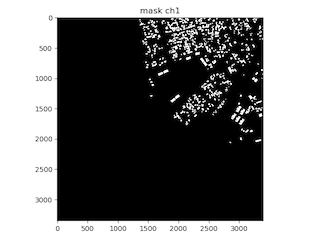
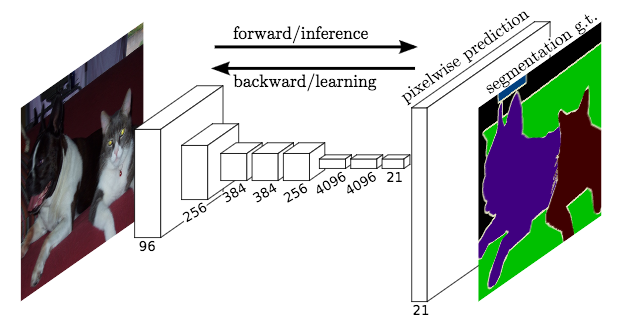
This is the entire train loop:
def train(model, optimizer, loss_fn, dataloader, metrics, params):
"""Train the model on `num_steps` batches
Args:
model: (torch.nn.Module) the neural network
optimizer: (torch.optim) optimizer for parameters of model
loss_fn: a function that takes batch_output and batch_labels and computes the loss for the batch
dataloader: (DataLoader) a torch.utils.data.DataLoader object that fetches training data
metrics: (dict) a dictionary of functions that compute a metric using the output and labels of each batch
params: (Params) hyperparameters
num_steps: (int) number of batches to train on, each of size params.batch_size
"""
# set model to training mode
model.train()
# summary for current training loop and a running average object for loss
summ = []
loss_avg = RunningAverage()
# Use tqdm for progress bar
with tqdm(total=len(dataloader)) as t:
for i, (train_batch, labels_batch) in enumerate(dataloader):
# move to GPU if available
if params.cuda:
train_batch, labels_batch = train_batch.cuda(async=True), labels_batch.cuda(async=True)
# convert to torch Variables
train_batch, labels_batch = Variable(train_batch), Variable(labels_batch)
# compute model output and loss
output_batch = model(train_batch)
#logger.debug("train output_batch.shape = {}. labels_batch.shape = {}".format(output_batch.shape, labels_batch.shape))
# check if predictions are negative
logger.info("negative predictions: {}".format((output_batch < 0.0).any()))
# compute loss
loss = loss_fn(output_batch, labels_batch)
logger.debug("loss: {}".format(loss.data.item()))
# clear previous gradients, compute gradients of all variables wrt loss
optimizer.zero_grad()
loss.backward()
# performs updates using calculated gradients
optimizer.step()
# Evaluate summaries only once in a while
if i % params.save_summary_steps == 0:
# extract data from torch Variable, move to cpu, convert to numpy arrays
output_batch = output_batch.data.cpu().numpy()
labels_batch = labels_batch.data.cpu().numpy()
# compute all metrics on this batch
summary_batch = {metric:metrics[metric](output_batch, labels_batch)
for metric in metrics}
summary_batch['loss'] = loss.data.item()
summ.append(summary_batch)
# update the average loss
loss_avg.update(loss.data.item())
t.set_postfix(loss='{:05.3f}'.format(loss_avg()))
t.update()
# compute mean of all metrics in summary
metrics_mean = {metric:np.mean([x[metric] for x in summ]) for metric in summ[0]}
metrics_string = " ; ".join("{}: {:05.3f}".format(k, v) for k, v in metrics_mean.items())
logger.info("- Train metrics: " + metrics_string)
def train_and_evaluate(model, train_dataloader, val_dataloader, optimizer, loss_fn, metrics, params, model_dir,
restore_file=None):
"""Train the model and evaluate every epoch.
