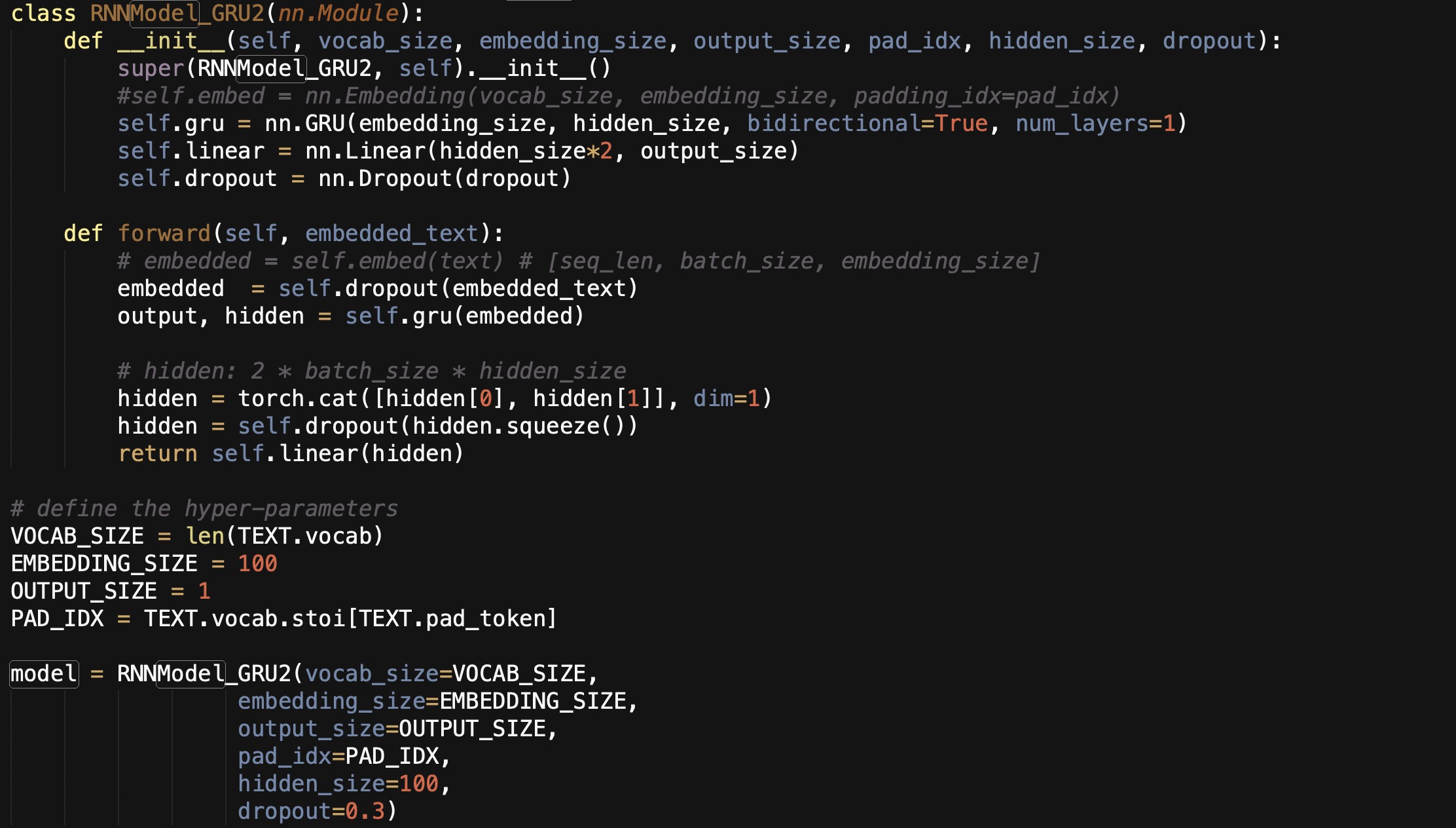
However, when I run “model.eval()”, the error occur: RuntimeError: cudnn RNN backward can only be called in training mode.
I’m really confused why CNN can go through saliency easily but RNN goes very difficult? Is there any solution to generate saliency map for text classification (to show which word is most important for model prediction) by RNN model? Thanks a lot!
Thanks shekhar! I read the problem you pasted here but it seems not same with my question. I want to figure out how to use backward() when doing saliency from RNN model.
The complete code is here, and the Saliency part start form line 262.
Well, just to see if it work, stay in the training mode with model.train() so you can perform backward(). Just avoid doing the optimizer step to actually change the trainable parameters. I can see no harm here.
Apart from that, I’ve tried to visualize the importance of words when using an RNN using attention, where the attention weights indicate which word had the most affect on the prediction. It’s not unintuitive but has been shown to have problems.
Thanks for your advices! It works! by perform backward() in model.train(), and go through forward path without updating weights of parameters, the saliency looks right.
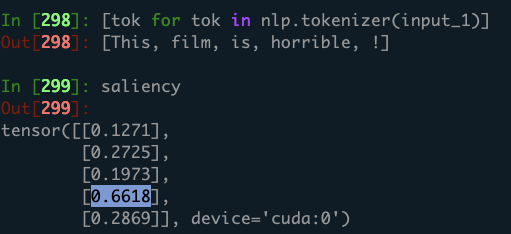
when I input “This film is horrible!” the saliency can tell the word “horrible” is most important for prediction the emotion of this review.
