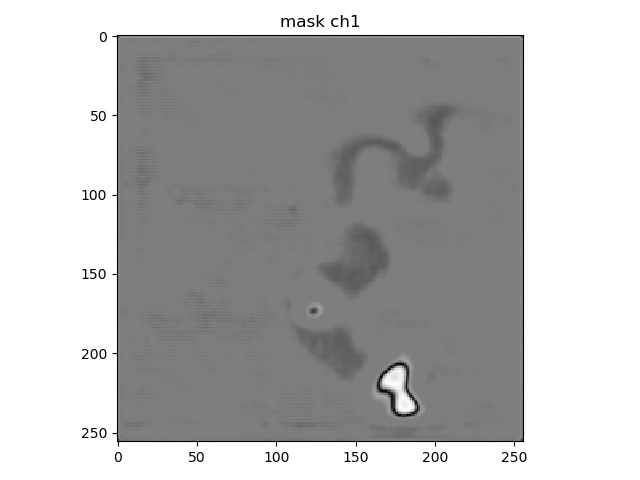
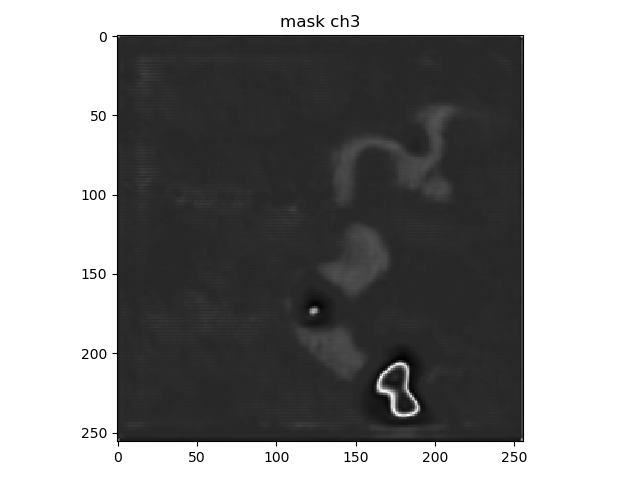
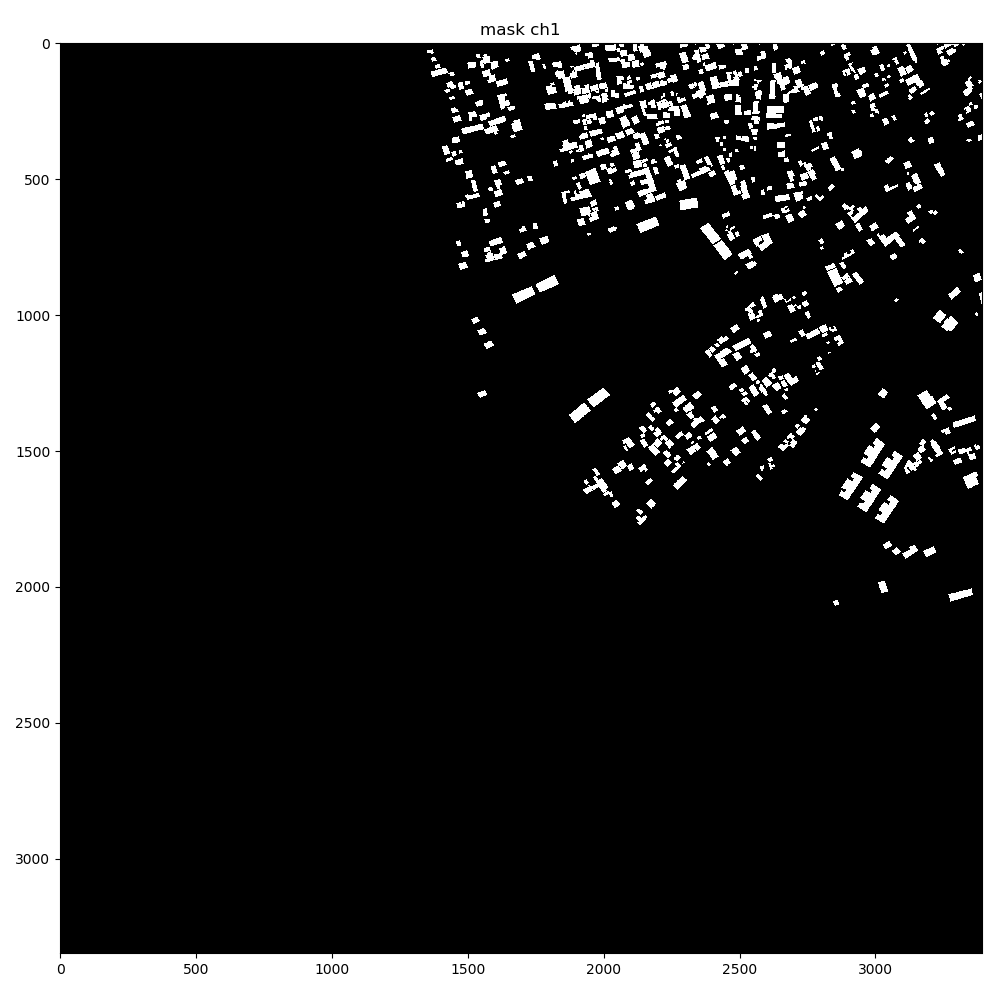
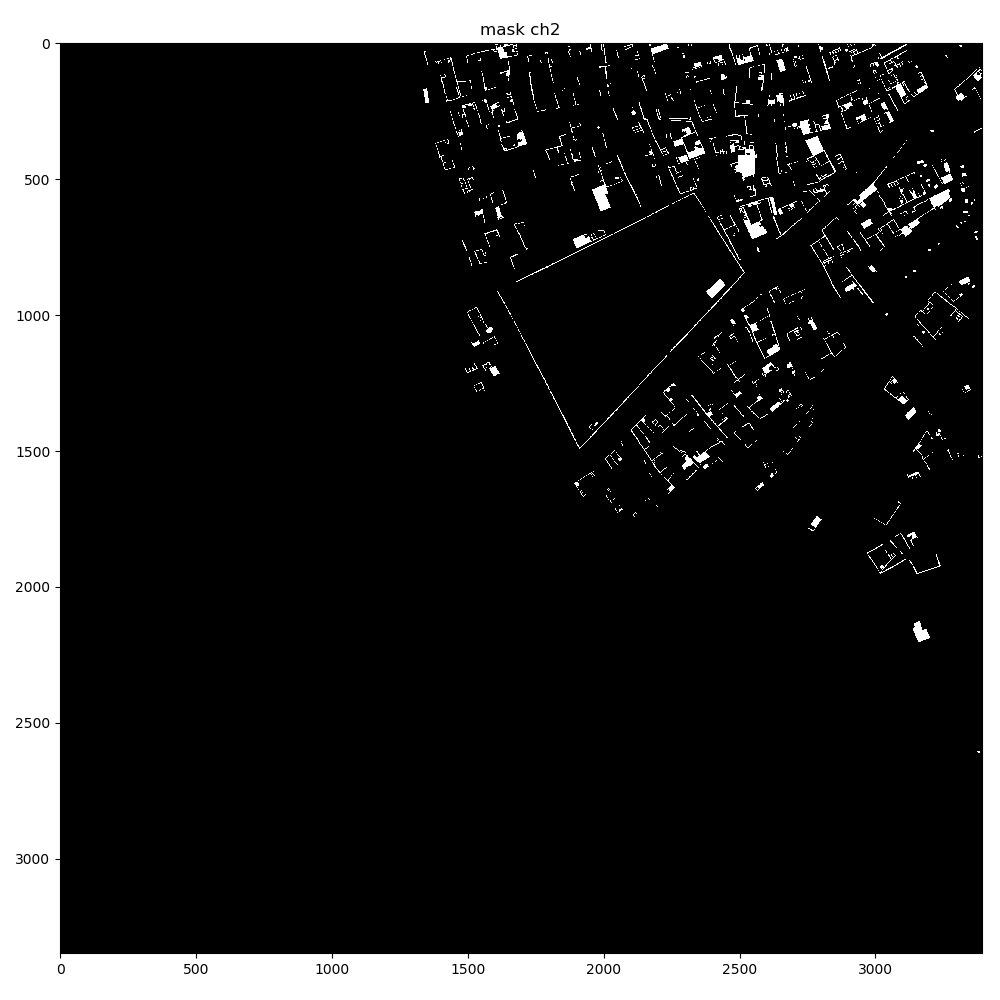
The dataset output shape for a single mask is [10, 256, 256]. The dataset getitem returns just 1 image and 1 mask.
This is the code fragment for my dataset class, just before it returns the image and mask. Image is [3, 256, 256], mask is [10, 256, 256]. U-Net model is 3-ch input and 10-ch output.
Should I be doing the class to index mapping here in side the dataset loader class, as follows:
# TODO: Remove this. Temporarily resizing both image and mask.
image = resize(image, 256, 256).transpose((2, 0, 1))
mask = resize(mask, 256, 256).transpose((2, 0, 1))
#mask = mask[0:3, :, :] # extract only the first channel of the mask
self.logger.info("image type: {}, image shape: {}, image max pixel value ch0: {}".format(image.dtype, image.shape, np.amax(image[0, :, :])))
self.logger.info("mask type: {}, mask shape: {}, mask max pixel value ch0: {}".format(mask.dtype, mask.shape, np.amax(mask[0, :, :])))
