Hi!
I have trained a Resnet20 model and record the train and test losses epoch per epoch. Here is the plot
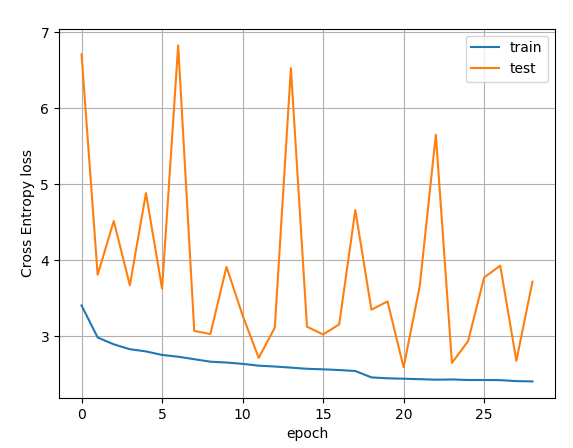
The fact that the test loss has a hieratic behaviour is an other subject (see Resnet: problem with test loss for details).
Schematically, during the training phase of the model, after all the dataloading, minimzer/scheduler init, for each epoch:
for epoch in range(start_epoch, args.epochs + 1):
train_loss = train(args, model, device, train_loader, train_transforms, optimizer, epoch)
test_loss = test(args, model, device, test_loader, test_transforms)
# save model ...
state = {
'epoch': epoch + 1,
'model_state_dict': model.state_dict(),
'scheduler_state_dict': scheduler.state_dict(),
'optimizer_state_dict': optimizer.state_dict()
}
torch.save(state,"model.pth")
In the train() function:
def train(args, model, device, train_loader, transforms, optimizer, epoch, attack=None, **attack_args):
# switch network layers to Training mode
model.train()
train_loss = 0 # to get the mean loss over the dataset (JEC 15/11/19)
# scans the batches
for i_batch, sample_batched in enumerate(train_loader):
img_batch = sample_batched['image'] #input image
ebv_batch = sample_batched['ebv'] #input redenning
z_batch = sample_batched['z'] #target
new_img_batch = torch.zeros_like(img_batch).permute(0, 3, 1, 2)
#for CrossEntropyLoss no hot-vector
new_z_batch = torch.zeros(batch_size,dtype=torch.long)
for i in range(batch_size):
# transform the images
img = img_batch[i].numpy()
for it in range(transf_size):
img = transforms[it](img)
new_img_batch[i] = img
# transform the redshift in bin number
z = (z_batch[i] - z_min) / (z_max - z_min) # z \in 0..1 => z est reel
z = max(0, min(n_bins - 1, int(z * n_bins))) # z \in {0,1,.., n_bins-1} => z est entier
new_z_batch[i] = z
# send the inputs and target to the device
new_img_batch, ebv_batch, new_z_batch = new_img_batch.to(device), \
ebv_batch.to(device), \
new_z_batch.to(device)
# reset the gradiants
optimizer.zero_grad()
# Feedforward
output = model(new_img_batch, ebv_batch)
# the loss
loss = F.cross_entropy(output,new_z_batch)
train_loss += loss.item() * batch_size
# backprop to compute the gradients
loss.backward()
# perform an optimizer step to modify the weights
optimizer.step()
# return some stat
return train_loss/len(train_loader.dataset)
For the test() function it is essentially the same code but with
model.eval()switch and- the use of
with torch.no_grad():which is above the loop on the batches
Now, I have setup an other program for debugging. The philosophy is the following, once the last “model.pth” checkpoint is loaded
- use the same training and testing samples used for the training job described above, and also use the same random seeds init, the same data augmentation schema also
- use in place of the train/test function, a single process function which sets the model.eval() and the
with torch.no_grad():and then loops on the batches to computes the mean losses
So, I would have expected that the model parameters (notzbly the Batch Norm param stats) would be frozen, such that I would recover the test and train losses values but, this is not the case:
Train mean loss over 781 samples = 4.95804432992288
Test mean loss over 781 samples = 4.958497584095075
Have you an idea for instance why the loss computed with the same training set used during the training job is around 5 while it was around 2.5 !!!
Does the model saved at each epoch after a train followed by a test, has lost the BatchNorm parameters and so after reloading the model the two sets are recongnized as fresh sets ???
