hi everyone,
I just learned about CNN and I want to create a custom architecture to classify 2 classes of rice leaf disease (leaf blight and leaf spot), with a relatively small total data, namely 1080 data on rice leaf in a photo on a white background. training has been carried out several times but the accuracy is not convergent.
what should I do to achieve good results.
def DepthConvBlock(in_channels, out_channels, stride=1):
return nn.Sequential(
nn.Conv2d(in_channels, in_channels, kernel_size=3, stride=stride, padding=1, groups=in_channels),
nn.BatchNorm2d(in_channels),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
class CNNpenyakitPadi(nn.Module):
def __init__(self, output_size):
super().__init__()
self.feature = nn.Sequential(
DepthConvBlock(3, 16, stride=1),
nn.MaxPool2d(2, 2),
DepthConvBlock(16, 32, stride=1),
nn.MaxPool2d(2, 2),
DepthConvBlock(32, 64, stride=1),
nn.MaxPool2d(2, 2),
DepthConvBlock(64, 128, stride=1),
nn.MaxPool2d(2, 2),
DepthConvBlock(128, 256, stride=1),
nn.MaxPool2d(2, 2),
DepthConvBlock(256, 512, stride=1),
nn.AdaptiveMaxPool2d(1)
)
self.classifier = nn.Sequential(
nn.Linear(512, output_size),
nn.Dropout(0.5)
)
def forward(self, x):
x = self.feature(x)
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x
some of the settings used
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = CNNpenyakitPadi(output_size = len(train_set.classes)).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.AdamW(model.parameters(), lr=0.0015, weight_decay=0.005, amsgrad=False)
callback = Callback(model, early_stop_patience=10, outdir="modelC6")
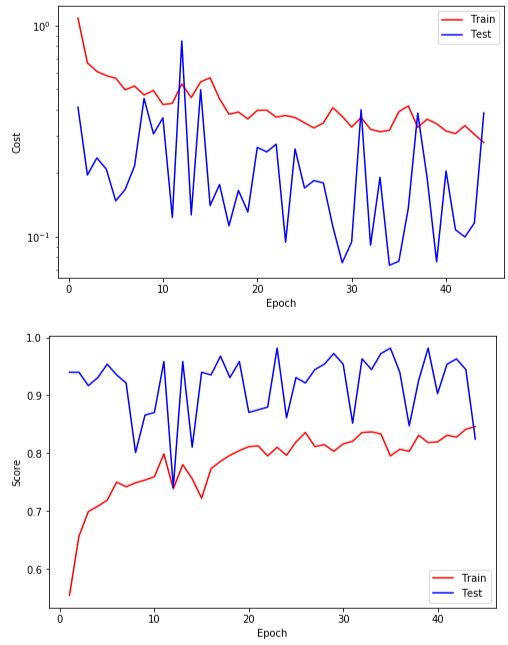
This is the result of training in several epochs
Epoch 1
Train_cost = 1.0851 | Test_cost = 0.4106 | Train_score = 0.5544 | Test_score = 0.9398 |
Epoch 2
Train_cost = 0.6667 | Test_cost = 0.1962 | Train_score = 0.6562 | Test_score = 0.9398 |
Epoch 3
Train_cost = 0.6072 | Test_cost = 0.2363 | Train_score = 0.6991 | Test_score = 0.9167 |
==> EarlyStop patience = 1 | Best test_cost: 0.1962
Epoch 4
Train_cost = 0.5799 | Test_cost = 0.2092 | Train_score = 0.7083 | Test_score = 0.9306 |
==> EarlyStop patience = 2 | Best test_cost: 0.1962
Epoch 5
Train_cost = 0.5638 | Test_cost = 0.1479 | Train_score = 0.7188 | Test_score = 0.9537 |
Epoch 6
Train_cost = 0.4966 | Test_cost = 0.1675 | Train_score = 0.7500 | Test_score = 0.9352 |
==> EarlyStop patience = 1 | Best test_cost: 0.1479
Epoch 7
Train_cost = 0.5178 | Test_cost = 0.2169 | Train_score = 0.7419 | Test_score = 0.9213 |
==> EarlyStop patience = 2 | Best test_cost: 0.1479
Epoch 8