# TODO: Check if we have to convert the image and mask to torch tensors here?
image = torch.from_numpy(image).float()
mask = torch.from_numpy(mask).float()
mask = torch.argmax(mask, dim=0) # map target classes to indices
self.logger.info("image type: {}, image shape: {}".format(image.dtype, image.shape))
self.logger.info("mask type: {}, mask shape: {}".format(mask.dtype, mask.shape,))
return image, mask
2018-06-04 13:35:23 INFO | dataset:__getitem__:355: image type: float64, image shape: (3, 256, 256), image max pixel value ch0: 0.7590009134675589
2018-06-04 13:35:23 INFO | dataset:__getitem__:356: mask type: uint8, mask shape: (10, 256, 256), mask max pixel value ch0: 1
2018-06-04 13:35:23 INFO | dataset:__getitem__:364: image type: torch.float32, image shape: torch.Size([3, 256, 256])
2018-06-04 13:35:23 INFO | dataset:__getitem__:365: mask type: torch.int64, mask shape: torch.Size([256, 256])
2018-06-04 13:35:23 INFO | train_unet:train:85: train output_batch.shape = torch.Size([1, 10, 256, 256]). labels_batch.shape = torch.Size([1, 256, 256])
2018-06-04 13:35:23 INFO | evaluate_unet:display_mask_ch:145: mask shape: (256, 256, 10)