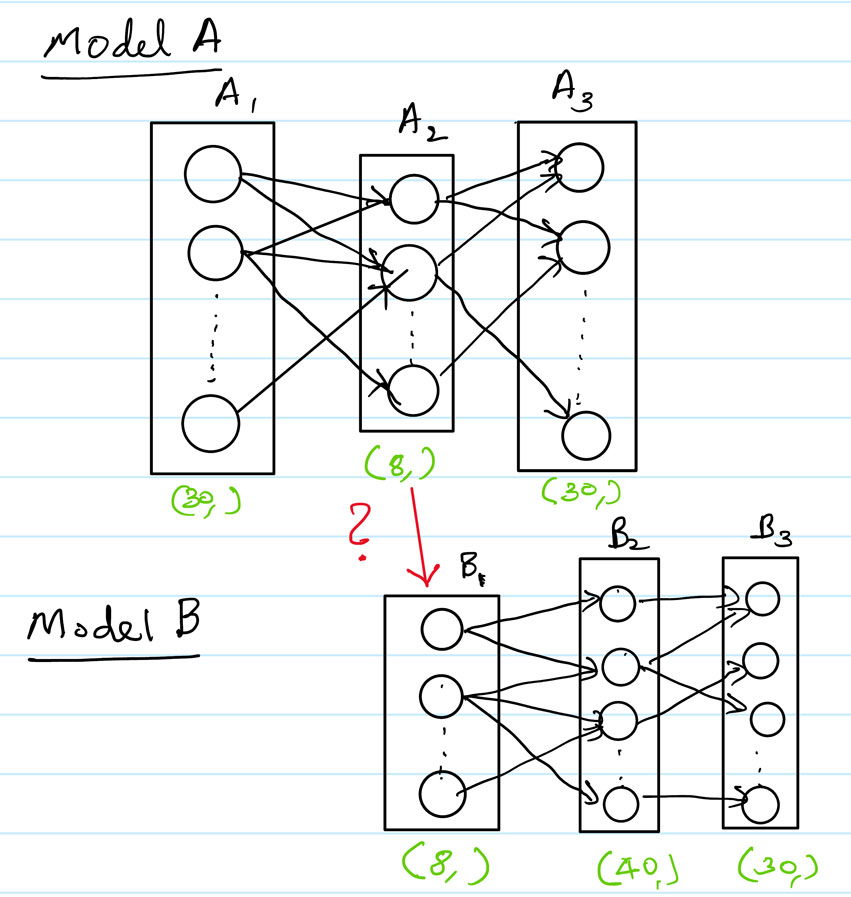
I have implementations of ModelA and ModelB that work fine when I train them separately. I am thinking of creating a class that will merge both of them inspired by this: Combining Trained Models in PyTorch - #2 by ptrblck.
My questions would be:
How do I handle the parameters? I want to pass ModelA and ModelB parameters to the same optimizer object. Can they be concatenated easily with some pytorch funcion?.
Should the loss function be the sum of lossA and lossB?. That question comes because even though the data set is the same for both models, ModelA’s loss “units” are different from those of ModelB’s. For example: lossA are in units of length and lossB are in units of force or energy.
I would appreciate any advice with this and even some code I am working on this and when coming to a solution I will post it here for reference.
I have a method class that extract those activations and I will be using them as inputs for B1. I hope, but might be wrong, that I won’t encounter size mismatches! I will report back later about it.
So you are still using the beginning part of model A (A1 and A2) as inputs to B2? The hybrid model would then be A1, A2/B1, B2, B3 with shapes 30x8, 8x40, 40x30 and it should work…
Do you compute the activations beforehand / offline for all your data and store them as features / inputs for model B later? That should also work, but I was thinking you would compute them on the fly at each forward pass. But in any case, both should work.
@alex.veuthey I don’t. What I do is I forward propagate model A (an autoencoder), and subsequently use the latent hidden layer as input for model B (everything online?). I finally got time to keep working again on this and am to the point where I concatenate the parameters of the models in one single list.
Is this correct? It seems to me that pytorch is so smart that figures out everything. I wonder if I should sum the losses before doing loss.backward() or running them independently is fine? Would that change anything?
@ptrblck, @alex.veuthey I would appreciate any input from you guys :), and thanks for your help!
Summing the losses (can be done with weighting or equal proportions) is definitely different from running them separately. If you do loss.backward() with the (weighted) sum then everything is backpropagated, which is not necessarily what you want.
In your case, I think it depends on whether you want to train weights in ModelA when you train ModelB, or if you keep them separate (i.e. the weights in A are fixed when training B). If you include parameters of A in the second loss as a (possibly weighted) sum, then those parameters are going to be updated by the optimizer step.
Also if you simply take the A loss and add it to the B loss, then there are weights in A that contribute to the A loss but should not contribute to the B loss (in your drawing: layer A3). So I guess you would need an intermediate A loss that takes that into account.
Disclaimer: I’m not familiar with and have never trained an encoder/decoder network, but what I’ve described seems like the logical behaviour to me…
Summing the losses (can be done with weighting or equal proportions) is definitely different from running them separately. If you do loss.backward() with the (weighted) sum then everything is backpropagated, which is not necessarily what you want.
Thanks for clarifying this. I would like the weights of ModelA to be dependent on ModelB, too. Therefore I should be combining the losses to backward propagate. I guess something like:
losses = (a * lossA) + (b * lossB)
losses.backward()
In your case, I think it depends on whether you want to train weights in ModelA when you train ModelB , or if you keep them separate (i.e. the weights in A are fixed when training B). If you include parameters of A in the second loss as a (possibly weighted) sum, then those parameters are going to be updated by the optimizer step.
I was getting confused because I am basically calling lossA.backward() and lossB.backward() separately but the optimizer object gets list(modelA.parameters()) + list(modelB.parameters()). I thought that that would make the trick, but as your reply suggests, that is not correct. When I do that I am basically updating, for example, modelA’s parameters using gradients of modelA.parameters() only.
Also if you simply take the A loss and add it to the B loss, then there are weights in A that contribute to the A loss but should not contribute to the B loss (in your drawing: layer A3). So I guess you would need an intermediate A loss that takes that into account.
This is an interesting point. I think I will have to explore because I have no idea.
Disclaimer: I’m not familiar with and have never trained an encoder/decoder network, but what I’ve described seems like the logical behaviour to me…
That is fine. Your comments make sense to me. I am not familiar with these models either . Thank you, this has been very useful. This community is very cool.