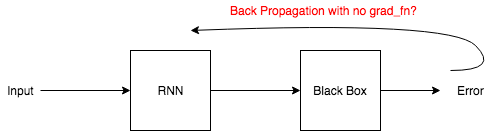
I want to minimize the error generated by my black box but there is no grad_fn attached to it. How could the autograd know what to do with this loss value?
I want to minimize the error generated by my black box but there is no grad_fn attached to it. How could the autograd know what to do with this loss value?
Autograd cannot create the backward pass without a grad_fn and you should get an error like:
RuntimeError: element 0 of tensors does not require grad and does not have a grad_fn
Did you detach the tensor manually from the computation graph or what is your exact use case?
The thing is the value generated by RNN is “interpreted”. No computations are made on it in blackbox so the error generated is detached. Is there any way I could backpropagate to minimize that detached error (by somehow manually attaching it).
The only valid way I could think of at the moment, is to write the backward function manually for your blackbox methods.
The blackbox is a simulation, I do not think it is possible to write a backward for it. I attempted to call back() on the output of RNN directly giving the error as all the gradients, it failed the system.
The computation graph is built during the forward pass and is used in the backward pass to calculate the gradients.
If you are detaching some tensors from the graph, you would need to write the backward manually, as explained.
If that’s not possible, you won’t be able to compute the gradients using the standard backward call.
Maybe some other training approaches might work (e.g. evolutionary algorithms)?
Hi,
I have a same problem.
How did you solve the problem.
I don’t know how to get the gradient of black box.
Best.
I am facing a similar problem. I apply RNN (LSTM/ or GRU or TFT) to generate driving signals, however, there is no label data(target signal) to calculate loss function directly. However, there is one-to-one relationship (pre-known with certain unknown noises) between the driving signals and the response signal. The response signal has target data to generate loss function.
I am wondering to applied decoder (another LSTM to model the relation-ship between driving signal and the response), however, this might increase the complexity (since the relationship between driving signal and the response is 90% known in advance).
Now I am learning the autograd of Pytorch, hoping that the parameters of RNN could be auto-corrected by the indirect loss function. I try to make the response signal to be (requires_grad=True), however, it does not update the model at all, since the loss keeps all the same during training.
Any suggestion?
Best regards.
Hi!
Perhaps you could use a so-called straight through estimator to bypass the black-box?
See e.g.
Best regards
Thank you so much for the fast reply. I will research on it and update the results.
Best
Hi, I try to apply the STE and self-defined function for indirect loss-function calculation. There are several questions listed below.
Here are the snippet of my code.
df = pd.DataFrame()
for i in range(look_back):
df = pd.concat([df, pd.DataFrame(train_X_norm.tolist()[i:-(look_back - i)])], ignore_index=True, axis=1)
print("df: ")
print(df)
df_numpy = np.array(df)
df_tensor = torch.Tensor(df_numpy)
class mytrainset(Dataset):
def __init__(self, df_tensor, train_y):
self.data, self.label = df_tensor[:, :].float(), train_y[:]
def __getitem__(self, index):
return self.data[index], self.label[index]
def __len__(self):
return len(self.data)
trainset = mytrainset(df_tensor, train_y_norm[look_back:]) # train_y
trainloader = DataLoader(trainset, batch_size=10, shuffle=False)
device = torch.device(‘cuda’ if torch.cuda.is_available() else ‘cpu’)
print(device)
class STEFunction(autograd.Function):
@staticmethod
def forward(ctx, inter_state):
# from sensor signal to output driving signals and then to the response by STE
# The following is for the response signal calculation, however, we will replace this part with real sensor signal directly in experiment.