Train_cost = 0.4695 | Test_cost = 0.4520 | Train_score = 0.7488 | Test_score = 0.8009 |
==> EarlyStop patience = 3 | Best test_cost: 0.1479
Epoch 9
Train_cost = 0.4929 | Test_cost = 0.3073 | Train_score = 0.7535 | Test_score = 0.8657 |
==> EarlyStop patience = 4 | Best test_cost: 0.1479
Epoch 10
Train_cost = 0.4230 | Test_cost = 0.3656 | Train_score = 0.7593 | Test_score = 0.8704 |
==> EarlyStop patience = 5 | Best test_cost: 0.1479
Epoch 11
Train_cost = 0.4288 | Test_cost = 0.1234 | Train_score = 0.7986 | Test_score = 0.9583 |
Epoch 12
Train_cost = 0.5295 | Test_cost = 0.8451 | Train_score = 0.7384 | Test_score = 0.7407 |
==> EarlyStop patience = 1 | Best test_cost: 0.1234
Epoch 13
Train_cost = 0.4564 | Test_cost = 0.1270 | Train_score = 0.7801 | Test_score = 0.9583 |
==> EarlyStop patience = 2 | Best test_cost: 0.1234
Epoch 14
Train_cost = 0.5418 | Test_cost = 0.4970 | Train_score = 0.7558 | Test_score = 0.8102 |
==> EarlyStop patience = 3 | Best test_cost: 0.1234
Epoch 15
Train_cost = 0.5663 | Test_cost = 0.1406 | Train_score = 0.7222 | Test_score = 0.9398 |
==> EarlyStop patience = 4 | Best test_cost: 0.1234
Epoch 16
Train_cost = 0.4501 | Test_cost = 0.1768 | Train_score = 0.7731 | Test_score = 0.9352 |
==> EarlyStop patience = 5 | Best test_cost: 0.1234
Epoch 17
Train_cost = 0.3807 | Test_cost = 0.1128 | Train_score = 0.7859 | Test_score = 0.9676 |
Epoch 18
Train_cost = 0.3899 | Test_cost = 0.1658 | Train_score = 0.7963 | Test_score = 0.9306 |
==> EarlyStop patience = 1 | Best test_cost: 0.1128
Epoch 19
Train_cost = 0.3616 | Test_cost = 0.1310 | Train_score = 0.8044 | Test_score = 0.9583 |
==> EarlyStop patience = 2 | Best test_cost: 0.1128
Epoch 20
Train_cost = 0.3970 | Test_cost = 0.2650 | Train_score = 0.8113 | Test_score = 0.8704 |
==> EarlyStop patience = 3 | Best test_cost: 0.1128
Epoch 21
Train_cost = 0.3979 | Test_cost = 0.2523 | Train_score = 0.8125 | Test_score = 0.8750 |
==> EarlyStop patience = 4 | Best test_cost: 0.1128
Epoch 22
Train_cost = 0.3689 | Test_cost = 0.2745 | Train_score = 0.7951 | Test_score = 0.8796 |
==> EarlyStop patience = 5 | Best test_cost: 0.1128
Epoch 23
Train_cost = 0.3753 | Test_cost = 0.0942 | Train_score = 0.8102 | Test_score = 0.9815 |
Epoch 24
Train_cost = 0.3673 | Test_cost = 0.2607 | Train_score = 0.7963 | Test_score = 0.8611 |
==> EarlyStop patience = 1 | Best test_cost: 0.0942
Epoch 25
Train_cost = 0.3467 | Test_cost = 0.1702 | Train_score = 0.8194 | Test_score = 0.9306 |
==> EarlyStop patience = 2 | Best test_cost: 0.0942
Epoch 26
Train_cost = 0.3278 | Test_cost = 0.1846 | Train_score = 0.8356 | Test_score = 0.9213 |
