I will explain the entire issue.
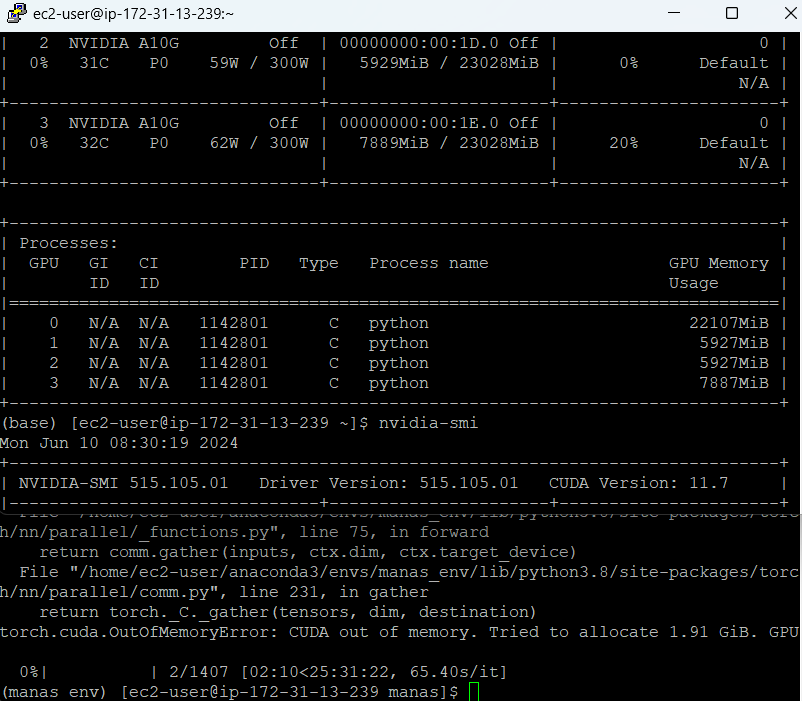
I am using a 4 gpu machine each of 20gb for finetuning mistral.
When I train a model, the gpu distributes some memory over all the gpus but fully utilises gpu 1. As soon as the memory is exhausted it throws an error Cuda OutofMemory instead of switching to the next gpu
I tried to use DistributedDataParallel but now I am facing this IndexError mentioned above:
torch.distributed.init_process_group(backend="nccl")
Set device based on local rank
local_rank = int(os.environ["LOCAL_RANK"])#
torch.cuda.set_device(local_rank)
device = torch.device("cuda", local_rank)
.
.
model = nn.parallel.DistributedDataParallel(model, device_ids=[local_rank], output_device=local_rank, find_unused_parameters=True)
Command to run torchrun --nproc_per_node=4 --nnodes=1 --node_rank=0 mistral-opt.py
There are no missing values in my dataset. I am not sure what is happening.Need some help
An IndexError occurred: Invalid key: 41784 is out of bounds for size 0
Skipping this error and continuing execution.
An IndexError occurred: Invalid key: 26752 is out of bounds for size 0
Skipping this error and continuing execution.
An IndexError occurred: Invalid key: 35187 is out of bounds for size 0
Skipping this error and continuing execution.
An IndexError occurred: Invalid key: 38692 is out of bounds for size 0
Skipping this error and continuing execution.
I don’t understand why the script should switch to the next GPU somehow. Did you debug why the imbalanced memory usage is seen in the first place?
Narrow down which line of code raises the warning and then check all corresponding inputs of the operation.
So, the machine has 4 gpus each of 20gb memory, The OutofMemory error occurs when Gpu 1 runs of out of memory, but as you can see the other gpus are still having a lot of unused memory, I wanted to know as to why it is not utilising the remaining memory instead to allocate space.
Also, I am new to this so can you tell how I can debug the imbalanced memory usage.
The error occurs in : trainer.train() , I am trying to finetune Mistral on a dataset
PyTorch does not automatically allocate memory on different devices and since each memory allocation is explicit, you would need to narrow down why the memory usage is higher on GPU0.
You could start by adding debug print statements narrowing down where the memory increases unexpectedly via print(torch.cuda.memory_allocated()) (or similar calls).
https://discuss.pytorch.org/t/uneven-gpu-utilization-during-training-backpropagation/36117
I found a thread related to the issue I am facing, I will try to see if I can change the output devices for gradient accumulation and forward/backward passes.
Thanks!
The linked issue uses nn.DataParallel which is known to create an imbalanced usage since the default GPU device will be used to gather all inputs and outputs. In your title you are mentioning DistributedDataParallel, which does not suffer from this issue since each device uses its own process for the model training including data loading and processing.
Yes I figured out this error was occuring in the tokenization step.Thanks alot!