Hi,
I have an Alienware laptop with GeForce GTX 980M , and I’m trying to run my first code in pytorch - using transfer learning with resnet.
The thing is that I get no GPU utilization although all CUDA signs in python seems to be ok:
print(“torch.cuda.is_available() =”, torch.cuda.is_available())
print(“torch.cuda.device_count() =”, torch.cuda.device_count())
print(“torch.cuda.device(‘cuda’) =”, torch.cuda.device(‘cuda’))
print(“torch.cuda.current_device() =”, torch.cuda.current_device())
print(“torch.cuda.get_device_name(0) =”,torch.cuda.get_device_name(0))
cudnn.benchmark = True
#Additional Info when using cuda
if device.type == ‘cuda’:
print(torch.cuda.get_device_name(0))
print(‘Memory Usage:’)
print(‘Allocated:’, round(torch.cuda.memory_allocated(0)/10243,1), ‘GB’)
print('Cached: ', round(torch.cuda.memory_cached(0)/10243,1), ‘GB’)
torch.cuda.is_available() = True
torch.cuda.device_count() = 1
torch.cuda.device(‘cuda’) = <torch.cuda.device object at 0x0000021F70F15D68>
torch.cuda.current_device() = 0
torch.cuda.get_device_name(0) = GeForce GTX 980M
GeForce GTX 980M
Memory Usage:
Allocated: 0.0 GB
Cached: 0.0 GB
I tried googling it and also looked here but came up with nothing helpful.
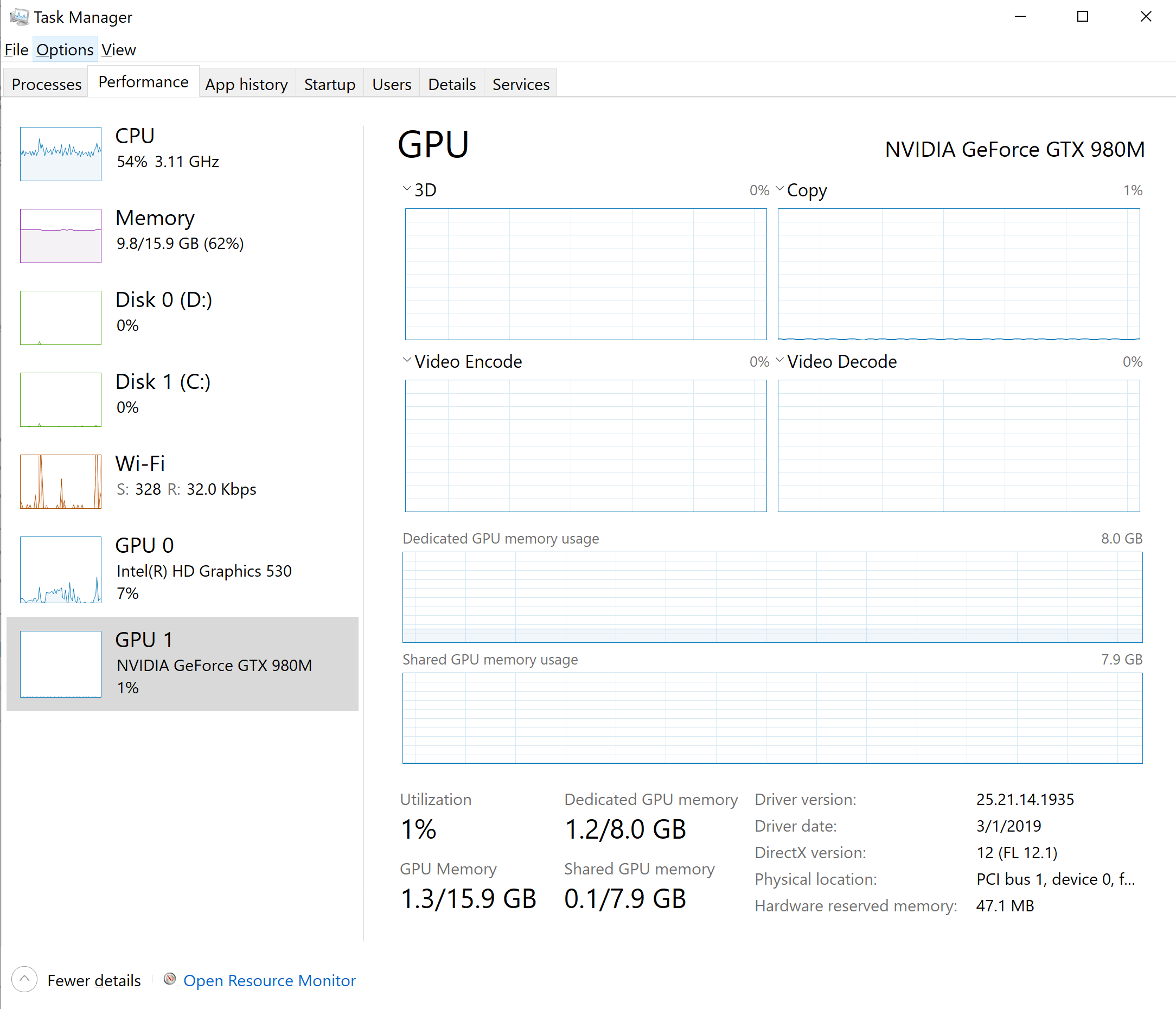
running nvidia-smi also shows that there is no GPU memory usage, and the following message:
Process ID : 19792
Type : C
Name : C:\Users\itaim\AppData\Local\Programs\Python\Python36\python.exe
Used GPU Memory : Not available in WDDM driver model
attaching task manager screenshot and nviidia-smi output:
nvidia-smi -l
C:\Users\itaim>nvidia-smi -l
±----------------------------------------------------------------------------+
| NVIDIA-SMI 419.35 Driver Version: 419.35 CUDA Version: 10.1 |
|-------------------------------±---------------------±---------------------+
| GPU Name TCC/WDDM | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 GeForce GTX 980M WDDM | 00000000:01:00.0 Off | N/A |
| N/A 66C P0 69W / N/A | 917MiB / 8192MiB | 51% Default |
±------------------------------±---------------------±---------------------+
±----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| 0 19792 C …cal\Programs\Python\Python36\python.exe N/A |
±----------------------------------------------------------------------------+
nvidia-smi -q
C:\Users\itaim>nvidia-smi -q
==============NVSMI LOG==============
Timestamp : Wed Mar 27 01:09:08 2019
Driver Version : 419.35
CUDA Version : 10.1
Attached GPUs : 1
GPU 00000000:01:00.0
Product Name : GeForce GTX 980M
Product Brand : GeForce
Display Mode : Disabled
Display Active : Disabled
Persistence Mode : N/A
Accounting Mode : Disabled
Accounting Mode Buffer Size : 4000
Driver Model
Current : WDDM
Pending : WDDM
Serial Number : N/A
GPU UUID : GPU-544e0a63-680d-08ca-c2da-1ef57adb2fff
Minor Number : N/A
VBIOS Version : 84.04.87.00.08
MultiGPU Board : No
Board ID : 0x100
GPU Part Number : N/A
Inforom Version
Image Version : N/A
OEM Object : N/A
ECC Object : N/A
Power Management Object : N/A
