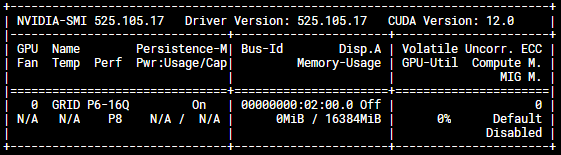
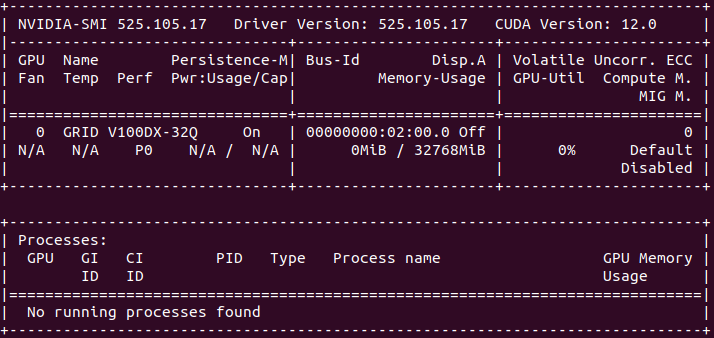
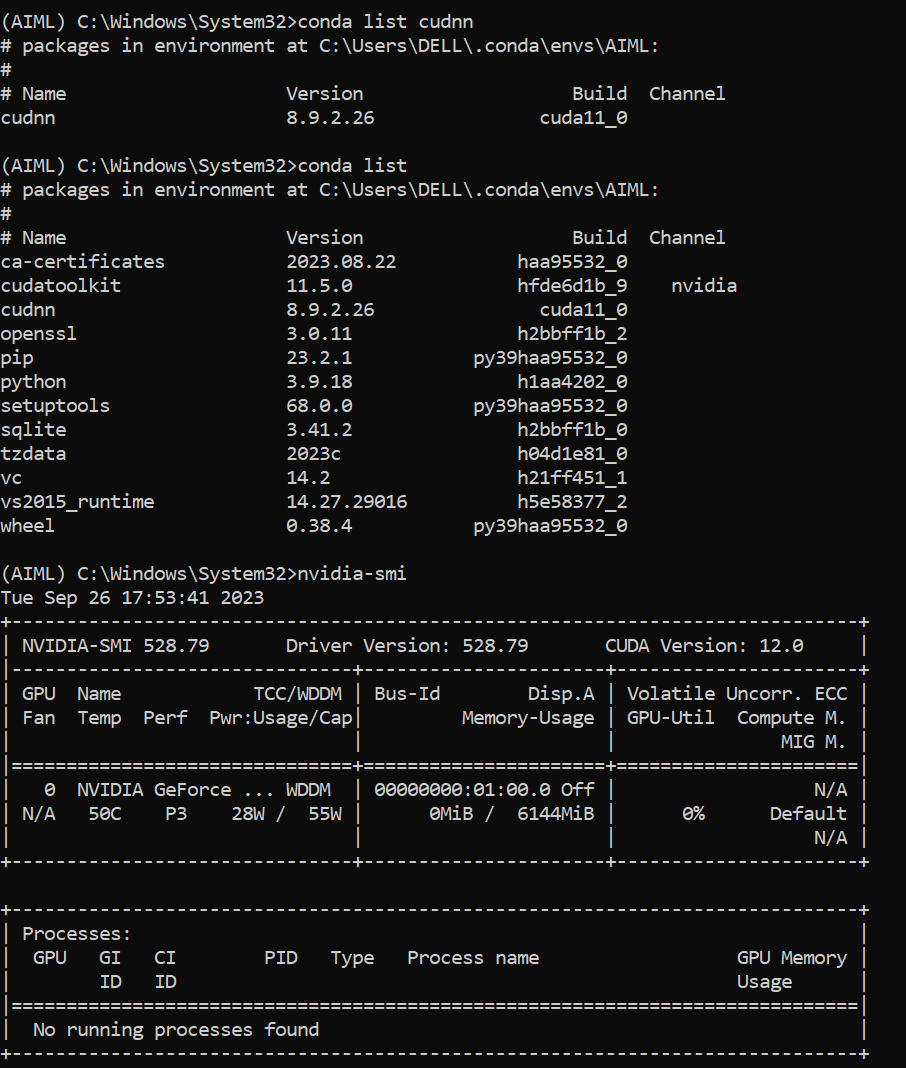
idont know how to fix this , i am using automatic1111
venv “D:\stable-diffusion-webui\venv\Scripts\Python.exe”
Python 3.10.6 (tags/v3.10.6:9c7b4bd, Aug 1 2022, 21:53:49) [MSC v.1932 64 bit (AMD64)]
Version: v1.6.0
Commit hash: 5ef669de080814067961f28357256e8fe27544f4
Launching Web UI with arguments:
no module ‘xformers’. Processing without…
no module ‘xformers’. Processing without…
No module ‘xformers’. Proceeding without it.
Loading weights [6ce0161689] from D:\stable-diffusion-webui\models\Stable-diffusion\v1-5-pruned-emaonly.safetensors
Running on local URL: http://127.0.0.1:7860
To create a public link, set share=True in launch().
Creating model from config: D:\stable-diffusion-webui\configs\v1-inference.yaml
Startup time: 5.4s (prepare environment: 1.3s, import torch: 1.7s, import gradio: 0.5s, setup paths: 0.4s, initialize shared: 0.2s, other imports: 0.3s, load scripts: 0.5s, create ui: 0.3s, gradio launch: 0.3s).
Applying attention optimization: Doggettx… done.
Model loaded in 7.0s (load weights from disk: 0.5s, create model: 0.3s, apply weights to model: 2.0s, apply half(): 1.0s, calculate empty prompt: 3.1s).
10%|████████▎ | 2/20 [00:00<00:08, 2.03it/s]Exception in thread MemMon:█▋ | 2/20 [00:00<00:01, 14.60it/s]
Traceback (most recent call last):
File “C:\Users\ryan\AppData\Local\Programs\Python\Python310\lib\threading.py”, line 1016, in _bootstrap_inner
*** Error completing request
*** Arguments: (‘task(93urvt8596sudh2)’, ‘help’, ‘’, , 20, ‘DPM++ 2M Karras’, 1, 1, 7, 512, 512, False, 0.7, 2, ‘Latent’, 0, 0, 0, ‘Use same checkpoint’, ‘Use same sampler’, ‘’, ‘’, , <gradio.routes.Request object at 0x00000168940C7C40>, 0, False, ‘’, 0.8, -1, False, -1, 0, 0, 0, False, False, ‘positive’, ‘comma’, 0, False, False, ‘’, 1, ‘’, , 0, ‘’, , 0, ‘’, , True, False, False, False, 0, False) {}
self.run()
Traceback (most recent call last):
File “D:\stable-diffusion-webui\modules\call_queue.py”, line 57, in f
res = list(func(*args, **kwargs))
File “D:\stable-diffusion-webui\modules\call_queue.py”, line 36, in f
res = func(*args, **kwargs)
File “D:\stable-diffusion-webui\modules\txt2img.py”, line 55, in txt2img
processed = processing.process_images(p)
File “D:\stable-diffusion-webui\modules\processing.py”, line 732, in process_images
res = process_images_inner(p)
File “D:\stable-diffusion-webui\modules\processing.py”, line 867, in process_images_inner
samples_ddim = p.sample(conditioning=p.c, unconditional_conditioning=p.uc, seeds=p.seeds, subseeds=p.subseeds, subseed_strength=p.subseed_strength, prompts=p.prompts)
File “D:\stable-diffusion-webui\modules\processing.py”, line 1140, in sample
samples = self.sampler.sample(self, x, conditioning, unconditional_conditioning, image_conditioning=self.txt2img_image_conditioning(x))
File “D:\stable-diffusion-webui\modules\sd_samplers_kdiffusion.py”, line 235, in sample
samples = self.launch_sampling(steps, lambda: self.func(self.model_wrap_cfg, x, extra_args=self.sampler_extra_args, disable=False, callback=self.callback_state, **extra_params_kwargs))
File “D:\stable-diffusion-webui\modules\sd_samplers_common.py”, line 261, in launch_sampling
return func()
File “D:\stable-diffusion-webui\modules\sd_samplers_kdiffusion.py”, line 235, in
samples = self.launch_sampling(steps, lambda: self.func(self.model_wrap_cfg, x, extra_args=self.sampler_extra_args, disable=False, callback=self.callback_state, **extra_params_kwargs))
File “D:\stable-diffusion-webui\venv\lib\site-packages\torch\utils_contextlib.py”, line 115, in decorate_context
return func(*args, **kwargs)
File “D:\stable-diffusion-webui\repositories\k-diffusion\k_diffusion\sampling.py”, line 594, in sample_dpmpp_2m
denoised = model(x, sigmas[i] * s_in, **extra_args)
File “D:\stable-diffusion-webui\venv\lib\site-packages\torch\nn\modules\module.py”, line 1501, in _call_impl
return forward_call(*args, **kwargs)
File “D:\stable-diffusion-webui\modules\sd_samplers_cfg_denoiser.py”, line 169, in forward
x_out = self.inner_model(x_in, sigma_in, cond=make_condition_dict(cond_in, image_cond_in))
File “D:\stable-diffusion-webui\venv\lib\site-packages\torch\nn\modules\module.py”, line 1501, in _call_impl
return forward_call(*args, **kwargs)
File “D:\stable-diffusion-webui\repositories\k-diffusion\k_diffusion\external.py”, line 112, in forward
eps = self.get_eps(input * c_in, self.sigma_to_t(sigma), **kwargs)
File “D:\stable-diffusion-webui\repositories\k-diffusion\k_diffusion\external.py”, line 138, in get_eps
return self.inner_model.apply_model(*args, **kwargs)
File “D:\stable-diffusion-webui\modules\sd_hijack_utils.py”, line 17, in
setattr(resolved_obj, func_path[-1], lambda *args, **kwargs: self(*args, **kwargs))
File “D:\stable-diffusion-webui\modules\sd_hijack_utils.py”, line 28, in call
return self.__orig_func(*args, **kwargs)
File “D:\stable-diffusion-webui\repositories\stable-diffusion-stability-ai\ldm\models\diffusion\ddpm.py”, line 858, in apply_model
x_recon = self.model(x_noisy, t, **cond)
File “D:\stable-diffusion-webui\venv\lib\site-packages\torch\nn\modules\module.py”, line 1501, in _call_impl
return forward_call(*args, **kwargs)
File “D:\stable-diffusion-webui\repositories\stable-diffusion-stability-ai\ldm\models\diffusion\ddpm.py”, line 1335, in forward
out = self.diffusion_model(x, t, context=cc)
File “D:\stable-diffusion-webui\venv\lib\site-packages\torch\nn\modules\module.py”, line 1501, in _call_impl
return forward_call(*args, **kwargs)
File “D:\stable-diffusion-webui\modules\sd_unet.py”, line 91, in UNetModel_forward
return ldm.modules.diffusionmodules.openaimodel.copy_of_UNetModel_forward_for_webui(self, x, timesteps, context, *args, **kwargs)
File “D:\stable-diffusion-webui\repositories\stable-diffusion-stability-ai\ldm\modules\diffusionmodules\openaimodel.py”, line 802, in forward
h = module(h, emb, context)
File “D:\stable-diffusion-webui\venv\lib\site-packages\torch\nn\modules\module.py”, line 1501, in _call_impl
return forward_call(*args, **kwargs)
File “D:\stable-diffusion-webui\repositories\stable-diffusion-stability-ai\ldm\modules\diffusionmodules\openaimodel.py”, line 84, in forward
x = layer(x, context)
File “D:\stable-diffusion-webui\venv\lib\site-packages\torch\nn\modules\module.py”, line 1501, in _call_impl
return forward_call(*args, **kwargs)
File “D:\stable-diffusion-webui\repositories\stable-diffusion-stability-ai\ldm\modules\attention.py”, line 327, in forward
x = self.norm(x)
File “D:\stable-diffusion-webui\venv\lib\site-packages\torch\nn\modules\module.py”, line 1501, in _call_impl
return forward_call(*args, **kwargs)
File “D:\stable-diffusion-webui\extensions-builtin\Lora\networks.py”, line 459, in network_GroupNorm_forward
return originals.GroupNorm_forward(self, input)
File “D:\stable-diffusion-webui\venv\lib\site-packages\torch\nn\modules\normalization.py”, line 273, in forward
return F.group_norm(
File “D:\stable-diffusion-webui\venv\lib\site-packages\torch\nn\functional.py”, line 2530, in group_norm
return torch.group_norm(input, num_groups, weight, bias, eps, torch.backends.cudnn.enabled)
RuntimeError: CUDA error: an illegal instruction was encountered
CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
Compile with TORCH_USE_CUDA_DSA to enable device-side assertions.
