In my case, the Pytorch seems ambitious to hold so much memory, and not free it give it back to cuda, I think it’s unreasonable, and I know it’s possible to free it through insert torch API in specific places in our code. But I want to find if there is some other ways to change the way that Pytorch allocate and cache the memory? Or, if it’s possible we can add our own memory management logic to the Pytorch backend?
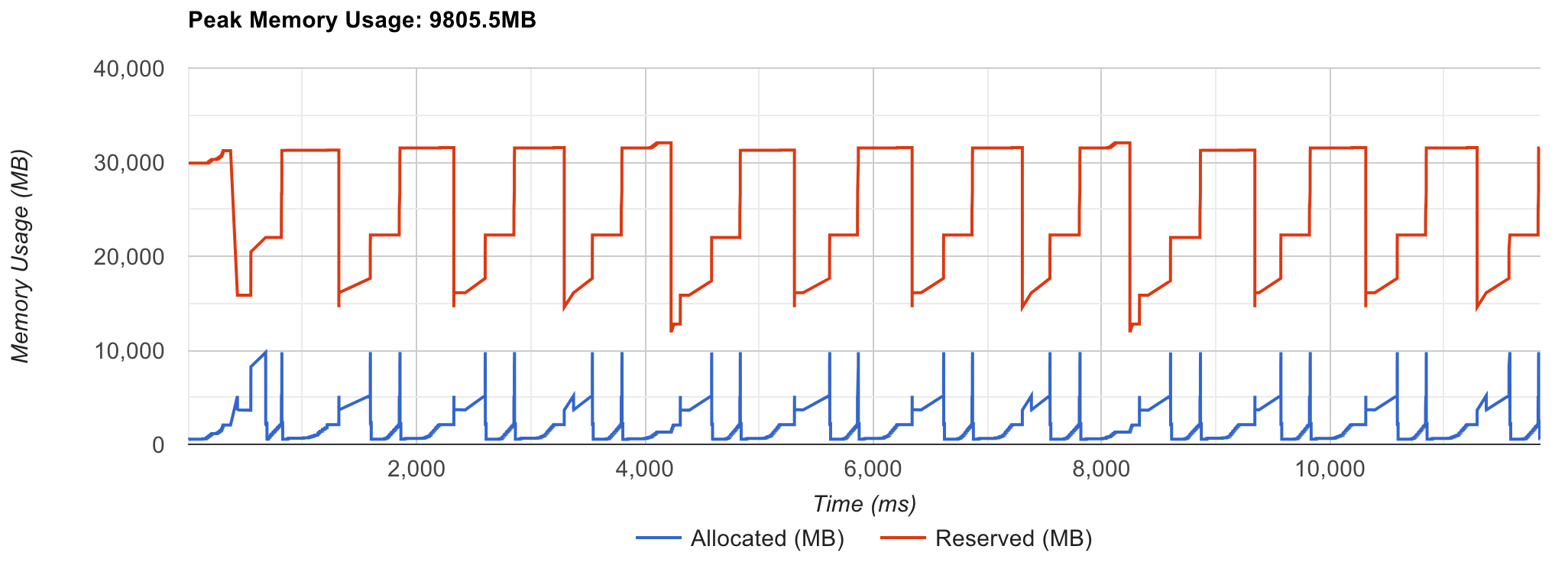
It’s not unreasonable to use a caching mechanism since releasing the memory to the system via cudaFree (and the need to reallocate the memory again via cudaMalloc) using the default memory allocator is synchronizing and expensive. If you don’t want to use the caching mechanism, you can disable it via PYTORCH_NO_CUDA_MEMORY_CACHING=1.
To implement your own allocator you can use the CUDAPluggableAllocator as described here or a custom MemPool.
Thanks, ptrblck. I have another question. If I only have 20 GB of GPU capacity, will my application run out of memory? I understand that keeping some cache can improve performance. So, can Pytorch set a threshold to keep the reserved memory below that threshold instead of not using memory caching?
It’s unclear what exactly lands in the cache and if some libraries use e.g. a larger workspace since your current device has enough memory. If you are seeing a large difference between the cached and allocated memory, you could try to use expandable_segments as descried here.
Yes, you can limit the available memory in the current PyTorch process via torch.cuda.set_per_process_memory_fraction.