I used pytorch’s DataParallel module in order to parallelize training of a large model. I noticed the utilization of my primary GPU (coda:0) would be far larger than my other GPUs. I checked previous topics and implemented recommended changes such as calculating loss in the forward pass. However this problem persists. I profiled my GPU usage and noticed it is evenly distributed until calling backward() on my loss. Memory usage on the primary GPU then increases for several iterations until plateauing around the 10-20th iteration. My training loop logic is pretty basic besides taking advantage of gradient accumulation so I am at a how to fix my problem.
# model is a DataParallel module
for i, batch in enumerate(dataloader):
if i % freq == 0:
optimizer.zero_grad()
loss = model(**batch) # even GPU utilization
loss = loss.sum()
loss.backward() # increase in primary GPU utilization
if (i+1) % freq == 0:
optimizer.step()
Upon further profiling, it seems almost all the remaining space on primary GPU is being consumed by gradient accumulation. When calling step() on the optimizer, the remaining space is used resulting in an out of memory error. Is this intended behavior to store gradients and optimizers on GPU 0? If so this seems highly inconvenient…
This is normal and expected as you load the data onto the primary GPU in DataParallel and also the gradient accumulation happens on the primary GPU as you mentioned.
Then is there a way to store accumulated gradients and/or the optimizer on a separate GPU or perform the forward pass without using the primary GPU? As it stands, 3/4 of my GPUs are not even half utilized.
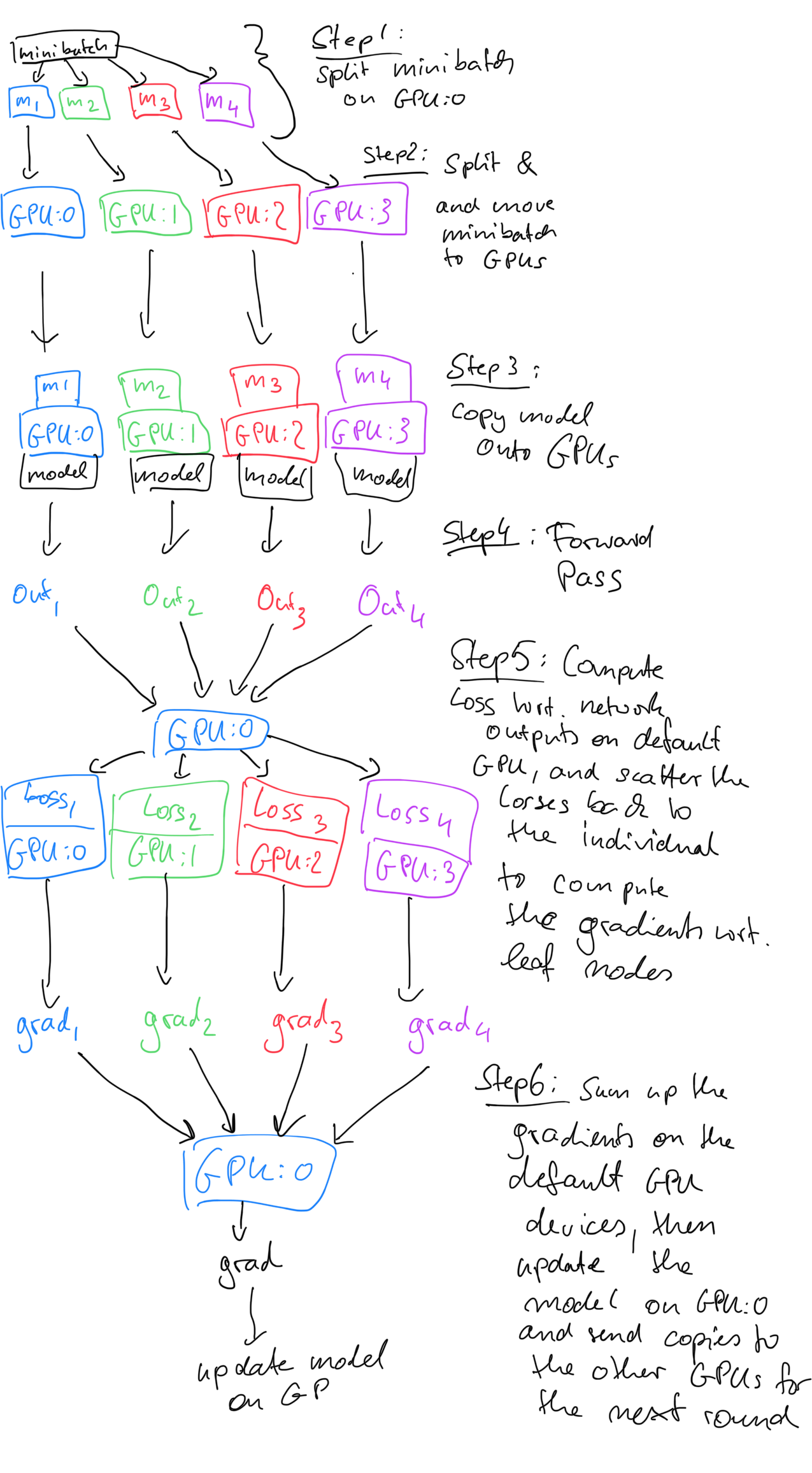
What you can do is to designate a different GPU to do this. However, if the accumulated gradients fit on one GPU, it’s not worth thinking about hacks to do that on separate GPUs imho, because doing it on one device should be the fasted way to do it. Actually, I think they are accumulated to calculate the loss, and the gradients, I’ve sketched it out once …
The reason why it is computed on the default GPU is that you typically have something like this:
start_time = time.time()
for epoch in range(num_epochs):
model.train()
for batch_idx, (features, targets) in enumerate(train_loader):
features = features.to(device)
targets = targets.to(device)
### FORWARD AND BACK PROP
logits, probas = model(features)
cost = F.cross_entropy(logits, targets)
optimizer.zero_grad()
cost.backward()
### UPDATE MODEL PARAMETERS
optimizer.step()
Note that targets (e.g., the class labels) is on the default GPU. Hence, if you want to do what you suggest you’d need to rewrite the code to split the class labels over the GPUs as well and then compute the loss on these separately and then combine the loss to compute the gradients. It’s not worth the hassle, imho, if the targets fit on the default GPU. Splitting it as well will only make it slower as the loss computation is super fast anyways.
