Hello,
I’m saving my model outputs as tensors by torch.save() under the no_grad() context manager. However, I noticed that from one job, tensors with shape (524, 720) and float32 consume ~200 MB disk usage, whereas from another set of tensors I created from a separate job with the same shape and dtype, they only take ~4MB. Also, when I take the clone() of the 200MB tensors, the cloned version takes a regular 4MB disk usage. I was wondering if it was due to gradient tracking that occupies the additional disk space, but both of them have requires_grad=False and have no grad function. Interestingly, when I rerun the same code I got the regular 4MB tensors and cannot reproduce the 200MB ones. I’m using torch 2.0.1 on a linux server, and jobs are submitted using slurm.
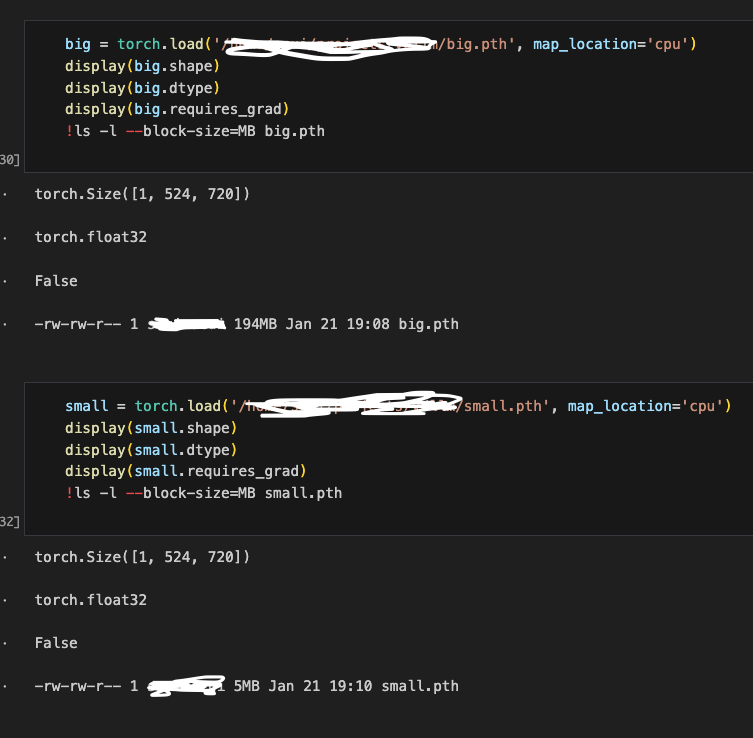
What could be the reason behind the discrepancy in their disk usage?
Below is the link to the 200MB tensor uploaded to my google drive, if anyone would like to take a look ![]()
Thank you so much for the help in advance ![]() And sorry if this is trivial…
And sorry if this is trivial…