ttemp = torch.squeeze(ctx[:, -1, :]).requires_grad_(True).detach().cpu().numpy()
ttemp = ttemp.transpose()
if inter_state is None:
_, tout, inter_state = control.forced_response(env.AMP_signal_acc, env.mat_step4['t'][0][
1:11], # batch_size=10
ttemp,
return_x=True)
state = inter_state[:, -1]
else:
_, tout, inter_state = control.forced_response(env.AMP_signal_acc, env.mat_step4['t'][0][
1:11], # batch_size=10
ttemp,
inter_state, return_x=True)
state = inter_state[:, -1]
out_u = torch.tensor(tout.transpose(), requires_grad=True).type(torch.FloatTensor)
ctx.save_for_backward(state)
return out_u, state
@staticmethod
def backward(ctx, grad_output):
# out = nn.Linear(6, 32 * 2) # grad_output.size = 6
# return out(grad_output)
state = ctx.saved_tensors
grad_input = grad_output.clone()
return grad_input, grad_input
class StraightThroughEstimator(nn.Module):
updated_state = None
def __init__(self, state):
inter_state = state
super(StraightThroughEstimator, self).__init__() # inter_state :super()
# https://realpython.com/python-super/
def forward(self, x, state):
x, updated_state = STEFunction.apply(x, state) # how to pass the self.state back to RNN class instance
return x, updated_state
class RNN(nn.Module):
def __init__(self, input_size):
super(RNN, self).__init__()
self.state = None
hidden_size = 32 # 64
self.encoder_embedding = nn.Linear(input_size, hidden_size)
self.encoder_rnn = nn.LSTM(
input_size=hidden_size,
hidden_size=hidden_size, # 64
num_layers=1,
batch_first=True,
dropout=0.1,
bidirectional=True,
# return_sequences=True,
)
self.encoder_out = nn.Linear(hidden_size * 2, 6) # output 6 signals to drive actuators
StraightThroughEstimator()
self.decoder_embedding = nn.Linear(6, hidden_size) # from 6 driving signals to LSTM
self.decoder_rnn = nn.LSTM(
input_size=hidden_size,
hidden_size=hidden_size, # 64
num_layers=1,
batch_first=True,
dropout=0.1,
bidirectional=True,
)
self.decoder_out = nn.Linear(2 * hidden_size, input_size)
def forward(self, x, encode=True, decode=False):
if encode:
x = self.encoder_embedding(x)
r_out, (h_n, h_c) = self.encoder_rnn(x, None) # None for initialization by 0 for hidden layers
out = self.encoder_out(r_out)
out_u, self.state = StraightThroughEstimator(out, self.state) #_init__() takes 2 positional arguments but 3 were given
return out_u # 20, 899, 1; 10, 6
elif decode:
# out_u = self.decoder(x) # response to sensor signal backwards, I expand it for debugging.
x = self.decoder_embedding(x)
r_out, (h_n, h_c) = self.decoder_rnn(x, None)
out_u = self.decoder_out(r_out)
else:
# encoding = self.encoder(x)
# out_u = self.decoder(encoding)
x = self.encoder_embedding(x)
t_out, (h_n, h_c) = self.encoder_rnn(x, None)
out = self.encoder_out(t_out)
p_out = self.decoder_embedding(out)
r_out, (h_n, h_c) = self.decoder_rnn(p_out, None)
out_u = self.decoder_out(r_out)
return out_u
n = 1 # Acc_stage_converted 1; target driving signal 6 dimension
rnn = RNN(n).to(device)
optimizer = torch.optim.Adam(rnn.parameters(), lr=0.0002)
loss_func = nn.MSELoss()
EPOCH = 5
print(“Start training …”)
for step in range(EPOCH):
rnn.state = None
for tx, ty in trainloader:
tx = tx.to(device)
ty = ty.to(device)
output = rnn(torch.unsqueeze(tx, dim=2)) # dim=1 # reshape input to be 3D [samples, timesteps, features]
loss = loss_func(output[:, 2].reshape(-1, 1).to(device), ty.reshape(-1, 1))
# clear out the gradients from the last step loss.backward()
optimizer.zero_grad()
# backward propagation: calculate gradients
loss.backward()
# update the weights
optimizer.step()
print("%d / %d, loss = %E" % (step + 1, EPOCH, loss))
out_u, self.state = StraightThroughEstimator(out, self.state) #init_() takes 2 positional arguments but 3 were given
I have to calculate the state variable for vibration response calculation.
How can I implement it.
Bests
I am sorry, I am newbee to edit and upload code, It seems the tab or spaces are missing…
Hi! Sorry for the late reply.
The reason for the error message is that you are actually passing three arguments: self, out and self.state.
Notice however that StraightThroughEstimator is the class constructor - this is not how you use it as a function during training. Below I’ll write a short code snippet to illustrate its use (the forward and backward methods are just used as exampled)
class STEFunction(torch.autograd.Function):
@staticmethod
def forward(ctx, input):
return torch.heaviside(input)
@staticmethod
def backward(ctx, grad_output):
return F.hardtanh(grad_output)
class StraightThroughEstimator(nn.Module):
def init(self):
super(StraightThroughEstimator, self).init()
def forward(self, x):
x = STEFunction.apply(x)
return x
class Class1(nn.Module):
def init(self):
super(Class1, self).init()
self.examplefn = nn.Sequential(
nn.Linear(64,64), # not important
nn.ReLU(inplace=True), # not important
StraightThroughEstimator() # STE-constructor used here
)
def forward(self, x):
return self.examplefn(x) # STE used here during training
class Class2(nn.Module):
def init(self):
super(Class2, self).init()
self.examplefn = nn.Sequential(
nn.Linear(64,64), # not important
nn.ReLU(inplace=True) # not important
)
self.ste = StraightThroughEstimator() # STE-constructor used here
def forward(self, inputs):
x1 = self.examplefn(inputs)
x2 = self.ste(x1) # STE used here
return x2
Hopefully this will shed some light on how STE:s are implemented and used.