Oh sorry, let me clarify. My problem is that I cannot fit a single mini-batch, gradients, and optimizer on a single GPU (in this case the primary GPU). I originally thought, wrongly, the extra memory usage on the primary GPU was some sort of bug.
I now want to try to get around this by having a separate GPU dedicated to storing the gradients and optimizer which is not used in the forward or backward pass. So if I have 5 GPUs, I would use 1-4 to calculate the loss and gradients, then send the resulting gradients to the 5th GPU in order to update the parameters.
Generally though, I would recommend scaling the batchsize by 1/num_cuda_devices if you use dataparallel and want results that are somewhat comparable to the 1-GPU version.
I am able to compute the loss and gradients on the GPU. I am simply unable to store the resultant gradients in a single GPU while also using the same GPU to compute future losses and gradients. So I simply want to gather and store the gradients elsewhere, like another GPU or CPU memory.
I tried computing loss on CPU, however the gradients still end up on the primary GPU.
Hm, that’s tricky then.
What you could try is to set output_device=torch.device('cpu') in DataParallel, but I am not sure if this will work and how fast this will be. I’d probably rather go with a smaller batch size instead of doing that.
Another thing that I don’t know if it would work is e.g., using device ids for cuda 0-2 via device_ids and then setting output_device=torch.device('cuda:3'). Let me know if that works, I’d be curious.
Unfortunately, setting output to CPU results in ValueError: Expected a cuda device, but got: cpu. Setting output to GPU 3 seems to only collect the loss to that GPU. Gradients seem to still be gathered in GPU 0.
Reducing batch size won’t work since I am already processing a single sample on each GPU due to the large size of my model.
oh that’s too bad. Unfortunately, I don’t have any better idea how to tackle this case.
Setting output to GPU 3 seems to only collect the loss to that GPU. Gradients seem to still be gathered in GPU 0.
I think this would be a useful thing to get to work properly such that the gradients are also gathered on the output device. I am not sure if this is a bug or a limitation, but I think this could be a useful feature/fix in PyTorch. Maybe that could be posted on the issue tracker for further discussion/investigation.
I actually just found that someone implemented a solution to this problem. While this is exactly what you were looking for, i haven’t tried it myself yet and am not sure how well it works – in theory though, it addresses the problem of unbalanced loads in DataParallel. They describe it in the context of Semantic Segmentation, but I assume it should work in more general and encompass other objective functions:
I got lucky today and found a way to get near-equal utilization across GPUs.
The two main changes were:
Make sure my outer-most module is wrapped by DataParallel. Before I had an inner module (like a layer) wrapped only.
From:
class BundledNet(nn.Module):
def __init__(self, net, preproc=None):
self.net = net
if torch.cuda.device_count() > 1:
self.net = torch.nn.DataParallel(self.net)
self.preproc = preproc
def forward(self, x):
if self.preproc != None:
x = self.preproc(x)
x = self.net(x)
return x
net = BundledNet(ResNet(), preproc=resnet_norm)
To:
class BundledNet(nn.Module):
def __init__(self, net, preproc=None):
self.net = net
self.preproc = preproc
def forward(self, x):
if self.preproc != None:
x = self.preproc(x)
x = self.net(x)
return x
net = BundledNet(ResNet(), preproc=resnet_norm)
if torch.cuda.device_count() > 1:
net = torch.nn.DataParallel(net)
It appears that the preprocessing and post-processing in the forward pass of BundledNet was enough to cause an imbalance across the GPUs.
Compute my loss function inside a DataParallel module.
From:
loss = torch.nn.CrossEntropyLoss()
To:
loss = torch.nn.CrossEntropyLoss()
if torch.cuda.device_count() > 1:
loss = CriterionParallel(loss)
Given:
class ModularizedFunction(torch.nn.Module):
"""
A Module which calls the specified function in place of the forward pass.
