I am trying to load and run the meta-llama/Meta-Llama-3-8B on a 16 GB Nvidia RTX 4060 Ti.
I am using the following BitsAndBytesConfig to load the model in 4-bit and use torch.bfloat16 for compute.
bnb_config = BitsAndBytesConfig(
# load_in_8bit=True,
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
model = AutoModel.from_pretrained(
'meta-llama/Meta-Llama-3-8B',
quantization_config=bnb_config,
device_map='auto'
)
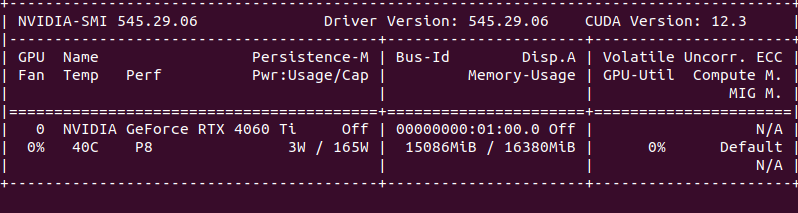
Just loading the model, the nvidia-smi output shows almost about 4.5 GB of GPU memory being used.
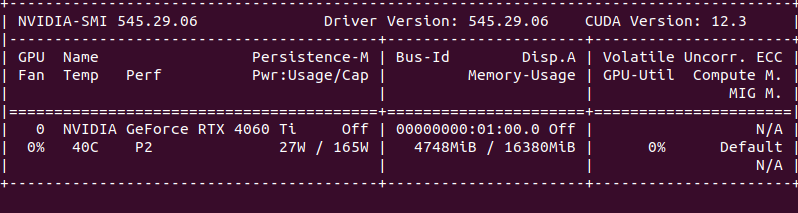
Then when I run the following command, the GPU memory immediately shoots up to 15.5 GB.
inp_sample = next(iter(train_loader))
logits = model(ex_sample['input_ids'])
I think I am missing something but just running one sample of size [2, 512] through this Meta-Llama-3-8B increases the memory by this much.
Added a couple of screenshots for reference. Would love any pointers on this one.
Just Loading the model
I want to try fine tuning the model after but that seems impossible now if the an 8B model 4-bit model runs a 16GB GPU out of memory.