Hi,
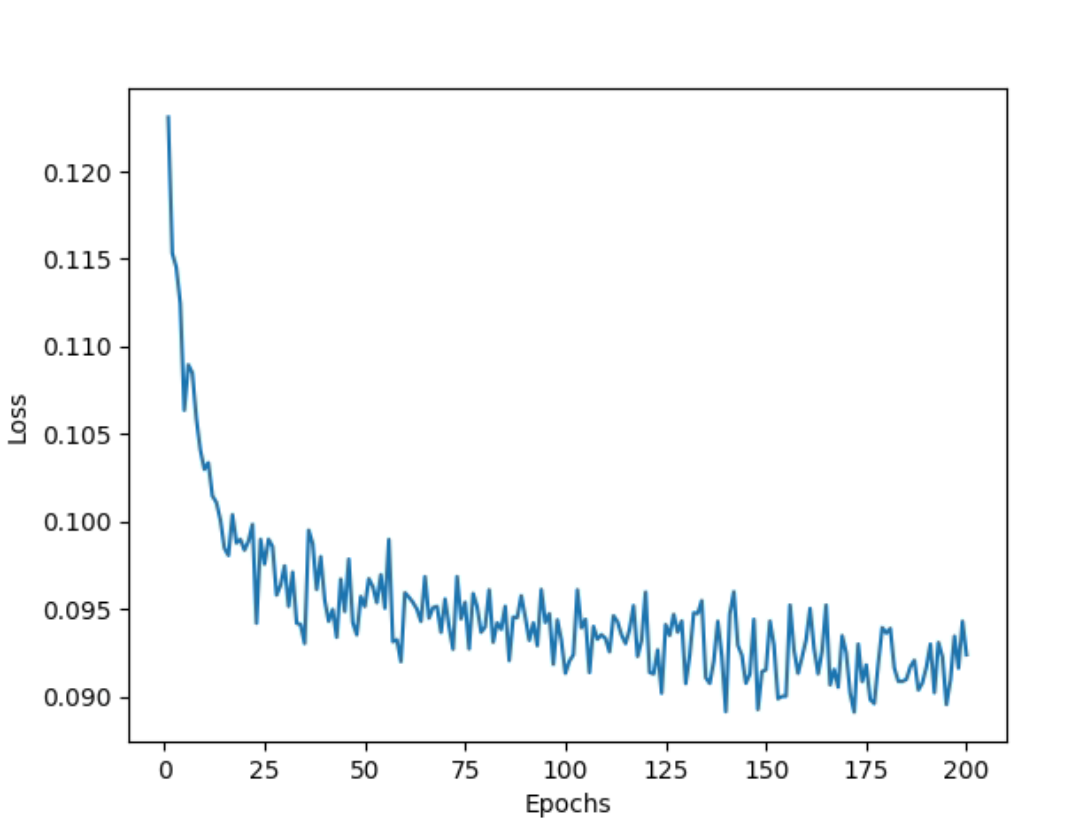
My previous challenge entailed the non-minimization and oscillation of loss during the training. Upon a thorough investigation, I identified a broken computation graph that impeded updating the model parameters. At present, the loss demonstrates a downward trend, but it becomes stagnant after a few epochs.
As can be observed from the graph, there is no significant improvement beyond approximately 125 epochs, remaining more or less constant afterward.
NOTE: I have tried the above experiments for Learning rates ranging from 1e-2 to 1e-6; Weight decay from 1e-3 to 1e-6; for optimizers both Adam and SGD; epochs from 50 to 200 (with and without early stopping). The loss graph for all the experiments conducted so far is similar to the above snapshot.
I’m still skeptical about your solution of making sure the target tensor is attached to a computation graph as mentioned here, since it’s common to assume a static target while the model outputs should of course be attached to the computation graph created in the forward pass of the model.
I understand your point, and I may have been unclear in my previous post. Unfortunately, target_val was somehow attached to the computational graph in my calculations, which was one of the issues. Additionally, I had performed some mathematical functions (non-differentiable) internally on pred_value in the forward pass, which raised further complications. I have addressed the glitch in the computation process caused by such problematic tasks.
However, currently, I am facing a hurdle where the loss is stuck at a certain point after a few epochs.