Hi @ptrblck
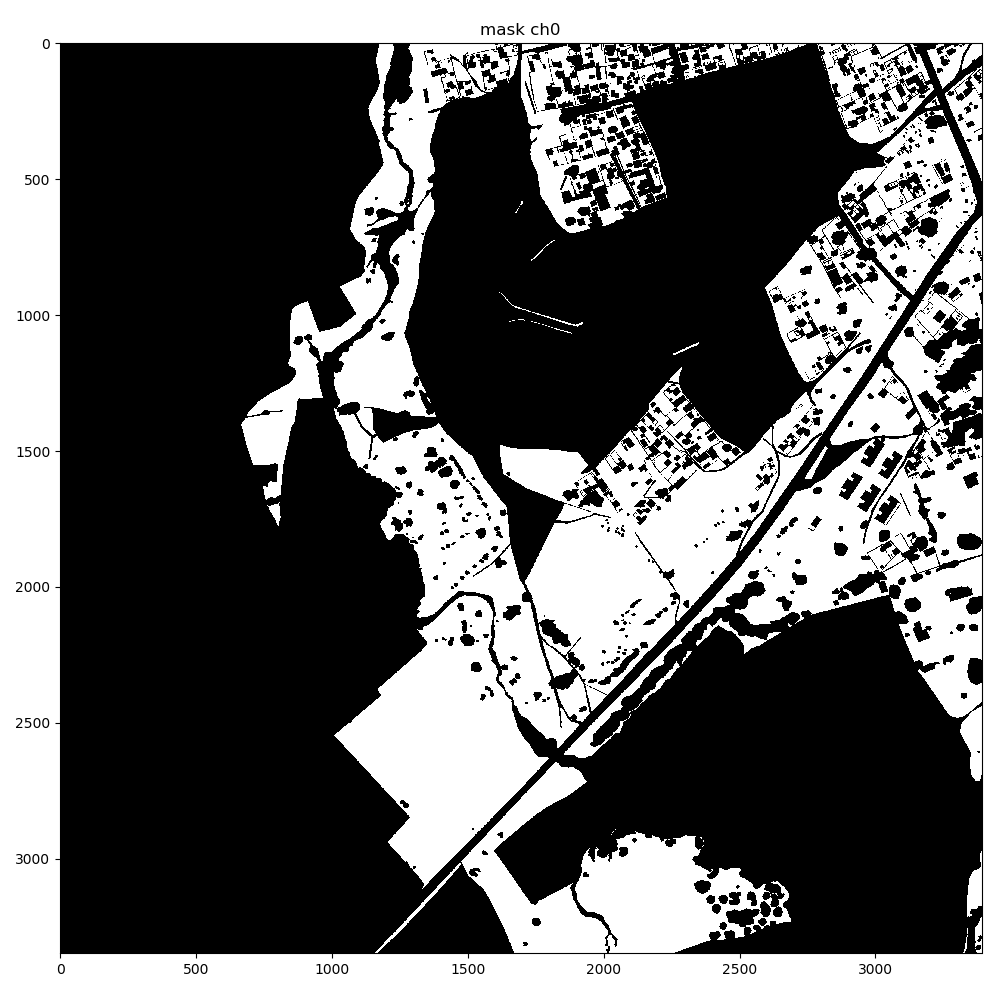
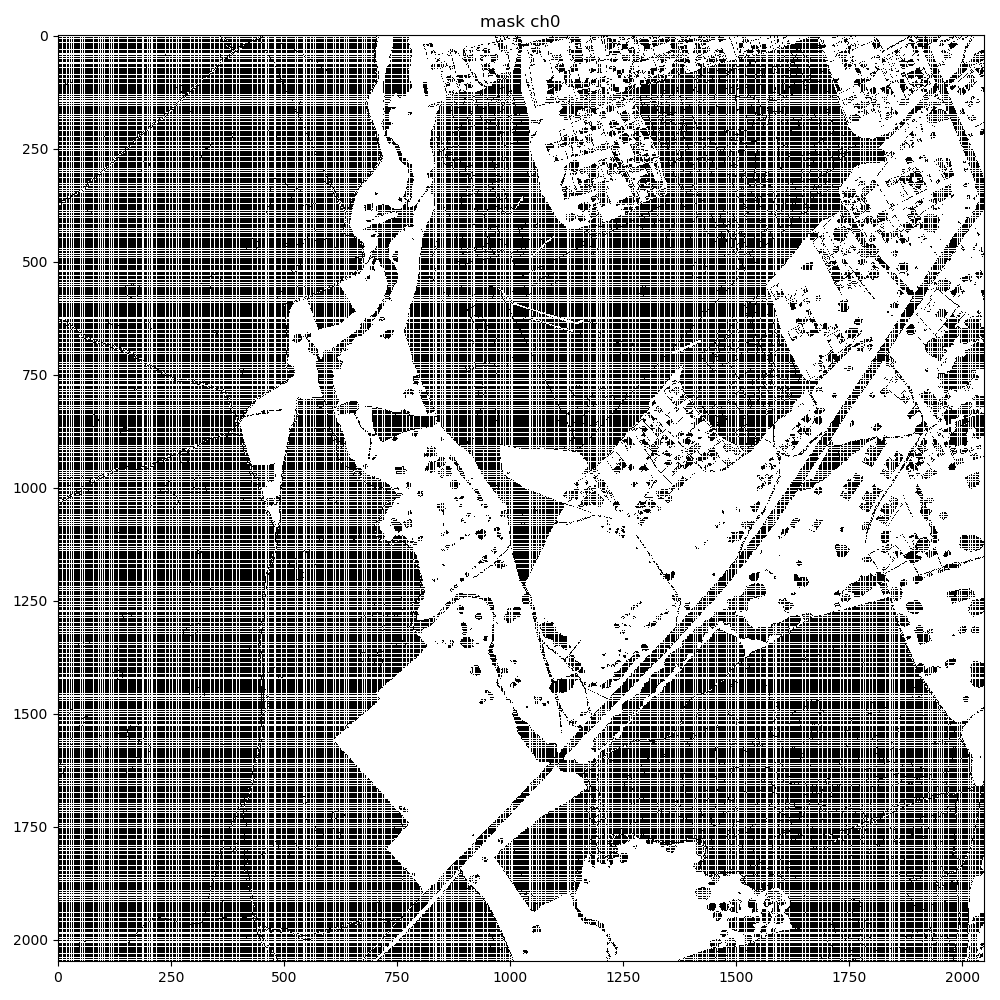
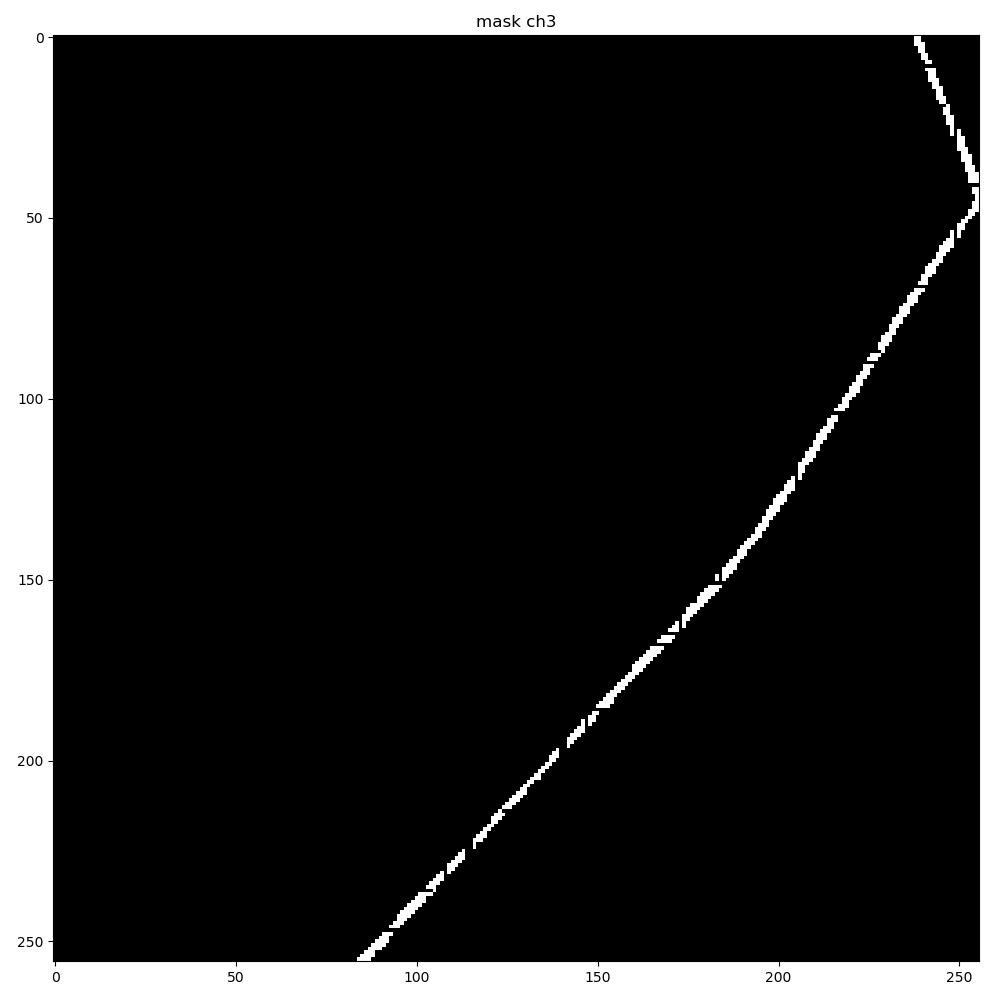
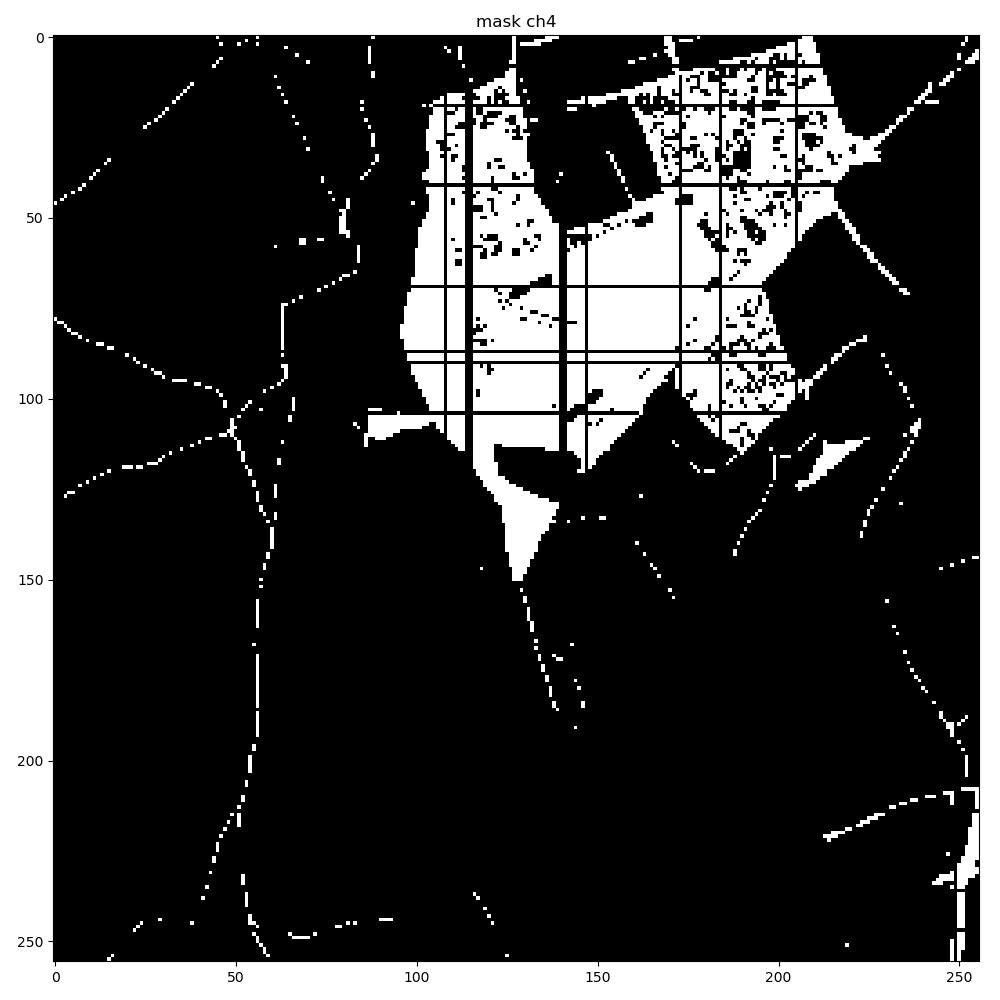
When I convert the generated mask to a Torch tensor, and convert it back, I see some corruption in the mask, with regular grid-like patterns appearing in the extracted mask as seen below. The problem gets exacerbated when using higher resolution input images at 2048x2048.
background mask ch0 corruption after tensor extraction using a resolution of 256x256
background mask ch0 corruption after tensor extraction using a resolution of 2048x2048
ch3 corruption after tensor extraction using a resolution of 256x256
ch4 corruption after tensor extraction using a resolution of 256x256