Useful when your existing loss is functional and you need it to be a Module.
"""
def __init__(self, forward_op):
super().__init__()
self.forward_op = forward_op
def forward(self, *args, **kwargs):
return self.forward_op(*args, **kwargs)
class CriterionParallel(torch.nn.Module):
def __init__(self, criterion):
super().__init__()
if not isinstance(criterion, torch.nn.Module):
criterion = ModularizedFunction(criterion)
self.criterion = torch.nn.DataParallel(criterion)
def forward(self, *args, **kwargs):
"""
Note the .mean() here, which is required since DataParallel
gathers any scalar outputs of forward() into a vector with
one item per GPU (See DataParallel docs).
"""
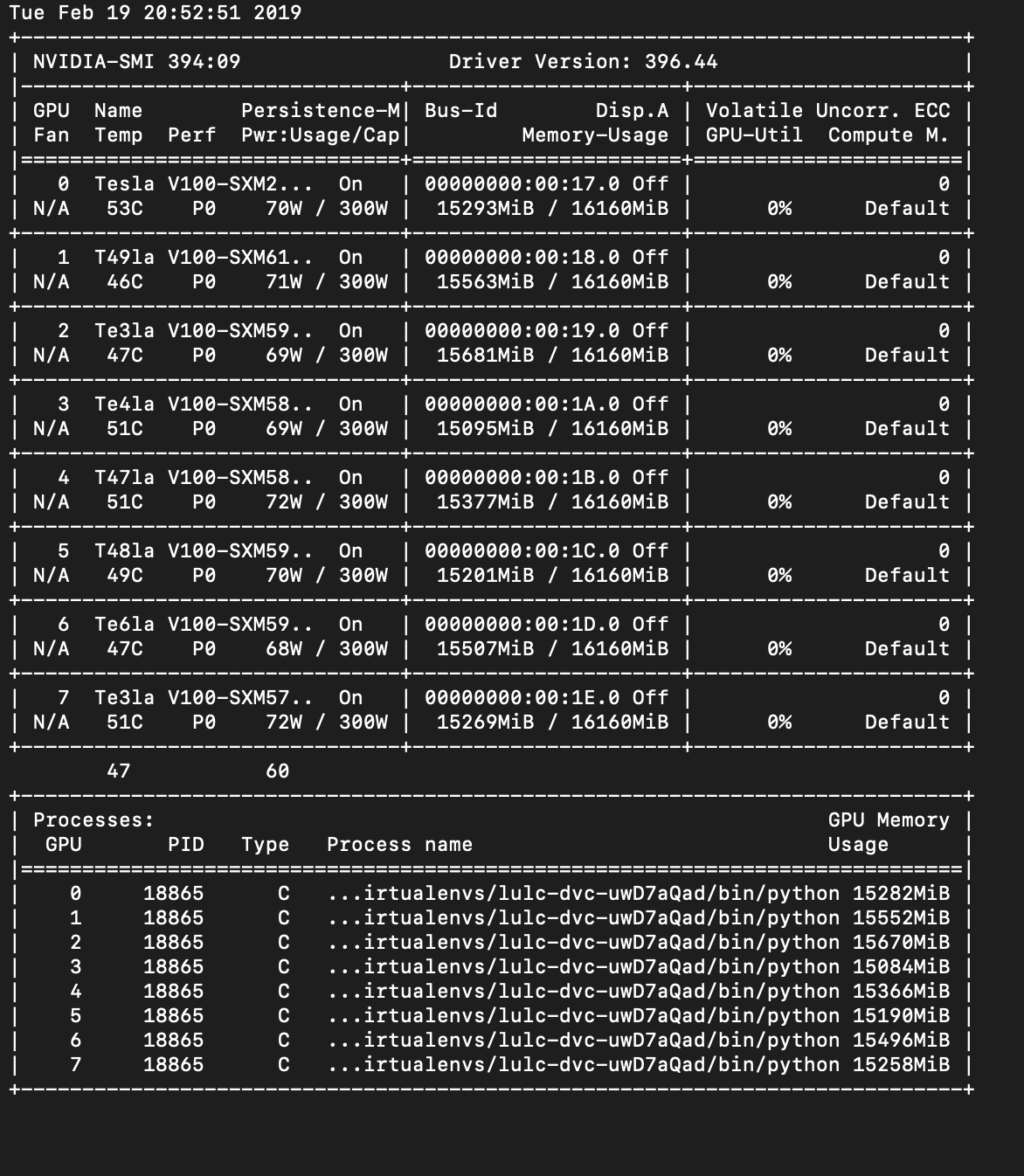
return self.criterion(*args, **kwargs).mean()
The general rule seems to be that you should try not to do any cuda tensor computation whatsoever outside the forward pass of a DataParallel module. Outside of a DataParallel module, I am only passing tensors around and moving them on and off the GPU. See this before/after image of nvidia-smi to see the results: