Hi there I get the following error when trying to train my model…
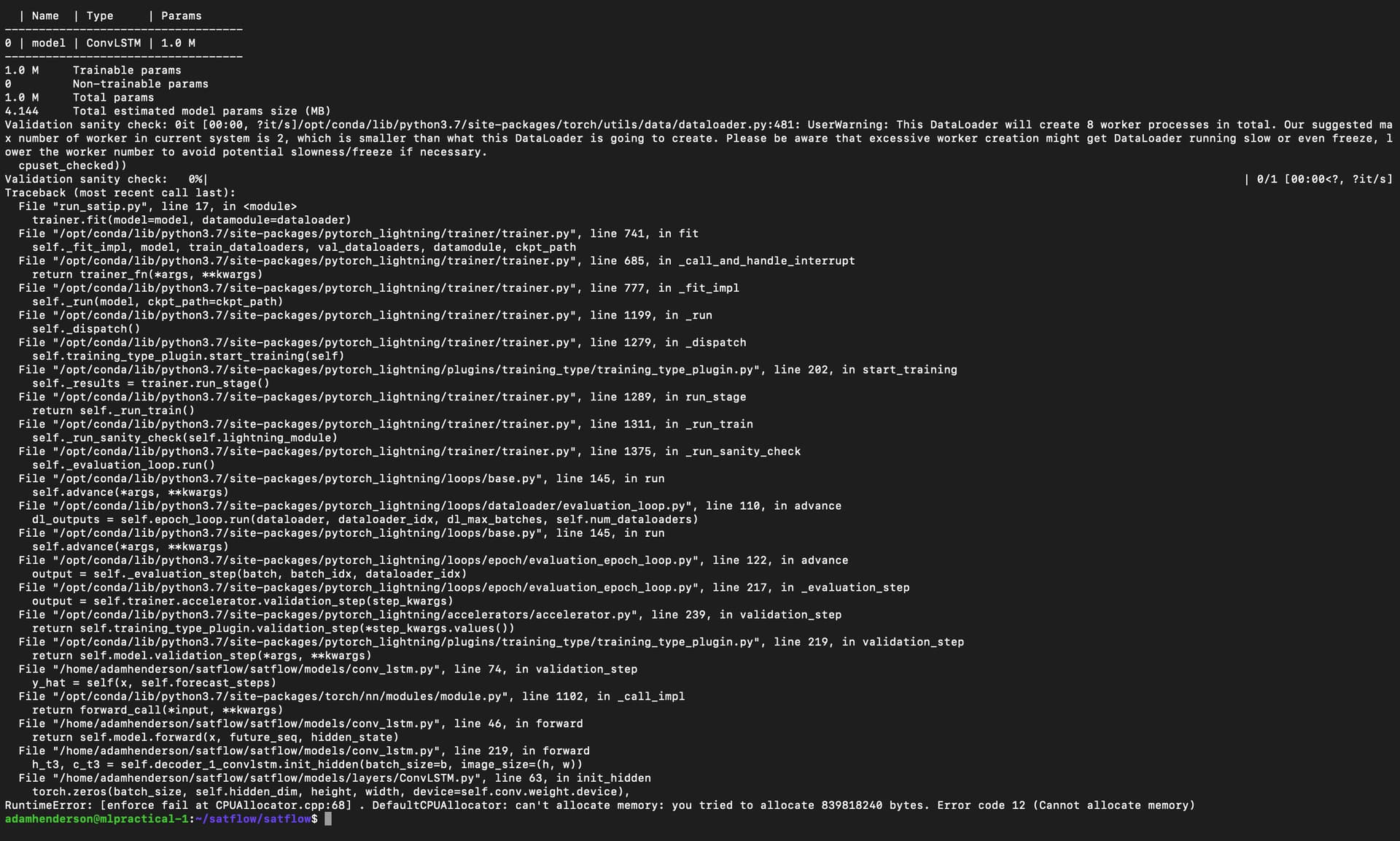
RuntimeError: [enforce fail at CPUAllocator.cpp:68] . DefaultCPUAllocator: can’t allocate memory: you tried to allocate 839818240 bytes. Error code 12 (Cannot allocate memory)
This error is seen quite a lot on internet forums however I do not believe the memory it is trying to allocate is too much in this case as 839818240 bytes = 0.8 GB roughly…
The failing call tries to allocate ~0.78GB, but note that the script (or other processes) might have already allocated memory on the host.
Check the host RAM usage during the lifetime of your script and check its peak usage before the OOM is raised.