The following is the updated code:
# tring Saliency now!
# for pre-processing the sentence (sentence to vectors)
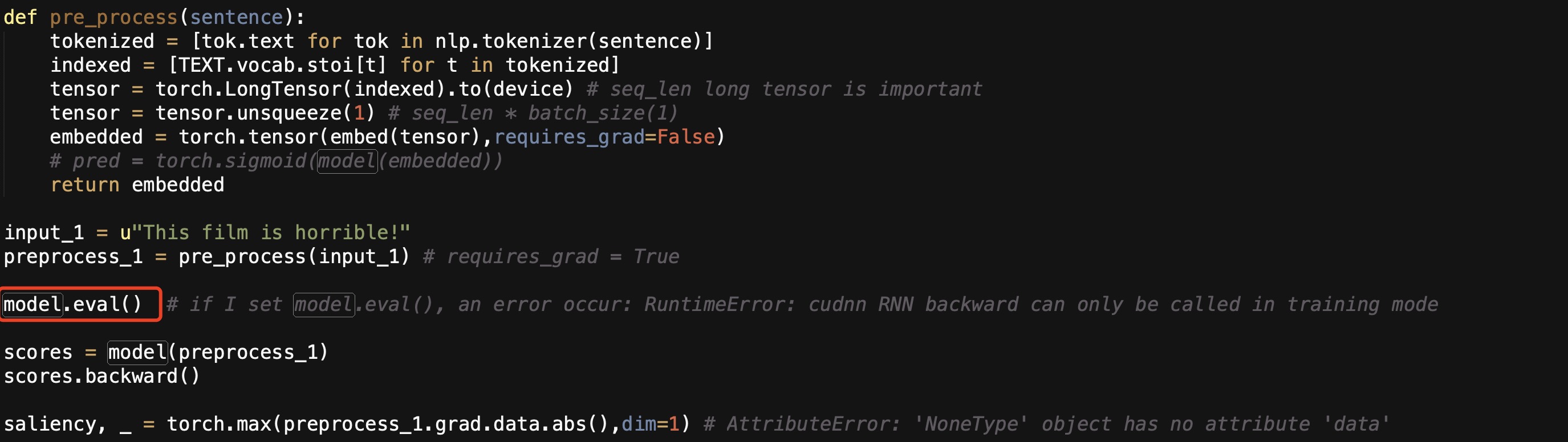
def pre_process(sentence):
tokenized = [tok.text for tok in nlp.tokenizer(sentence)]
indexed = [TEXT.vocab.stoi[t] for t in tokenized]
tensor = torch.LongTensor(indexed).to(device) # seq_len long tensor is important
tensor = tensor.unsqueeze(1) # seq_len * batch_size(1)
embedded = torch.tensor(embed(tensor),requires_grad=True)
# here we need to get gradient for saliency computation, use requires_grad=True
return embedded
# deal with input sentence
input_1 = u"This film is horrible!"
input_1 = u"This movie was sadly under-promoted but proved to be truly exceptional."
preprocess_1 = pre_process(input_1) # requires_grad = True
# we would run the model in evaluation mode
model.train()
# if I set model.eval(), an error occur: RuntimeError: cudnn RNN backward can only be called in training mode
'''forward pass through the model to get the scores, note that RNNModel_GRU2 model doesn't perform sigmoid at the end
and we also don't need sigmoid, we need scores, so that's perfect for us.
'''
scores = model(preprocess_1)
'''
backward function on score_max performs the backward pass in the computation graph and calculates the gradient of
score_max with respect to nodes in the computation graph
'''
scores.backward()
'''
Saliency would be the gradient with respect to the input now.
But note that the input has 100 dim embdeddings.
To derive a single class saliency value for each word (i, j),
we take the maximum magnitude across all embedding dimensions.
'''
saliency, _ = torch.max(preprocess_1.grad.data.abs(),dim=2) # AttributeError: 'NoneType' object has no attribute 'data'
There’s still a small problem when I avoided to do optimizer step after calling backward() in training mode. the problem is: for the same input sentence and the same model, the saliencies are different between the first time and second time I called. If the parameters are totally fixed, the results of saliency should be consistent. I guess that because my model contains a dropout layer and the randomness is generated in model.train() from drop out layer. Any ideas about how to deactivate drop out layer in model.train() mode?
Saliency for the first time calling backward():
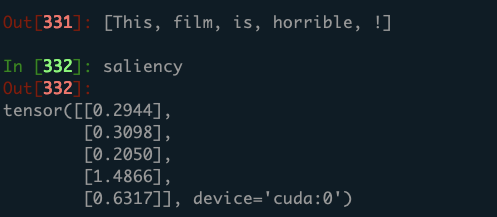
Saliency for the second time calling backward():
The Saliency for each word is getting bigger.
Well actually I figured out how to do this, just set the drop out layer to eval by adding model.dropout.eval(), now the Saliency become consistent.
Yes, the Dropout layer was still a non-deterministic part of your network. This is one of the main reasons for eval(). I’ve never tried it, but I assume setting the dropout probability to 0.0 would have worked as well. Not sure, thought.