Hello everyone,
as far as I understand, the grey cell maintains the shape [batch, sequence, dim] all the way through.
So during infernece, how is last decoder cell supposed to give the probabilities of a single word, if the output shape is [batch, sequence, dim] with sequence > 1 ?
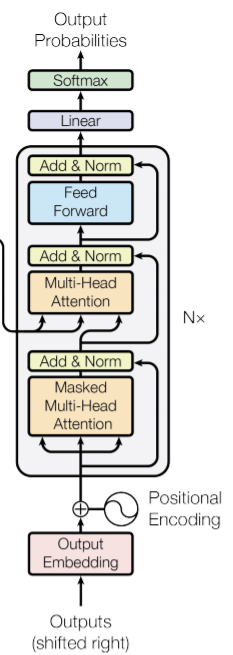
My hypothesis is the following, is that correct?
iteration 1: dec_inp = [start] → dec_out = [y0] append last out element to input (here: y0)
iteration 2: dec_inp = [start, y0] → dec_out = [y0, y1] append last out element to input (here: y1)
iteration 3: dec_inp = [start, y0,y1] → dec_out = [y0, y1,y2]
So you do not actually predict one word, but the whole sequence that you have ‘so far’ and then append the last element of that sequence to the input of the new iteration.
Thanks in advance