GPU Operation Mode
Current : N/A
Pending : N/A
GPU Virtualization Mode
Virtualization mode : None
IBMNPU
Relaxed Ordering Mode : N/A
PCI
Bus : 0x01
Device : 0x00
Domain : 0x0000
Device Id : 0x13D710DE
Bus Id : 00000000:01:00.0
Sub System Id : 0x07081028
GPU Link Info
PCIe Generation
Max : 3
Current : 3
Link Width
Max : 16x
Current : 8x
Bridge Chip
Type : N/A
Firmware : N/A
Replays Since Reset : 0
Replay Number Rollovers : 0
Tx Throughput : 59000 KB/s
Rx Throughput : 26000 KB/s
Fan Speed : N/A
Performance State : P0
Clocks Throttle Reasons
Idle : Not Active
Applications Clocks Setting : Not Active
SW Power Cap : Not Active
HW Slowdown : Not Active
HW Thermal Slowdown : N/A
HW Power Brake Slowdown : N/A
Sync Boost : Not Active
SW Thermal Slowdown : Not Active
Display Clock Setting : Not Active
FB Memory Usage
Total : 8192 MiB
Used : 827 MiB
Free : 7365 MiB
BAR1 Memory Usage
Total : 256 MiB
Used : 229 MiB
Free : 27 MiB
Compute Mode : Default
Utilization
Gpu : 39 %
Memory : 25 %
Encoder : 0 %
Decoder : 0 %
Encoder Stats
Active Sessions : 0
Average FPS : 0
Average Latency : 0
FBC Stats
Active Sessions : 0
Average FPS : 0
Average Latency : 0
Ecc Mode
Current : N/A
Pending : N/A
ECC Errors
Volatile
Single Bit
Device Memory : N/A
Register File : N/A
L1 Cache : N/A
L2 Cache : N/A
Texture Memory : N/A
Texture Shared : N/A
CBU : N/A
Total : N/A
Double Bit
Device Memory : N/A
Register File : N/A
L1 Cache : N/A
L2 Cache : N/A
Texture Memory : N/A
Texture Shared : N/A
CBU : N/A
Total : N/A
Aggregate
Single Bit
Device Memory : N/A
Register File : N/A
L1 Cache : N/A
L2 Cache : N/A
Texture Memory : N/A
Texture Shared : N/A
CBU : N/A
Total : N/A
Double Bit
Device Memory : N/A
Register File : N/A
L1 Cache : N/A
L2 Cache : N/A
Texture Memory : N/A
Texture Shared : N/A
CBU : N/A
Total : N/A
Retired Pages
Single Bit ECC : N/A
Double Bit ECC : N/A
Pending : N/A
Temperature
GPU Current Temp : 66 C
GPU Shutdown Temp : 96 C
GPU Slowdown Temp : 91 C
GPU Max Operating Temp : 101 C
Memory Current Temp : N/A
Memory Max Operating Temp : N/A
Power Readings
Power Management : N/A
Power Draw : 41.15 W
Power Limit : N/A
Default Power Limit : N/A
Enforced Power Limit : N/A
Min Power Limit : N/A
Max Power Limit : N/A
Clocks
Graphics : 1126 MHz
SM : 1126 MHz
Memory : 2505 MHz
Video : 1036 MHz
Applications Clocks
Graphics : 1038 MHz
Memory : 2505 MHz
Default Applications Clocks
Graphics : 1038 MHz
Memory : 2505 MHz
Max Clocks
Graphics : 1126 MHz
SM : 1126 MHz
Memory : 2505 MHz
Video : 1036 MHz
Max Customer Boost Clocks
Graphics : N/A
Clock Policy
Auto Boost : N/A
Auto Boost Default : N/A
Processes
Process ID : 20840
Type : C
Name : C:\Users\itaim\AppData\Local\Programs\Python\Python36\python.exe
Used GPU Memory : Not available in WDDM driver model
and my code:
import torch
import torchvision
import torch.nn as nn
import torch.nn.functional as F
from torchvision import transforms, datasets, models
from torch.utils.data import Dataset, DataLoader
