You could use a similar approach as described in this post.
As you already explained, the following layer should be changes as well, if you change the number of output channels in the preceding layer.
1 Like
Hi!
I tried to “cut” a Resnet18 into multiple parts, because I need to use the result of a hidden layer as input to another function.
The solution from @ptrblck worked perfectly(Thanks!), but there is a “size mismatch” between the two networks.
Creating the first part: [0:6]
#Loading Resnet18 - loading weights, disposing of the end of the network
baseModel=torchvision.models.resnet18(pretrained=False)
baseModel.fc = torch.nn.Linear(512, 2)
baseModel.load_state_dict(torch.load('model.pth'),strict=True)
baseModel = torch.nn.Sequential(*(list(baseModel.children())[0:6]))
The same for the end of the network (6-end): [6:]
#Loading Resnet18 - loading weights, disposing of the beginning of the network
endModel=torchvision.models.resnet18(pretrained=False)
endModel.fc = torch.nn.Linear(512, 2)
endModel.load_state_dict(torch.load('model.pth'),strict=True)
endModel = torch.nn.Sequential(*(list(endModel.children())[6:]))
Moving to GPU:
device = torch.device('cuda')
baseModel = baseModel.to(device)
baseModel = baseModel.eval().half()
endModel = endModel.to(device)
endModel = endModel.eval().half()
Running an image through the first part:
baseResNet=baseModel(preprocess(image))
print(baseResNet.shape)
Result: torch.Size([1, 128, 28, 28])
The last layer of the first part of the newwork is:
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
But if I try to run this through the second part:
output=endModel(baseResNet)
This results in an error:
RuntimeError: size mismatch, m1: [512 x 1], m2: [512 x 2] at C:/w/1/s/tmp_conda_3.7_075911/conda/conda-bld/pytorch_1579075223148/work/aten/src\THC/generic/THCTensorMathBlas.cu:290
What I do not understand, is how can there be a size mismatch, if the two layers have been connected before. I have tried to to do this in different ways, but I got stuck.
Unfortunately I have been using PyTorch and Python only for a short time,
so it is entirely possible possible that I am messing up something basic.
Any help or pointers appreciated… Thanks in advance!
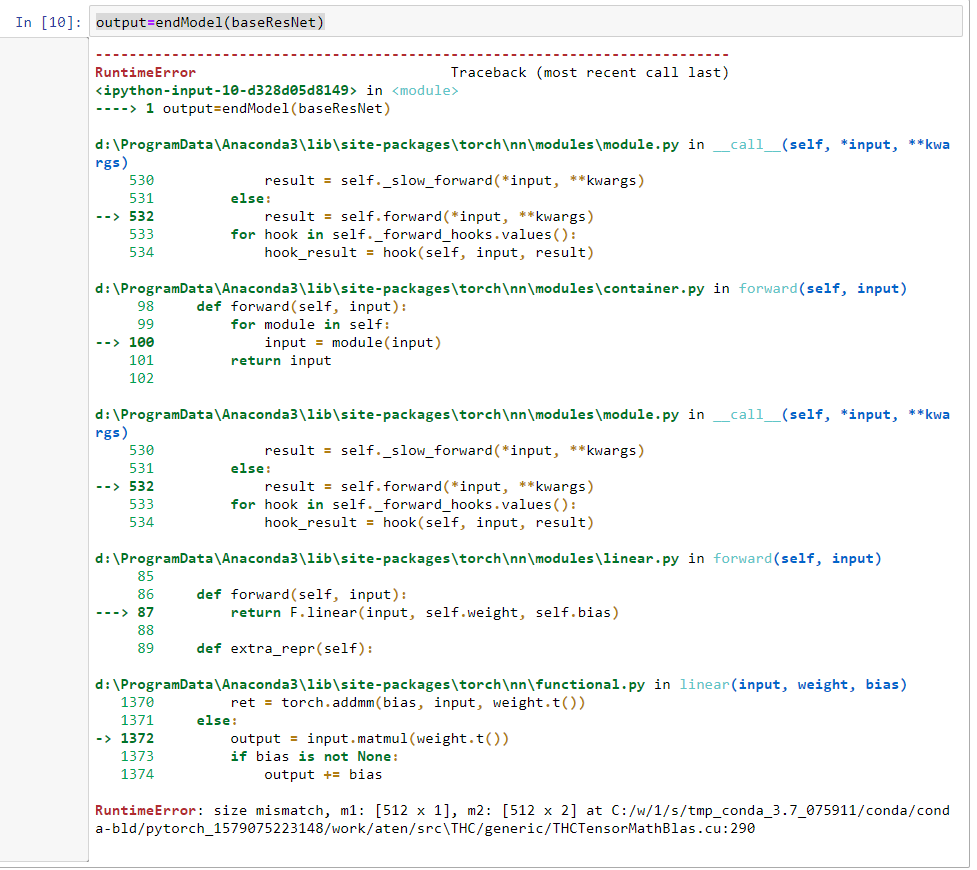
If you are wrapping the submodules in nn.Sequential containers, note that you will lose the functional API calls in the forward, e.g. this flatten operation, which might create this error.
You could add an nn.Flatten() layer to your nn.Sequential containers or modify the forward instead.
2 Likes
It worked perfectly!
I have only checked the network with a simple print(model), and it seems, that I cannot find this with that command. I will do some more reading on this…
Thank you for your help!
Why do i get different output shapes when i use model.fc = Identity() and model = nn.Sequential(*list(preNet.children())[:-1]) for Inception V3?
For model.fc = Identity() , the output dimension is [2048] while for model = nn.Sequential(*list(preNet.children())[:-1]) , the output dimension is [2048,35,35].
