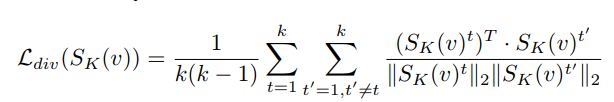pcshih
July 26, 2019, 3:20am
1
Is this function differentiable?
Is there any implementation code behind this function? I cannot find the source code of this function in the pytorch website.
I have implemented a paper
Other Question:
In this paper section 3.3
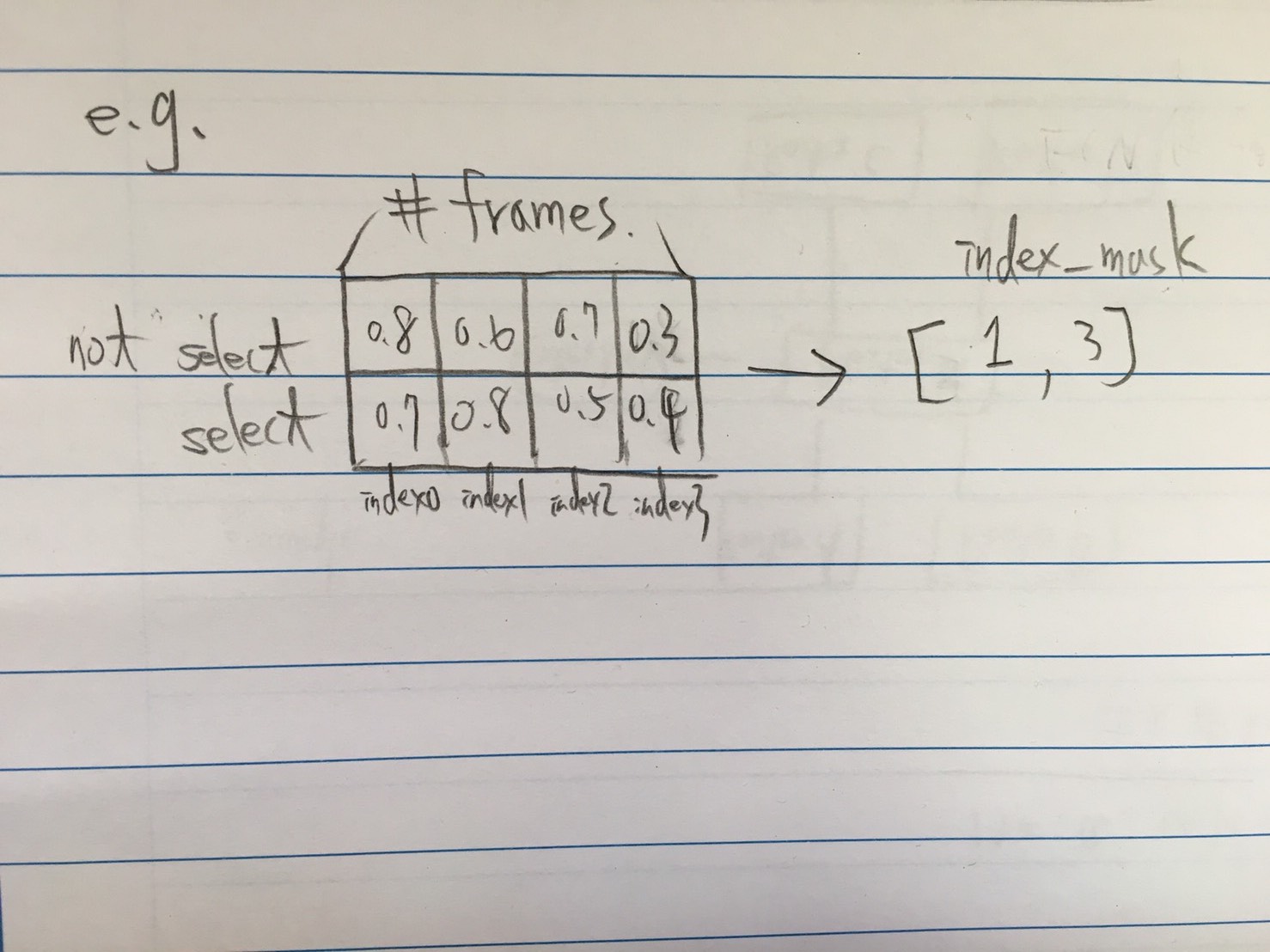
We first select Y frames (i.e. keyframes) based on the prediction scores from the
The decoder output is [2,320], which means non-keyframe score and key frame score of the 320 frames. We want to find a 0/1 vector according to the decoder output but the process of [2,320] → 0/1 vector seems not differentiable…
How to implement this in pytorch?