Args:
model: (torch.nn.Module) the neural network
train_dataloader: (DataLoader) a torch.utils.data.DataLoader object that fetches training data
val_dataloader: (DataLoader) a torch.utils.data.DataLoader object that fetches validation data
optimizer: (torch.optim) optimizer for parameters of model
loss_fn: a function that takes batch_output and batch_labels and computes the loss for the batch
metrics: (dict) a dictionary of functions that compute a metric using the output and labels of each batch
params: (Params) hyperparameters
model_dir: (string) directory containing config, weights and log
restore_file: (string) optional- name of file to restore from (without its extension .pth.tar)
"""
# reload weights from restore_file if specified
if restore_file is not None:
restore_path = os.path.join(model_dir, restore_file + '.pth.tar')
logger.info("Restoring parameters from {}".format(restore_path))
load_checkpoint(restore_path, model, optimizer)
best_val_acc = 0.0
for epoch in range(params.num_epochs):
# Run one epoch
logger.info("Epoch {}/{}".format(epoch + 1, params.num_epochs))
# compute number of batches in one epoch (one full pass over the training set)
train(model, optimizer, loss_fn, train_dataloader, metrics=metrics, params=params)
# Evaluate for one epoch on validation set
val_metrics = evaluate(model, loss_fn, val_dataloader, metrics=metrics, params=params)
# TODO: Fix TypeError: 'NoneType' object is not subscriptable
val_acc = val_metrics['accuracy']
is_best = val_acc>=best_val_acc
# Save weights
save_checkpoint({'epoch': epoch + 1,
'state_dict': model.state_dict(),
'optim_dict' : optimizer.state_dict()},
is_best=is_best,
checkpoint=model_dir)
# If best_eval, best_save_path
if is_best:
logger.info("- Found new best accuracy")
best_val_acc = val_acc
# Save best val metrics in a json file in the model directory
best_json_path = os.path.join(model_dir, "metrics_val_best_weights.json")
save_dict_to_json(val_metrics, best_json_path)
# Save latest val metrics in a json file in the model directory
last_json_path = os.path.join(model_dir, "metrics_val_last_weights.json")
save_dict_to_json(val_metrics, last_json_path)
def main():
# print some log messages
logger.info("DSTL Satellite Imagery Feature Detection - Train U-Net Model")
# load parameters
# load parameters from configuration file
params = Params('experiment/unet_model/params_3ch.yaml', ParameterFileType.YAML, ctx=None)
# parameters
logger.debug("parameters: \n{}\n".format(pformat(params.dict)))
# use GPU if available
params.cuda = torch.cuda.is_available()
# Set the random seed for reproducible experiments
torch.manual_seed(230)
if params.cuda:
torch.cuda.manual_seed(230)
# dataset parameters, which includes download, input, output and mask generation parameters.
dataset_params = params.dataset
logger.debug("dataset parameters: \n{}\n".format(pformat(dataset_params)))
# dataset
logger.info("loading datasets...")
train_set = DSTLSIFDDataset(dataset_params=dataset_params,
mode='train',
transform=True,
transform_mask=None,
download=False)
dev_set = DSTLSIFDDataset(dataset_params=dataset_params,
mode='dev',
transform=True,
transform_mask=None,
download=False)
# dataloader
logger.debug("train dataloader, batch size: {}, num workers: {}, cuda: {}".format(
params.train['batch_size'],
params.train['num_workers'],
params.cuda));
train_dl = DataLoader(dataset=train_set,
batch_size=params.train['batch_size'],
shuffle=True,
num_workers=params.train['num_workers'],
pin_memory=params.cuda)
logger.debug("dev dataloader, batch size: {}, num workers: {}, cuda: {}".format(
params.valid['batch_size'],
params.valid['num_workers'],
params.cuda));
valid_dl = DataLoader(dataset=dev_set,
batch_size=params.valid['batch_size'],
shuffle=True,
num_workers=params.valid['num_workers'],
pin_memory=params.cuda)
logger.info("- done.")
# define the model and optimizer
#model = UNet()
model = UNet().cuda() if params.cuda else UNet()
logger.info("using adam optimized with lr = {}".format(float(params.learning_rate)))
optimizer = optim.Adam(model.parameters(), lr=float(params.learning_rate))
# loss function
loss_fn = multi_class_cross_entropy_loss # nn.MSELoss() # nn.L1Loss() # nn.CrossEntropyLoss()
# maintain all metrics required in this dictionary- these are used in the training and evaluation loops
metrics = {
'accuracy': accuracy,
# could add more metrics such as accuracy for each token type
}
# train the model
logger.info("Starting training for {} epoch(s)".format(params.num_epochs))
data_dir = "data/"
model_dir = "experiment/unet_model"
train_and_evaluate(model=model,
train_dataloader=train_dl,
val_dataloader=valid_dl,
optimizer=optimizer,
loss_fn=loss_fn,
metrics=metrics,
params=params,
model_dir=data_dir,
restore_file=None)
if __name__ == '__main__':
main()