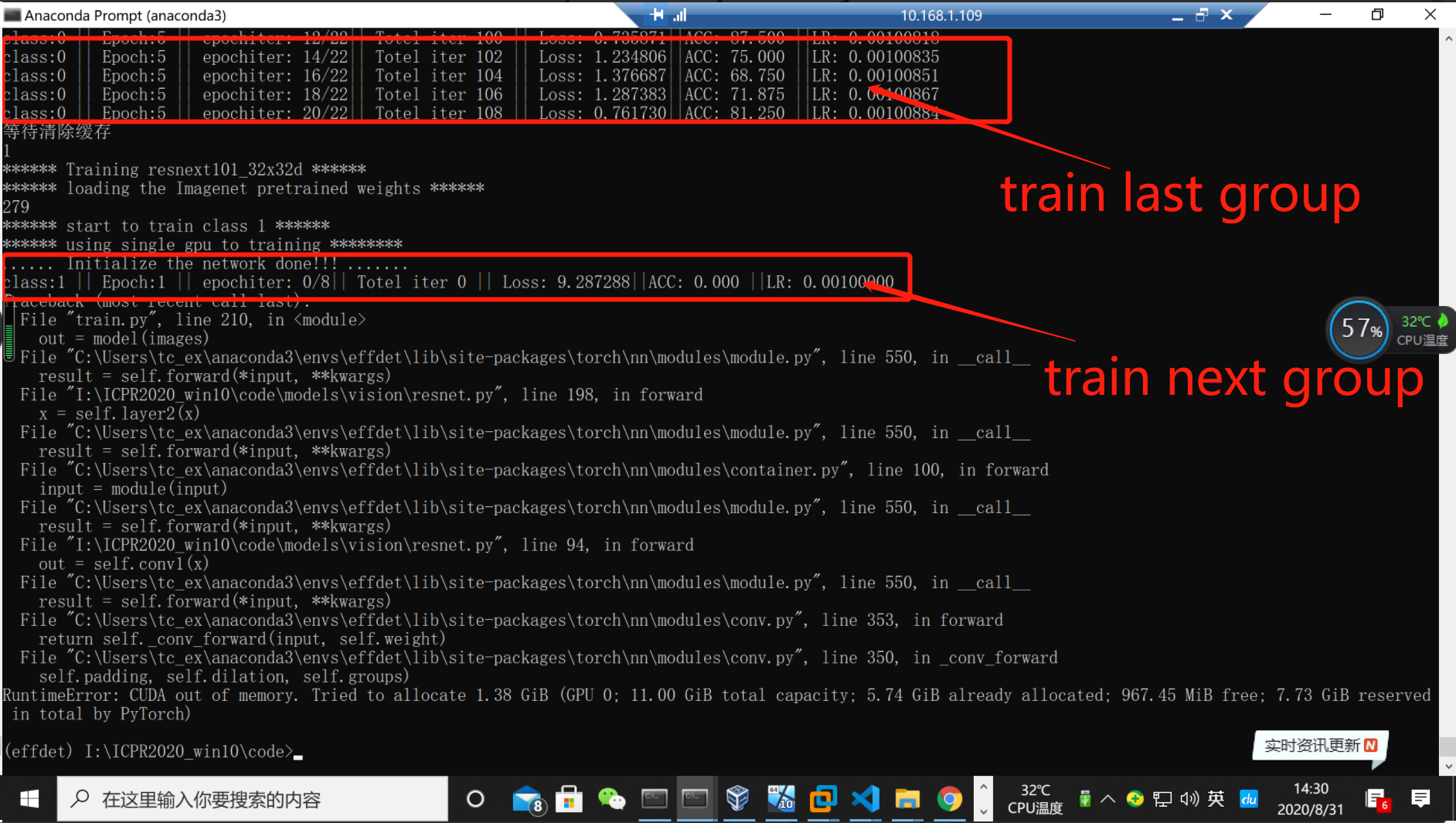
I need to train the image classifiers in different groups. When one group is trained, the script will automatically load and train the next group by “for” statements.
But an error occurred saying there was not enough memory in GPU when it start to train the next group. How can I clear the GPU memory used by the last group training before the script start train the next group?
l have try to use torch.cuda.empty_cache() after each group training finished but it doesn’t work.
time.sleep(5)
del model
del loss
gc.collect()
torch.cuda.empty_cache()#清空GPU缓存
# print(torch.cuda.memory_stats(0))
time.sleep(10)
torch.cuda.empty_cache()#清空GPU缓存
# print(torch.cuda.memory_stats(0))
Pytorch’s version is 1.6.0