Thanks for anyone pointing out the reason.
Tony-Y
July 26, 2019, 7:41am
2
I have found its source code.
CPU:
void THTensor_(indexSelect)(THTensor *tensor, THTensor *src, int dim, THLongTensor *index)
{
ptrdiff_t i, numel;
THTensor *tSlice, *sSlice;
int64_t *index_data;
CUDA:
void THCTensor_(indexSelect)(THCState *state, THCTensor *dst, THCTensor *src, int dim, THCudaLongTensor *indices)
{
THCAssertSameGPU(THCTensor_(checkGPU)(state, 3, dst, src, indices));
int dims = THCTensor_(nDimensionLegacyNoScalars)(state, dst);
THArgCheck(dims <= MAX_CUTORCH_DIMS, 2, CUTORCH_DIM_WARNING);
pcshih
July 26, 2019, 8:22am
3
Thank you Tony-Y.
Tony-Y
July 26, 2019, 8:31am
4
- name: index_select(Tensor self, int dim, Tensor index) -> Tensor
self: at::zeros(self.sizes(), grad.options()).index_add_(dim, index, grad)
index: non_differentiable
It is non-differentiable with respect to index.
pcshih
July 26, 2019, 8:54am
5
Thank you very much, Tony-Y.
What do you think of the pytorch implementation of the “select” action in “we select k key frames to form the predicted summary video” ?
I use torch.index_select first but I know the function cannot be differentiable now.
Tony-Y
July 26, 2019, 12:15pm
6
You use index_select 4 times in your code:
index = torch.tensor(column_mask, device=torch.device('cuda:0'))
h_select = torch.index_select(h, 3, index)
x_select = torch.index_select(x_temp, 3, index)
gt_summary = torch.from_numpy(dataset[key]["gtsummary"][...]).to(device)
column_index = gt_summary.nonzero().view(-1)
feature_summary_cuda = torch.from_numpy(dataset[key]["features"][...]).to(device)
feature_summary_cuda = feature_summary_cuda.transpose(1,0).view(1,1024,1,feature_summary_cuda.shape[0])
feature_summary_cuda = torch.index_select(feature_summary_cuda, 3, column_index)
attributes["summary_features"] = feature_summary_cuda; #print(torch.isnan(feature_summary_cuda).nonzero().view(-1))
index = torch.tensor(column_mask, device=device)
select_vd = torch.index_select(vd, 3, index)
reconstruct_loss = torch.norm(S_K_summary-select_vd, p=2)**2
reconstruct_loss /= len(column_mask)
Where is the problem?
pcshih
July 26, 2019, 12:28pm
7
Thank you very much, Tony-Y.
The index_select function cannot be diff. so the gradient cannot backprop. to the previous S_K architecture.
My problem is how do I implement “select” action in pytorch instead of using the index_select function to implement it?
Tony-Y
July 26, 2019, 11:05pm
8
Do you want a derivative with respect to the index rather than the source tensor?
pcshih
July 27, 2019, 2:19am
9
I want a derivative with respect to the source tensor[index] → the tensor on the “index” location.
Because the output tensor of FCSN architecture is in the shape of [1,2,1,#frame ]. This tensor means whether frames are selected or not.