How can I output the last convolution layer output of Inception V3 with the shape [2048,5,5] before the pooling layer averages it to [2048,1,1]?
InceptionV3 uses functional calls in its forward, which will be missing, if you wrap all submodules in an nn.Sequential container.
In particular this flatten operation will be missing.
You could use forward hooks as described here.
2 Likes
Thanks. From the flatten operation link you shared, I will like to get Mixed_7c output N x 2048 x 8 x 8 just before the Adaptive average pooling. Please can you help? I tried the forward hook as follows but i dont understand how it works and my output is N x 1000 instead of N x 2048 x 8 x 8:
activation = {}
def get_activation(name):
def hook(model, input, output):
activation[name] = output.detach()
return hook
preNet = models.inception_v3(pretrained=True, aux_logits = False)
preNet.fc.register_forward_hook(get_activation(‘fc’))
#images is of size (3,299,299)
a = preNet(images)
print(a.shape) #outputs (1000), however, I am interested in the mixed_7c output of (2048,8,8)
In that case you should register the hook to the .Mixed_7b instead of the .fc layer:
activation = {}
def get_activation(name):
def hook(model, input, output):
activation[name] = output.detach()
return hook
model = models.inception_v3()
model.Mixed_7b.register_forward_hook(get_activation('Mixed_7b'))
out = model(torch.randn(2, 3, 299, 299))
print(activation['Mixed_7b'].shape)
> torch.Size([2, 2048, 8, 8])
2 Likes
Wow. Thanks so much. It works. So the variable activation[‘Mixed_7b’] holds the output torch and not the variable ‘out’? This means i will use activation[‘Mixed_7b’] in following analysis and not ‘out’?
out is the return value from the model’s forward method, while activation['Mixed_7b'] contains the output of the model.Mixed_7b layer, so you should use it for your analysis.
2 Likes
I am curious about the outputs of Mixed_7b layer i.e. the feature maps. Is there a sequential order in the output feature maps or the maps are totally random?
The activation is given as [batch_size, out_channels, height, width], where out_channels are the number of filters from the last conv layer.
1 Like
should we also remove the weights of those removed layers? if yes, how should it be done? thank you.
Layers are implemented as nn.Modules, which hold parameters and buffers, if applicable, and define a forward method.
If you remove a layer which contained weights, the weights will also be removed and not used anymore.
1 Like
Hi @ptrblck, I saw a seemingly quick method to delete some layers. Just simply use del resnet_model.fc as done in this project. Is there any side effect of using such a method? Thanks for your comments in advance.
Yes, I would not recommend to delete the modules directly, as this would break the model as seen here:
model = models.resnet18()
del model.fc
out = model(torch.randn(1, 3, 224, 224))
> ModuleAttributeError: 'ResNet' object has no attribute 'fc'
While the .fc module was removed, it’s still used in the forward method, which will raise this error.
In the linked example, the submodules of the resnet are called manually in a sequential manner, so you would have to be careful, as you won’t be able to call the model directly anymore.
3 Likes
Hi. I am struggling to remove the softmax of pretrained resnet18. I am trying to send the CNN output to a transformer encoder-decoder network. The encoder-decoder network expects an input tensor of size [2000]. A similar thread is here.
import torchvision.models as models
class ResnetEncoder(nn.Module):
def __init__(self):
super(ResnetEncoder, self).__init__()
resnet = models.resnet18(pretrained=True)
modules = list(resnet.children())[::-1]
self.resnet = nn.Sequential(*modules)
def forward(self, images):
out = self.resnet(images) # dimension: (batchsize * n frame, 3, 227, 227)
out = out.view(-1, 2000)
return out
model = ResnetEncoder()
input_frames = torch.randn(100, 3, 224, 224)
output = model(x)
RuntimeError: size mismatch, m1: [168000 x 224], m2: [512 x 1000] at /pytorch/aten/src/TH/generic/THTensorMath.cpp:41
There is a size mismatch because the first layer of resnet expects an input of size Z x 512.
ResnetEncoder(
(resnet): Sequential(
(0): Linear(in_features=512, out_features=1000, bias=True)
(1): AdaptiveAvgPool2d(output_size=(1, 1))
1 Like
Update:
It was a stupid mistake in modules = list(resnet.children())[::-1] 
The right syntax is modules = list(resnet.children())[:-1]
I was wondering why the output for these two code is different?
1)
resnet50 = models.resnet50(pretrained=True)
resnet50.fc = Identity()
resnet50.avgpool = Identity()
output = resnet50(torch.randn(1, 3, 224, 224))
print(output.shape)
output:
torch.Size([1, 100352])
and the model resent50 looks like:
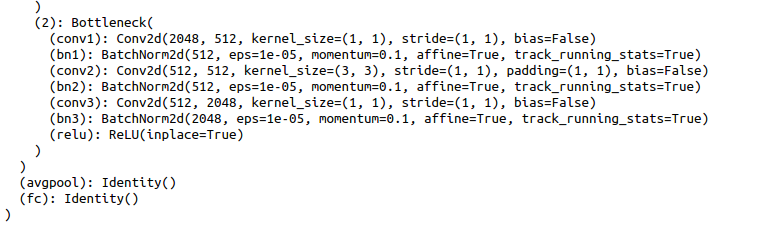
resnet50_2 = models.resnet50(pretrained=True)
model = nn.Sequential(*list(resnet50_2.children())[:-2])
print(model(torch.randn(1, 3, 224, 224)).shape)
output:
torch.Size([1, 2048, 7, 7])
and the model looks like:

The first approach would still use the original forward method with the replaced avgpool and fc layers, so this flatten operation would still be applied, while the latter approach would call the modules sequentially and would thus drop the functional flatten call from the forward method.
As you can see, 2048*7*7=100352.
2 Likes