You should make sure that if you store a list of nn.Parameters, it should be in a nn.ParameterList and not a plain python list, same if you store a list of nn.Modules should be in a nn.ModuleList.
Thanks for the quick reply. My completed code looks like:
param_frozen_list = [] # should be changed into torch.nn.ParameterList()
param_active_list = [] # should be changed into torch.nn.ParameterList()
for name, param in model.named_parameters():
if name == 'frozen_condition':
param_frozen_list.append(param)
elif name == 'active_condition':
param_active_list.append(param)
else:
continue
optimizer = torch.optim.SGD([
{'params': param_frozen_list, 'lr': 0.0},
{'params': param_active_list, 'lr': args.learning_rate}],
lr = args.learning_rate,
momentum = args.momentum,
weight_decay = args.weight_decay)
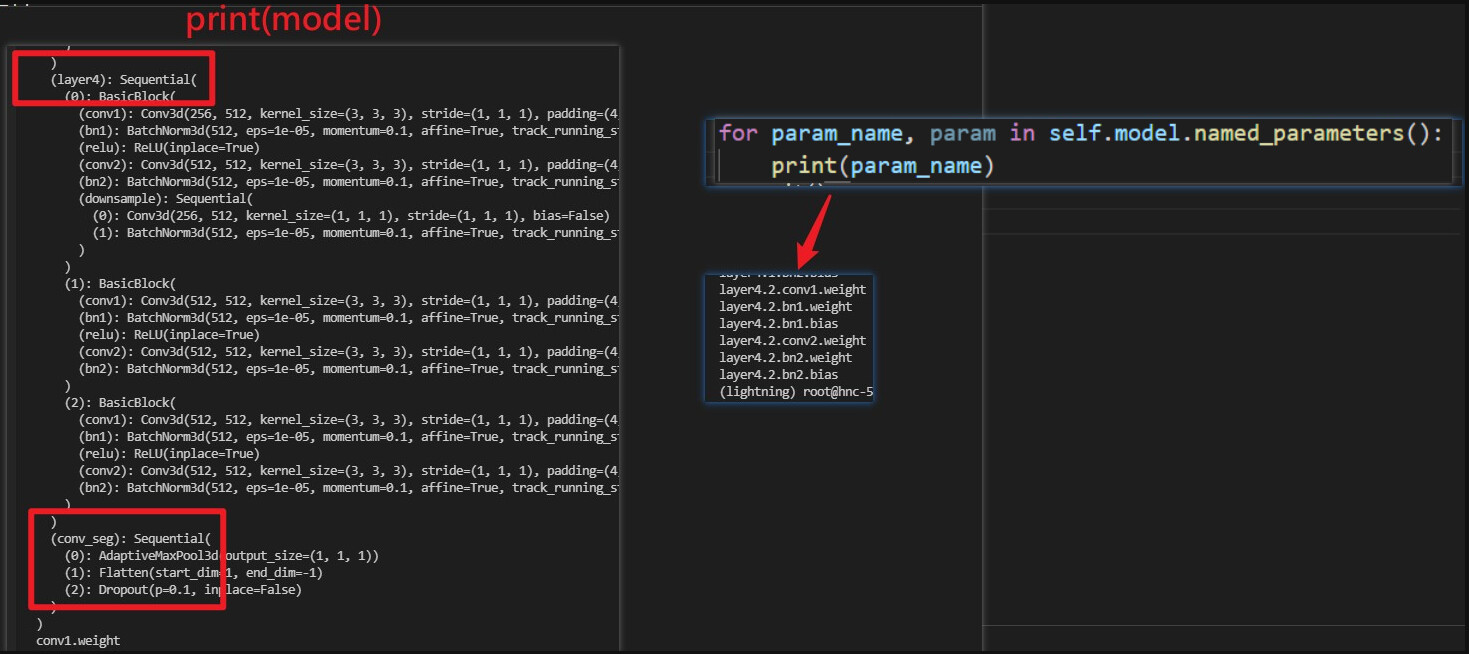
The key problem is that in the loop result of model.named_parameters(), some layers is lost.
I use model.modules() to check out that they exits in the full module sequences. So is there wrong in my code or a pytorch bug?
the named_parameters() method does not look for all objects that are contained in your model, just the nn.Modules and nn.Parameters, so as I stated above, if you store you parameters outsite of these, then they won’t be detected by named_parameters().
Thanks. I understand what you mean, but I create all the layers by using class LayerName(nn.Module) and there is no any other parameters beyond the torch.nn.layers.
I think they are registered properly and can be visible.
I change the method to group the parameters via model.state_dict() like this:
for k, v in model.state_dict().items():
name = k
param = torch.nn.Parameter(v)
Does this way can be seemed as same with named_parameters()?
The thing is that if named_parameters does not work properly, then .parameters doesn’t either, and that could be a problem if you use it to create your optimizer. Check the exemple below of what will and what won’t work.
class MyLayer(nn.Module):
def __init__(self, arg):
super(MyLayer, self).__init__()
self.linear = nn.Linear(...) # that will work
self.linears = nn.ModuleList(nn.Linear(...), nn.Linear(...)) # that will work
self.wrong_linears = [nn.Linear(...), nn.Linear(...)] # that will NOT work
self.wrong_linears_2 = {1: nn.Linear(...), 2: nn.Linear(...)} # that will NOT work
# And similarly for nn.Parameter !
# Also anything saved as `torch.Tensor` or `torch.autograd.Variable` will NOT work
def forward(self, args):
# some code