The algo. of this paper is below:
Downsampling every video in 2fps and pre-processing every downsampled training video to [1,1024, 1, T] (video) and [1,1024,1,S] (summary) through pre-trained googlenet.
for every pre-processed downsample video’s feature(in the format [1,1024,1,T]) and real summary video’s feature(in the format [1,1024,1,S]): ->T,S may differ in each video
Put [1,1024,1,T] into FCSN and get the index_mask(this index_mask is constructed from the output of FCSN [1,2,1,T] which means which frame should be selected)
Select K key outputs of FCSN according to index_mask and get the output in format [1,2,1,K].
Put the selected K key outputs of FCSN([1,2,1,K]) into the 1x1 conv to get the [1,1024,1,K].
Add K key features[1,1024,1,K] (Pick the K key features from original video feature according to index_mask) to the 1x1 conv output[1,1024,1,K] to do skip connection(this is the output of S_K).
Pick the K key features from original video feature according to index_mask and calculate the reconstruction loss with previous step output.
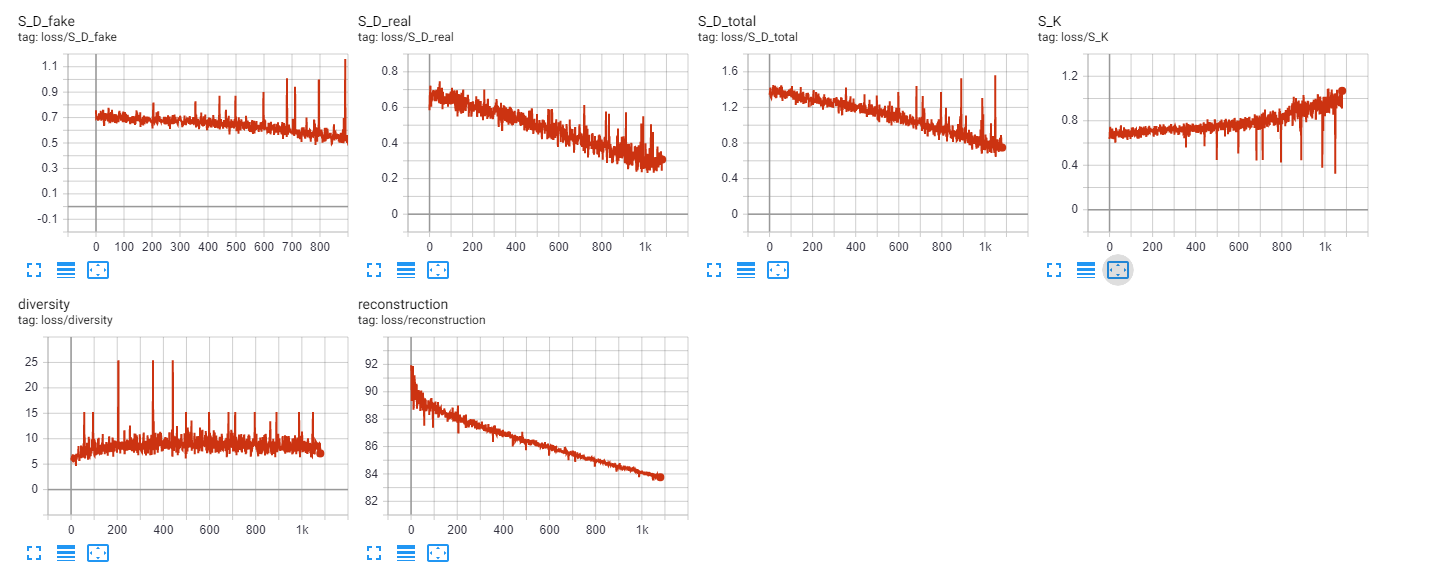
Calculate the diversity loss.
Calculate the adv. loss by putting the output of S_K in to S_D and set target score 1 to get the adv. loss
Put Real summary videos’ features [1,1024,1,S] into S_D to calculate and set target score 1 to get the adv. loss.
Put Fake summary videos’ features [1,1024,1,K] come from S_K in S_D to calculate and set target score 0 to get adv. loss.
end
Thank you very much, Tony-Y.
Tony-Y
July 27, 2019, 3:45am
10
This reconstruction loss can be calculated by the weighted mean where the index_mask is used as the weights and k is the sum of the index_mask.
pcshih
July 27, 2019, 4:22am
11
But the the frame with larger index will get more weight, am I right?
Tony-Y
July 27, 2019, 4:35am
12
Since index_select is not used, the frame numbers of SK and v are the same.
pcshih
July 27, 2019, 4:42am
13
Sorry for my poor English understanding.
Could you please set an example?
Thank you very much, Tony-Y.
Tony-Y
July 27, 2019, 4:56am
14
import torch
index_mask = torch.Tensor([0.0, 0.0, 1.0, 1.0, 0.0])
v = torch.randn(3,5)
sk = torch.randn(3,5)
torch.sum((sk-v)**2 * index_mask) / torch.sum(index_mask)
where the feature size is 3 and the number of frames is 5.
pcshih
July 27, 2019, 6:46am
15
I have followed your idea but the loss is the same quite weird.
h = x
x_temp = x
h = self.FCSN(h)
values, indices = h.max(1, keepdim=True)
###old###
# # 0/1 vector, we only want key(indices=1) frame
# column_mask = (indices==1).view(-1).nonzero().view(-1).tolist()
# # if S_K doesn't select more than one element, then random select two element(for the sake of diversity loss)
# if len(column_mask)<2:
# print("S_K does not select anything, give a random mask with 2 elements")
# column_mask = random.sample(list(range(h.shape[3])), 2)
# index = torch.tensor(column_mask, device=torch.device('cuda:0'))
# h_select = torch.index_select(h, 3, index)
# x_select = torch.index_select(x_temp, 3, index)
###old###
show original
###new reconstruct###
reconstruct_loss = torch.sum((S_K_summary-vd)**2 * index_mask) / torch.sum(index_mask)
###new reconstruct###
# diversity
S_K_summary_reshape = S_K_summary.view(S_K_summary.shape[1], S_K_summary.shape[3])
norm_div = torch.norm(S_K_summary_reshape, 2, 0, True)
S_K_summary_reshape = S_K_summary_reshape/norm_div
loss_matrix = S_K_summary_reshape.transpose(1, 0).mm(S_K_summary_reshape)
diversity_loss = loss_matrix.sum() - loss_matrix.trace()
#diversity_loss = diversity_loss/len(column_mask)/(len(column_mask)-1)
diversity_loss = diversity_loss/(torch.sum(index_mask))/(torch.sum(index_mask)-1)
p.s. The torch.index_select in below is just for training set preparation so I do not change.
gt_summary = torch.from_numpy(dataset[key]["gtsummary"][...]).to(device)
column_index = gt_summary.nonzero().view(-1)
feature_summary_cuda = torch.from_numpy(dataset[key]["features"][...]).to(device)
feature_summary_cuda = feature_summary_cuda.transpose(1,0).view(1,1024,1,feature_summary_cuda.shape[0])
feature_summary_cuda = torch.index_select(feature_summary_cuda, 3, column_index)
attributes["summary_features"] = feature_summary_cuda; #print(torch.isnan(feature_summary_cuda).nonzero().view(-1))
Thank you very much, Tony-Y.
Tony-Y
July 27, 2019, 6:59am
16
By the way, is the random selection a valid approach?
pcshih
July 27, 2019, 7:13am
17
The selection is based on the output of the FCSN architecture (i.e. [1,1024,1,T] tensor)
Thank you very much, Tony-Y.
pcshih
July 27, 2019, 7:30am
19
Because the calculation of diversity loss must have at least two frames.
pcshih
July 27, 2019, 7:30am
20
I implement the diversity loss through below concept, where the feature size is 2 and the number of frames is 3.