Hello,
Since the new CUDA 12 is out, was wondering if PyTorch is compatible with the newest CUDA version or should I install the 11.8.
Thank you
Hello,
Since the new CUDA 12 is out, was wondering if PyTorch is compatible with the newest CUDA version or should I install the 11.8.
Thank you
You should be able to build PyTorch from source using CUDA 12.0, but the binaries are not ready yet (and the nightlies with CUDA 11.8 were just added ~2 weeks ago).
If you decide to build from source, note that a few fixes still need to land which are tracked here.
Hi
still, PyTorch doesn’t work with cuda12, and even downgraded the cuda it is not working too.
my driver version is 525. how can I deal with that?
I appreciate your help
PyTorch does work with CUDA 12 and we are already supporting it via the NGC containers.
You would need to post more information about issues you are seeing.
RuntimeError: CUDA error: no kernel image is available for execution on the device
CUDA kernel errors might be asynchronously reported at some other API call,so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
my graphic card is RTX 3080 16 GB
This error is raised if your build wasn’t compiled for the right GPU architecture (sm_86 in your case).
Check what torch.cuda.get_arch_list() returns and also check your build logs to see which compute capability was selected.
i’ve checked the architectures list and i got the following output
[‘sm_37’, ‘sm_50’, ‘sm_60’, ‘sm_70’]
In case you’ve build PyTorch from source, use TORCH_CUDA_ARCH_LIST=8.6 python setup.py install to build for compute capability 8.6.
i did what you mentioned above i’ve cloned pytroch and then I modified the setup file to add the line specifying the architecture then i ran the python setup.py install in a conda environment with python 3.6 but i faced the same error.
RuntimeError: CUDA error: no kernel image is available for execution on the device
CUDA kernel errors might be asynchronously reported at some other API call,so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
I appreciate your help
Your install log should show if the environment variable was properly detected or not.
Also, you don’t need to modify anything in the setup.py script and could execute my posted command as it is.
If you are still having trouble building from source, you could use the 11.8 binaries (which support your GPU), use the linked NGC container, or wait for the PyTorch binaries to support CUDA 12.
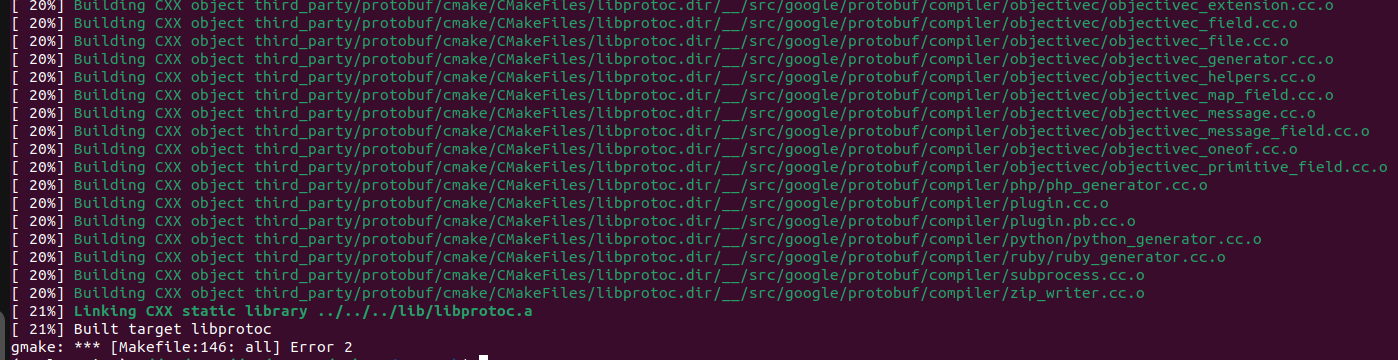
now I tried again to execute the command as it is and I think there’s an error at the end of the
It seems your build now fails to compile protobuf. Was this working before?
this is my first use of my computer, I just bought it that’s why I m trying to install all the framework. but everything was working perfectly on my previous computer because already has an older GPU and CUDA.
I’m also having an issue with CUDA 12 and PyTorch where I’m getting the following trace:
Traceback (most recent call last):
File “/home/barry/code/test.py”, line 5, in
import torchvision
File “/home/barry/miniconda3/envs/tf/lib/python3.9/site-packages/torchvision/init.py”, line 4, in
import torch
File “/home/barry/miniconda3/envs/tf/lib/python3.9/site-packages/torch/init.py”, line 229, in
from torch._C import * # noqa: F403
ImportError: libcusparse.so.11: cannot open shared object file: No such file or directory
I tried running ldconfig and I’m also seeing when running ldconfig -p | grep cuda , I see
libcusparse.so.12 (libc6,x86-64) => /usr/local/cuda/targets/x86_64-linux/lib/libcusparse.so.12
libcusparse.so (libc6,x86-64) => /usr/local/cuda/targets/x86_64-linux/lib/libcusparse.so
nvidia-smi shows NVIDIA-SMI 525.65 Driver Version: 527.37 CUDA Version: 12.0
Assuming you’ve built PyTorch from source using CUDA 12.x, since the binaries are not available yet, I would recommend to make sure no CUDA 11.x (math) library can be found.
I’m having related problems trying to build pytorch from source – I cloned the repo and followed the windows build from source directions – but it complains that it can’t find nvToolsExt
The location of nvToolsExt used to be installed to C:\Program Files\NVIDIA GPU Computing Toolkit\nvToolsExt but that seems to be no longet the case. I am currently opting to install everything that comes with the 12.1 Cuda Toolkit installer. I have also searched my entire computer for nvToolsExt but can’t seem to find that folder anywhere. Does it get installed somewhere else under a different name now? And if so does that mean it also will need to be set with the NVTOOLSEXT_PATH environment variable? Here is the error that occurs during the install script:
(diff3d) C:\Dev\pytorch>python setup.py install
Building wheel torch-2.1.0a0+git461f088
-- Building version 2.1.0a0+git461f088
cmake -GNinja -DBUILD_PYTHON=True -DBUILD_TEST=True -DCMAKE_BUILD_TYPE=Release -DCMAKE_INSTALL_PREFIX=C:\Dev\pytorch\torch -DCMAKE_PREFIX_PATH=C:\Users\Owner\mambaforge\envs\diff3d\Lib\site-packages -DJAVA_HOME=C:\Program Files\Android\Android Studio\jre -DNUMPY_INCLUDE_DIR=C:\Users\Owner\mambaforge\envs\diff3d\lib\site-packages\numpy\core\include -DPYTHON_EXECUTABLE=C:\Users\Owner\mambaforge\envs\diff3d\python.exe -DPYTHON_INCLUDE_DIR=C:\Users\Owner\mambaforge\envs\diff3d\Include -DPYTHON_LIBRARY=C:\Users\Owner\mambaforge\envs\diff3d/libs/python39.lib -DTORCH_BUILD_VERSION=2.1.0a0+git461f088 -DUSE_NUMPY=True C:\Dev\pytorch
CMake Warning at CMakeLists.txt:367 (message):
TensorPipe cannot be used on Windows. Set it to OFF
-- Current compiler supports avx2 extension. Will build perfkernels.
-- Current compiler supports avx512f extension. Will build fbgemm.
CMake Error at cmake/public/cuda.cmake:69 (message):
Failed to find nvToolsExt
Call Stack (most recent call first):
cmake/Dependencies.cmake:43 (include)
CMakeLists.txt:709 (include)
Hi @ptrblck I’ve solved the Cuda issue right now by using cuda12+pytorch2.0. however, I got another issue related to the optimizer scheduler, where I would like to use CYclicLR as a scheduler but I faced the following error could u please explain how I can solve it
raise ValueError(f’The provided lr scheduler “{scheduler}” is invalid’)
ValueError: The provided lr scheduler “<torch.optim.lr_scheduler.CyclicLR object at 0x7f7f6457f0a0>” is invalid
It seems the error is raised by Lightning from here and I don’t know why it’s raised as I’m not familiar enough with this lib.
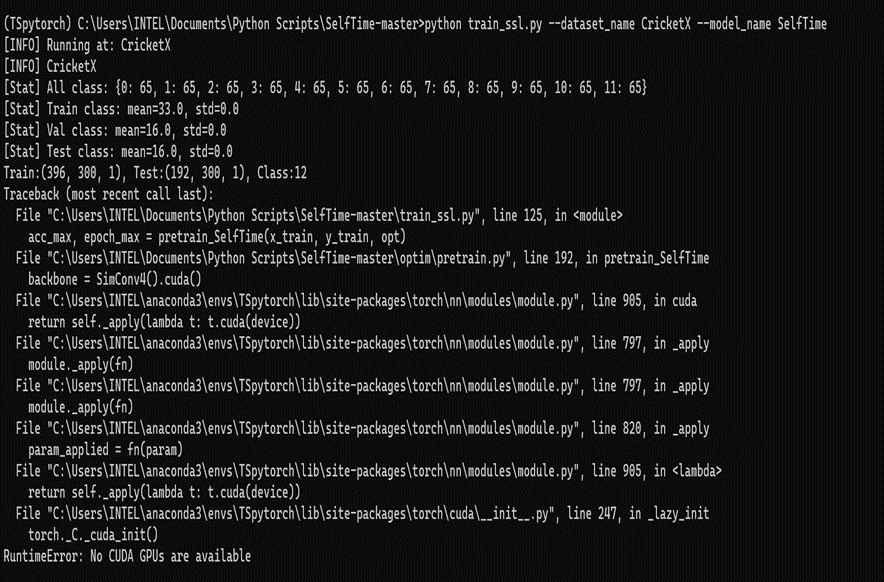
I am facing the following error while using pytorch with cuda 11.7 version. I installed the first Cuda toolkit 12.1 from Nvidia. but it throws a run time error: No Cuda GPUs are available. Then I installed cuda toolkit 11.7 and ran the code again I am facing the same error. How to clear this error?
Your locally installed CUDA toolkit won’t be used as the PyTorch binaries ship with their own CUDA dependencies unless you build PyTorch from source or a custom extension.
Check the output of python -m torch.utils.collect_env and make sure a PyTorch version with a CUDA runtime is installed.