from torch.autograd import Variable
import torch.optim as optim
from torch.optim import lr_scheduler
from torch.utils.data.sampler import SubsetRandomSampler
import torch.backends.cudnn as cudnn
import matplotlib.pyplot as plt
import numpy as np
import torch.optim as optim
import pandas as pd
import os
from PIL import Image
import pickle
import urllib
from urllib.request import urlopen
import time
import copy
device = torch.device(“cuda:0” if torch.cuda.is_available() else “cpu”)
print(“torch.cuda.is_available() =”, torch.cuda.is_available())
print(“torch.cuda.device_count() =”, torch.cuda.device_count())
print(“torch.cuda.device(‘cuda’) =”, torch.cuda.device(‘cuda’))
print(“torch.cuda.current_device() =”, torch.cuda.current_device())
print(“torch.cuda.get_device_name(0) =”,torch.cuda.get_device_name(0))
cudnn.benchmark = True
#Additional Info when using cuda
if device.type == ‘cuda’:
print(torch.cuda.get_device_name(0))
print(‘Memory Usage:’)
print(‘Allocated:’, round(torch.cuda.memory_allocated(0)/10243,1), ‘GB’)
print('Cached: ', round(torch.cuda.memory_cached(0)/10243,1), ‘GB’)
class DogsTrainingDataset(Dataset):
def __init__(self,text_file,root_dir):
"""
Args:
text_file(string): path to text file
root_dir(string): directory with all train images
"""
self.name_frame = pd.read_csv(text_file,sep=",",usecols=range(1))
self.label_frame = pd.read_csv(text_file,sep=",",usecols=range(1,2))
self.label_idx_frame = pd.read_csv(text_file,sep=",",usecols=range(2,3))
self.root_dir = root_dir
self.transform = transforms.Compose([
transforms.Resize(224),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize( mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
def __len__(self):
return len(self.name_frame)
def __getitem__(self, idx):
img_name = os.path.join(self.root_dir, self.name_frame.iloc[idx, 0]) + '.jpg'
label_str = self.label_frame.iloc[idx, 0]
label = self.label_idx_frame.iloc[idx, 0]
image = Image.open(img_name)
image = self.transform(image)
#labels = labels.reshape(-1, 2)
return [image, label, label_str]
def imshow(img, title=None):
inp = img.numpy().transpose((1, 2, 0))
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
inp = std * inp + mean
inp = np.clip(inp, 0, 1)
plt.imshow(inp)
if title is not None:
plt.title(title)
plt.pause(0.001) # pause a bit so that plots are updated
def train_model(model, criterion, optimizer, scheduler, validation_split, dataloaders, num_epochs=25):
since = time.time()
best_model_wts = copy.deepcopy(model.state_dict())
best_acc = 0.0
best_epoch_idx = 0
train_loss = []
train_acc = []
val_loss = []
val_acc = []
val_size = np.floor(len(dataloaders['train'].dataset) * validation_split)
train_size = len(dataloaders['train'].dataset) - val_size
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
print('-' * 10)
# Each epoch has a training and validation phase
for phase in ['train', 'val']:
if phase == 'train':
dataset_size = train_size
scheduler.step()
model.train() # Set model to training mode
else:
