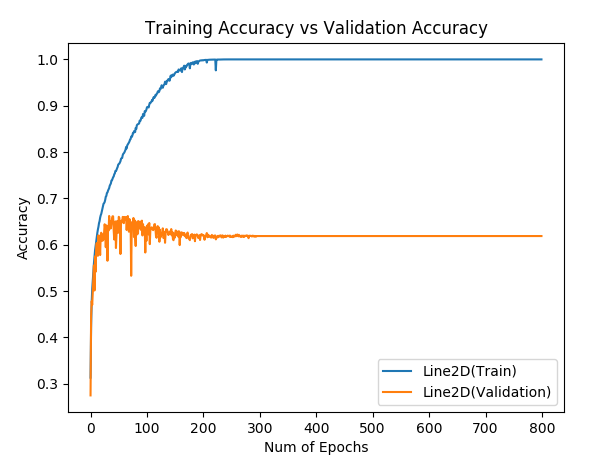
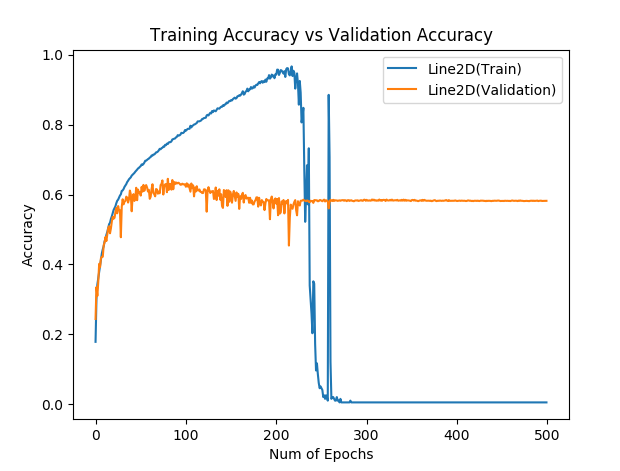
The main part of the script was:
import time
import numpy as np
import torch
from torch.autograd import Variable
from maps import NamedDict
import data_utils
import utils
from pdb import set_trace as st
def evalaute_mdl_data_set(loss,error,net,dataloader,enable_cuda):
'''
Evaluate the error of the model under some loss and error with a specific data set.
'''
running_loss,running_error = 0,0
for i,data in enumerate(dataloader):
inputs, labels = extract_data(enable_cuda,data,wrap_in_variable=True)
outputs = net(inputs)
running_loss += loss(outputs,labels).data[0]
running_error += error(outputs,labels)
return running_loss/(i+1),running_error/(i+1)
def extract_data(enable_cuda,data,wrap_in_variable=False):
inputs, labels = data
if enable_cuda:
inputs, labels = inputs.cuda(), labels.cuda()
if wrap_in_variable:
inputs, labels = Variable(inputs), Variable(labels)
return inputs, labels
def train_and_track_stats(args, nb_epochs, trainloader,testloader, net,optimizer,criterion,error_criterion ,stats_collector):
enable_cuda = args.enable_cuda
##
print('about to start training')
for epoch in range(nb_epochs): # loop over the dataset multiple times
running_train_loss,running_train_error = 0.0,0.0
for i,data_train in enumerate(trainloader):
''' zero the parameter gradients '''
optimizer.zero_grad()
''' train step = forward + backward + optimize '''
inputs, labels = extract_data(enable_cuda,data_train,wrap_in_variable=True)
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_train_loss += loss.data[0]
running_train_error += error_criterion(outputs,labels)
''' print error first iteration'''
if i == 0 and epoch == 0: # print on the first iteration
print(inputs)
''' End of Epoch: collect stats'''
train_loss_epoch, train_error_epoch = running_train_loss/(i+1), running_train_error/(i+1)
test_loss_epoch, test_error_epoch = evalaute_mdl_data_set(criterion,error_criterion,net,testloader,enable_cuda)
stats_collector.collect_mdl_params_stats(net)
stats_collector.append_losses_errors_accs(train_loss_epoch, train_error_epoch, test_loss_epoch, test_error_epoch)
print(f'[{epoch}, {i+1}], (train_loss: {train_loss_epoch}, train error: {train_error_epoch}) , (test loss: {test_loss_epoch}, test error: {test_error_epoch})')
return train_loss_epoch, train_error_epoch, test_loss_epoch, test_error_epoch
the rest like net and criterion are just standard things I called from the pytorch library.
Yes, there was ReLU. I was not careful enough when this happened and don’t know what pytorch version did this. But I am pretty sure it was something bellow 0.3. It was on GPU (it takes forever to train 400 epochs of cifar10 on cpu). Feel free to ask me for anything else you might need! 
Error criterion might be important. Let me share it. Its just a function pointer/handle pointing to:
def error_criterion(outputs,labels):
max_vals, max_indices = torch.max(outputs,1)
train_acc = (max_indices != labels).sum().data[0]/max_indices.size()[0]
return train_acc