Hello everyone, I wrote the code below to test the GPU memory for a training process. Here is the code
import os
import torch
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
to_mb = 1024**2
last_memory = 0
def get_gpu_memory():
return torch.cuda.memory_allocated()/to_mb
def get_gpu_memory_change():
global last_memory
now_gpu = get_gpu_memory()
changed = now_gpu - last_memory
last_memory = now_gpu
print(f"memory_usage_add:{changed} MB, total_memory_usage_now:{now_gpu} MB")
def get_max_gpu_allocated():
return torch.cuda.max_memory_allocated()/to_mb
data_type = torch.float32
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear = torch.nn.Sequential(torch.nn.Linear(10240, 10240,dtype=data_type),
torch.nn.Linear(10240, 10240, dtype=data_type),
torch.nn.Linear(10240, 10240, dtype=data_type),
torch.nn.Linear(10240, 10240, dtype=data_type)
)
def forward(self,input):
input = self.linear(input)
# for index in range(100):
# input = self.linear[index](input)
return input
# with torch.no_grad():
model = Model().cuda()
get_gpu_memory_change()
optimizer = torch.optim.AdamW(model.parameters())
get_gpu_memory_change()
data = torch.randn(1024, 10240, dtype=data_type).cuda()
get_gpu_memory_change()
batch_size = 1
print("*"*5+"now start Training"+"*"*5)
for each in range(batch_size):
#print("*"*10)
output = model(data)
get_gpu_memory_change()
print(f"after forward propagation, max gpu allocated is {get_max_gpu_allocated()} MB")
loss = torch.sum(output)
get_gpu_memory_change()
loss.backward()
get_gpu_memory_change()
print(f"after backward propagation, max gpu allocated is {get_max_gpu_allocated()} MB")
optimizer.step()
get_gpu_memory_change()
print(f"after optimizer step, max gpu allocated is {get_max_gpu_allocated()} MB")
optimizer.zero_grad()
get_gpu_memory_change()
print(torch.cuda.max_memory_reserved()/to_mb)
I run the code on NVIDIA A100 with cuda version 11.7 on linux. And I got different result with torch 2.0.0 and torch 2.1.0.
For torch 2.0.0, results are
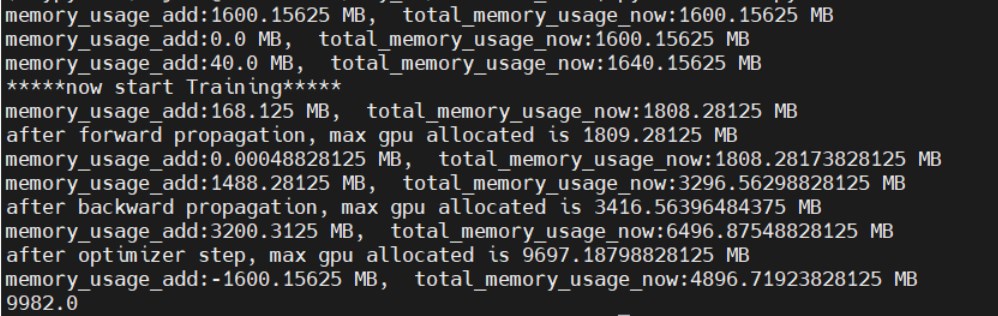
and the max GPU memory allocated is 9697.18798828125 MB
For torch 2.1.0, results are
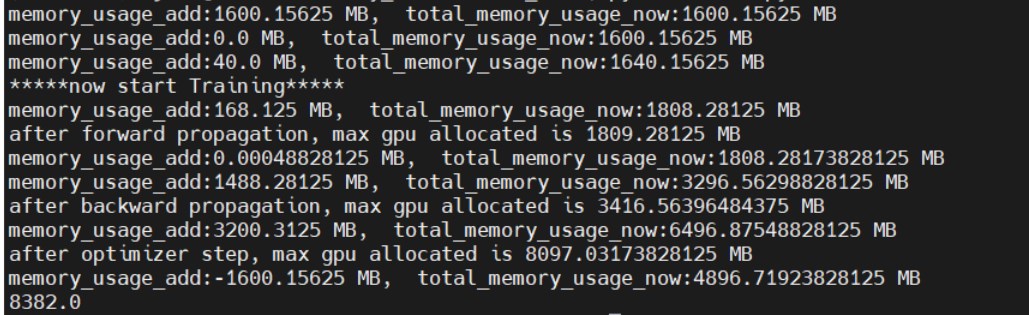
and the max GPU memory allocated is 8097.03173828125 MB
Here is my analyze about max GPU memory allocated:
So just ignored the middle result during forward process and just considering model paraterms, gradient and optimizer state.
According to the adam document
[Adam — PyTorch 2.1 documentation]
I think for each parameter, we will have 4 optimizer state parameter related to it. So the peak of GPU memory usage is around 6 times for model parameter (1600MB) memory usage which should be around 9600 MB as the torch 2.0.0’s result.
But with torch 2.1.0, the result is just about 1600MB less than torch 2.0.0’s result, which just equal the memory usage of the model parameter.
Can anybody tell me what is the difference? Thanks