dataset_size = val_size
model.eval() # Set model to evaluate mode
running_loss = 0.0
running_corrects = 0
# Iterate over data.
for inputs, labels, labels_str in dataloaders[phase]:
inputs = inputs.to(device)
labels = labels.to(device)
# zero the parameter gradients
optimizer.zero_grad()
# forward
# track history if only in train
with torch.set_grad_enabled(phase == 'train'):
#if(phase == 'train'):
# outputs,aux = model(inputs)
#else:
# outputs = model(inputs)
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
# backward + optimize only if in training phase
if phase == 'train':
loss.backward()
optimizer.step()
# statistics
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
epoch_loss = running_loss / dataset_size
epoch_acc = running_corrects.double() / dataset_size
print('{} Loss: {:.4f} Acc: {:.4f}'.format(
phase, epoch_loss, epoch_acc))
# save loss and accuracy
if phase == 'train':
train_loss.append(epoch_loss)
train_acc.append(epoch_acc)
else:
val_loss.append(epoch_loss)
val_acc.append(epoch_acc)
# deep copy the model
if phase == 'val' and epoch_acc > best_acc:
best_acc = epoch_acc
best_epoch_idx = epoch
best_model_wts = copy.deepcopy(model.state_dict())
time_elapsed = time.time() - since
print('Training complete in {:.0f}m {:.0f}s'.format(
time_elapsed // 60, time_elapsed % 60))
print('Best val Acc: {:4f}'.format(best_acc))
# plot loss and accuracy
plt.figure()
plt.xlabel('# of epochs')
plt.title('Accuracy')
plt.plot(range(num_epochs), train_acc, label='Train Accuracy')
plt.plot(range(num_epochs), val_acc, label='Validation Accuracy')
plt.legend()
plt.figure()
plt.xlabel('# of epochs')
plt.title('Loss')
plt.plot(range(num_epochs), train_loss, label='Train Loss')
plt.plot(range(num_epochs), val_loss, label='Validation Loss')
plt.legend()
print('best epoch index:',best_epoch_idx)
# load best model weights
model.load_state_dict(best_model_wts)
return model
dogsTrainSet = DogsTrainingDataset(text_file =‘C:\Users\itaim\Master\TeamLily\labels.csv’,
root_dir = ‘C:\Users\itaim\Master\TeamLily\train’)
num_epochs = 10
batch_size = 16
validation_split = .2
shuffle_dataset = True
random_seed= 42
Creating data indices for training and validation splits:
dataset_size = len(dogsTrainSet)
indices = list(range(dataset_size))
split = int(np.floor(validation_split * dataset_size))
if shuffle_dataset :
np.random.seed(random_seed)
np.random.shuffle(indices)
train_indices, val_indices = indices[split:], indices[:split]
Creating PT data samplers and loaders:
train_sampler = SubsetRandomSampler(train_indices)
val_sampler = SubsetRandomSampler(val_indices)
handle data loaders
dogsTrainLoader = DataLoader(dogsTrainSet, batch_size=16, sampler=train_sampler, pin_memory=True)
dogsValLoader = DataLoader(dogsTrainSet, batch_size=16, sampler=val_sampler, pin_memory=True)
dataloaders = {‘train’: dogsTrainLoader , ‘val’: dogsValLoader}
init model and its attributes
model = models.resnet50(pretrained=True)
#model.aux_logit=False
option 1 - use the model as feature extractor (train only classifier)
for param in model.parameters():
param.requires_grad = False
num_ftrs = model.fc.in_features
model.fc = nn.Linear(num_ftrs, 120)
model = model.to(device)
criterion = nn.CrossEntropyLoss()
choose SG with momentum
optimizer = optim.SGD(model.fc.parameters(), lr=0.001, momentum=0.9)
Decay LR by a factor of 0.1 every 7 epochs
exp_lr_scheduler = lr_scheduler.StepLR(optimizer, step_size=7, gamma=0.1)
train the model and evaluate on the validation set
print(‘#########################################’)
print(‘running with SGD’)
print(‘#########################################’)
model_trained1 = train_model(model, criterion, optimizer,
exp_lr_scheduler, validation_split, dataloaders, num_epochs=25)
print(‘#########################################’)
print(‘running with Adam’)
print(‘#########################################’)
optimizer = optim.Adam(model.fc.parameters(), lr=0.001, betas=(0.9, 0.999), eps=1e-08, weight_decay=0, amsgrad=False)
exp_lr_scheduler = lr_scheduler.StepLR(optimizer, step_size=7, gamma=0.1)
model_trained2 = train_model(model, criterion, optimizer,
exp_lr_scheduler, validation_split, dataloaders, num_epochs=25)
any suggestions?
Thanks in advance ![]()