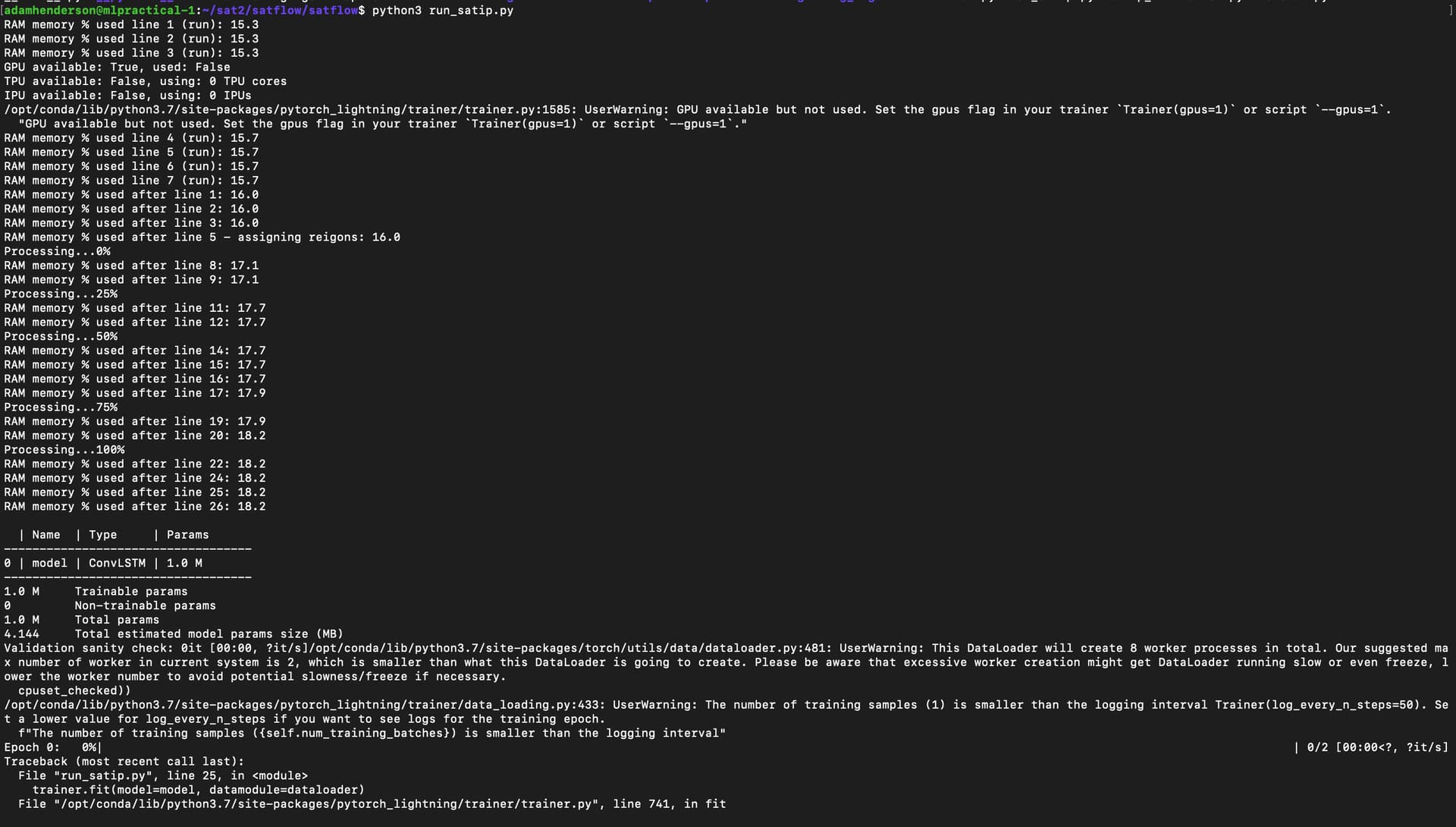
thankyou for the reply! I have printed RAM usage at each line of my script and the output has been attached below. What is confusing me here is that it does not use anymore than 20% of the max RAM at the time when the error occurs! The error seems to raise when I run the line ‘trainer.fit(model)’ where trainer is an instance of Trainer() class in the pytorch_lightning library.
I should also mention that ‘RAM memory (run)’ is the RAM used from running the running script and ‘RAM memory’ without the ‘(run)’ is the RAM usage from the script that loads the data we are training on.
I am a bit confused about the fact that the built-in ‘Trainer()’ class is throwing the error. Why might this be? Does this mean I will struggle to solve the problem as we cannot change this script?
I guess the Trainer class tries to allocate more memory internally and is then running into the issue.
You might thus want to add more debugging print statements to the actual model definition (and/or Dataset) to see where this memory is being allocated (I don’t know what the Trainer class is doing in detail).