ch6 corruption after tensor extraction using a resolution of 256x256
This is a code snippet for the full test case. The mask before conversion to Torch tensors is fine, but it gets corrupted after extraction from the Torch tensor.
def test_mask_class_to_index_tensor_mapping(self):
self.logger.info("generating mask")
# mask parameters, which includes the number of channels to be included in the generated mask
self.logger.debug("mask parameters: \n{}\n".format(pformat(self.mask_params)))
# select a sample
image_id = self.dataset_partition_params['train'][0]
# generate mask
mask = self.mask_generator.mask(id=image_id, height=3349, width=3391)
self.logger.debug("generated mask type: {}, shape: {}".format(mask.dtype, mask.shape))
# resize mask
mask = resize(mask, 256, 256)
# display mask
display_mask(mask)
# convert to torch type (c x h x w)
mask = mask.transpose((2, 0, 1))
# convert to torch tensor to type long
mask = torch.from_numpy(mask).long()
self.logger.info("mask tensor type: {}, mask shape: {}".format(mask.dtype, mask.shape))
# map target classes to tensor indices
mask = torch.argmax(mask, dim=0)
self.logger.info("mask shape after class to tensor index mapping: {}".format(mask.shape))
"""
Now let' try to emulate the dataloader and retrieve the individual
mask channels.
"""
# emulate adding an extra batch dimension by the dataloader
labels_batch = torch.unsqueeze(mask, 0)
self.logger.info("labels_batch shape after unsqueeze: {}".format(labels_batch.shape))
# convert labels_batch back to target classes, for visual debug purposes
# the unsqueezed image contains one color channel and pixel values indicating the classes
n, h, w = labels_batch.shape
tensor = torch.zeros(n, self.params.out_channels, h, w)
tensor.scatter_(1, labels_batch.unsqueeze(1), 1)
self.logger.info("label tensor shape: {}".format(tensor.shape))
# convert the label tensor back to a numpy array
label_mask = tensor.numpy()[0, :, :, :].transpose([1, 2, 0]) # * 9.0 # denormalize the mask values
self.logger.info("label_mask shape: {}".format(label_mask.shape))
display_mask(label_mask)
Q01: Is this a known issue?
Q02: What could be the reason for the mask data corruption after extracting it from the Torch tensor?
Q03: Is there some other operation other than mask = torch.argmax(mask, dim=0) that will perform the required class to index mapping without causing these artifacts?