Best regards
Hi Mathias and @albanD:
Thank you for the fast reply and very clear explanation. I fix this bug as following:
class STEFunction(autograd.Function):
@staticmethod
def forward(ctx, input_x, inter_state):
ttemp = torch.squeeze(input_x[:, -1, :]).requires_grad_(True).detach().cpu().numpy()
ttemp = ttemp.transpose()
if inter_state is None:
_, tout, inter_state = control.forced_response(env.AMP_signal_acc, env.mat_step4['t'][0][
1:11], # batch_size=10
ttemp,
return_x=True)
updated_state = inter_state[:, -1]
else:
inter_state = inter_state.requires_grad_(True).detach().cpu().numpy()
_, tout, inter_state = control.forced_response(env.AMP_signal_acc, env.mat_step4['t'][0][
1:11], # batch_size=10
ttemp,
inter_state, return_x=True)
updated_state = inter_state[:, -1]
out_u = Variable(torch.tensor(tout.transpose()), requires_grad=True).type(torch.FloatTensor).cuda()
updated_state = Variable(torch.tensor(updated_state), requires_grad=True).type(torch.FloatTensor).cuda()
back_out_u = torch.zeros(10, 1350, 6).cuda()
for i in range(1350):
back_out_u[:, i, :] = out_u
return back_out_u, updated_state # return out_u
@staticmethod
def backward(ctx, grad_output, grad_output1):
return F.hardtanh(grad_output), None
class StraightThroughEstimator(nn.Module):
def __init__(self, inter_state, x): # inter_state, x
self.state = inter_state
super(StraightThroughEstimator, self).__init__()
def forward(self, inter_state, x):
x, updated_state = STEFunction.apply(x, inter_state)
return x, updated_state
However, I find another error as introduced below.
It tells that the intermedia buffers have been freed when comes to the second time backward calling.
In my code, the control.forced_response applied in the STEFunction class definition, is used to simulate the reponse with respect to driving signals. It needs numpy datatype and the inter_state of last step. The problem could be the
ttemp = torch.squeeze(input_x[:, -1, :]).requires_grad_(True).detach().cpu().numpy()
and
the inter_state. I save it in the Rnn class as a class member variable.
In order to find the problem I upload the following snippets for reference.
class RNN(nn.Module):
def __init__(self, input_size):
super(RNN, self).__init__()
self.state = None
self.out = None
hidden_size = 32 # 64
self.encoder_embedding = nn.Linear(input_size, hidden_size)
self.encoder_rnn = nn.LSTM(
input_size=hidden_size,
hidden_size=hidden_size,
num_layers=1,
batch_first=True,
dropout=0.1,
bidirectional=True,
)
self.encoder_out = nn.Linear(2*hidden_size, 6) # output 6 signals to drive actuators
self.ste = StraightThroughEstimator(self.state, self.out) # As suggested, thank you
self.decoder_embedding = nn.Linear(6, hidden_size) # from 6 driving signals to LSTM
self.decoder_rnn = nn.LSTM(
input_size=hidden_size,
hidden_size=hidden_size, # 64
num_layers=1,
batch_first=True,
dropout=0.1,
bidirectional=True,
)
self.decoder_out = nn.Linear(2 * hidden_size, input_size)
def forward(self, x, encode=True, decode=False):
if encode:
x = self.encoder_embedding(x)
r_out, (h_n, h_c) = self.encoder_rnn(x, None) # None for initialization by 0 for hidden layers
out = self.encoder_out(r_out)
**out_u_1, self.state = self.ste(self.state, out)**
out_u = out_u_1[:, -1, :]
return out_u # 20, 899, 1; 10, 6
elif decode:
# out_u = self.decoder(x) # response to sensor signal backwards
x = self.decoder_embedding(x)
r_out, (h_n, h_c) = self.decoder_rnn(x, None)
out_u = self.decoder_out(r_out)
else:
# encoding = self.encoder(x)
# out_u = self.decoder(encoding)
x = self.encoder_embedding(x)
t_out, (h_n, h_c) = self.encoder_rnn(x, None)
out = self.encoder_out(t_out)
p_out = self.decoder_embedding(out)
r_out, (h_n, h_c) = self.decoder_rnn(p_out, None)
out_u = self.decoder_out(r_out)
return out_u
n = 1 # Only 1 channel of signal for training
rnn = RNN(n).to(device)
optimizer = torch.optim.Adam(rnn.parameters(), lr=0.0002)
loss_func = nn.MSELoss()
EPOCH = 5
print(“Start training …”)
for step in range(EPOCH):
rnn.state = None
for tx, ty in trainloader:
tx = tx.to(device)
ty = ty.to(device)
output = rnn(torch.unsqueeze(tx, dim=2)) # reshape input to be 3D [samples, timesteps, features]
loss = loss_func(output[:, 2].reshape(-1, 1).to(device), ty.reshape(-1, 1))
# clear out the gradients from the last step loss.backward()
optimizer.zero_grad()
# backward propagation: calculate gradients. Success in the first train, fail for the second.
loss.backward()
# update the weights
optimizer.step()
print(“%d / %d, loss = %E” % (step + 1, EPOCH, loss))
I delete all state variables, and it can train successfully. However, It is necessary to pass this variable for response simulation.
For real experiments, this response simulation will be replaced by sensor signals. It is supposed to jump out this problem.
Best regards and Merry Christmas
Chen