==> EarlyStop patience = 3 | Best test_cost: 0.0942
Epoch 27
Train_cost = 0.3460 | Test_cost = 0.1800 | Train_score = 0.8113 | Test_score = 0.9444 |
==> EarlyStop patience = 4 | Best test_cost: 0.0942
Epoch 28
Train_cost = 0.4086 | Test_cost = 0.1121 | Train_score = 0.8148 | Test_score = 0.9537 |
==> EarlyStop patience = 5 | Best test_cost: 0.0942
Epoch 29
Train_cost = 0.3718 | Test_cost = 0.0754 | Train_score = 0.8032 | Test_score = 0.9722 |
Epoch 30
Train_cost = 0.3311 | Test_cost = 0.0946 | Train_score = 0.8160 | Test_score = 0.9537 |
==> EarlyStop patience = 1 | Best test_cost: 0.0754
Epoch 31
Train_cost = 0.3670 | Test_cost = 0.3998 | Train_score = 0.8206 | Test_score = 0.8519 |
==> EarlyStop patience = 2 | Best test_cost: 0.0754
Epoch 32
Train_cost = 0.3229 | Test_cost = 0.0913 | Train_score = 0.8356 | Test_score = 0.9630 |
==> EarlyStop patience = 3 | Best test_cost: 0.0754
Epoch 33
Train_cost = 0.3145 | Test_cost = 0.1913 | Train_score = 0.8368 | Test_score = 0.9444 |
==> EarlyStop patience = 4 | Best test_cost: 0.0754
Epoch 34
Train_cost = 0.3195 | Test_cost = 0.0733 | Train_score = 0.8333 | Test_score = 0.9722 |
Epoch 35
Train_cost = 0.3911 | Test_cost = 0.0766 | Train_score = 0.7951 | Test_score = 0.9815 |
==> EarlyStop patience = 1 | Best test_cost: 0.0733
Epoch 36
Train_cost = 0.4168 | Test_cost = 0.1364 | Train_score = 0.8067 | Test_score = 0.9398 |
==> EarlyStop patience = 2 | Best test_cost: 0.0733
Epoch 37
Train_cost = 0.3302 | Test_cost = 0.3855 | Train_score = 0.8032 | Test_score = 0.8472 |
==> EarlyStop patience = 3 | Best test_cost: 0.0733
Epoch 38
Train_cost = 0.3606 | Test_cost = 0.1893 | Train_score = 0.8310 | Test_score = 0.9259 |
==> EarlyStop patience = 4 | Best test_cost: 0.0733
Epoch 39
Train_cost = 0.3430 | Test_cost = 0.0762 | Train_score = 0.8183 | Test_score = 0.9815 |
==> EarlyStop patience = 5 | Best test_cost: 0.0733
Epoch 40
Train_cost = 0.3170 | Test_cost = 0.2049 | Train_score = 0.8194 | Test_score = 0.9028 |
==> EarlyStop patience = 6 | Best test_cost: 0.0733
Epoch 41
Train_cost = 0.3081 | Test_cost = 0.1080 | Train_score = 0.8310 | Test_score = 0.9537 |
==> EarlyStop patience = 7 | Best test_cost: 0.0733
Epoch 42
Train_cost = 0.3362 | Test_cost = 0.0998 | Train_score = 0.8275 | Test_score = 0.9630 |
==> EarlyStop patience = 8 | Best test_cost: 0.0733
Epoch 43
Train_cost = 0.3055 | Test_cost = 0.1161 | Train_score = 0.8414 | Test_score = 0.9444 |
==> EarlyStop patience = 9 | Best test_cost: 0.0733
Epoch 44
Train_cost = 0.2796 | Test_cost = 0.3860 | Train_score = 0.8461 | Test_score = 0.8241
thank you,
sorry for my bad english