File “D:\stable-diffusion-webui\modules\memmon.py”, line 53, in run
free, total = self.cuda_mem_get_info()
File “D:\stable-diffusion-webui\modules\memmon.py”, line 34, in cuda_mem_get_info
return torch.cuda.mem_get_info(index)
Traceback (most recent call last):
File “D:\stable-diffusion-webui\venv\lib\site-packages\torch\cuda\memory.py”, line 618, in mem_get_info
File “D:\stable-diffusion-webui\venv\lib\site-packages\gradio\routes.py”, line 488, in run_predict
output = await app.get_blocks().process_api(
File “D:\stable-diffusion-webui\venv\lib\site-packages\gradio\blocks.py”, line 1431, in process_api
result = await self.call_function(
return torch.cuda.cudart().cudaMemGetInfo(device)
File “D:\stable-diffusion-webui\venv\lib\site-packages\gradio\blocks.py”, line 1103, in call_function
prediction = await anyio.to_thread.run_sync(
RuntimeError: CUDA error: an illegal instruction was encountered
CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
Compile with TORCH_USE_CUDA_DSA to enable device-side assertions.
File “D:\stable-diffusion-webui\venv\lib\site-packages\anyio\to_thread.py”, line 33, in run_sync
return await get_asynclib().run_sync_in_worker_thread(
File “D:\stable-diffusion-webui\venv\lib\site-packages\anyio_backends_asyncio.py”, line 877, in run_sync_in_worker_thread
return await future
File “D:\stable-diffusion-webui\venv\lib\site-packages\anyio_backends_asyncio.py”, line 807, in run
result = context.run(func, *args)
File “D:\stable-diffusion-webui\venv\lib\site-packages\gradio\utils.py”, line 707, in wrapper
response = f(*args, **kwargs)
File “D:\stable-diffusion-webui\modules\call_queue.py”, line 77, in f
devices.torch_gc()
File “D:\stable-diffusion-webui\modules\devices.py”, line 51, in torch_gc
torch.cuda.empty_cache()
File “D:\stable-diffusion-webui\venv\lib\site-packages\torch\cuda\memory.py”, line 133, in empty_cache
torch._C._cuda_emptyCache()
RuntimeError: CUDA error: an illegal instruction was encountered
CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
Compile with TORCH_USE_CUDA_DSA to enable device-side assertions.
*** Error completing request
*** Arguments: (‘task(yzh9m3b7twmyjef)’, ‘help’, ‘’, , 20, ‘DPM++ 2M Karras’, 1, 1, 7, 512, 512, False, 0.7, 2, ‘Latent’, 0, 0, 0, ‘Use same checkpoint’, ‘Use same sampler’, ‘’, ‘’, , <gradio.routes.Request object at 0x000001689376A5F0>, 0, False, ‘’, 0.8, -1, False, -1, 0, 0, 0, False, False, ‘positive’, ‘comma’, 0, False, False, ‘’, 1, ‘’, , 0, ‘’, , 0, ‘’, , True, False, False, False, 0, False) {}
Traceback (most recent call last):
File “D:\stable-diffusion-webui\modules\call_queue.py”, line 57, in f
res = list(func(*args, **kwargs))
File “D:\stable-diffusion-webui\modules\call_queue.py”, line 32, in f
shared.state.begin(job=id_task)
File “D:\stable-diffusion-webui\modules\shared_state.py”, line 119, in begin
devices.torch_gc()
File “D:\stable-diffusion-webui\modules\devices.py”, line 51, in torch_gc
torch.cuda.empty_cache()
File “D:\stable-diffusion-webui\venv\lib\site-packages\torch\cuda\memory.py”, line 133, in empty_cache
torch._C._cuda_emptyCache()
RuntimeError: CUDA error: an illegal instruction was encountered
CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
Compile with TORCH_USE_CUDA_DSA to enable device-side assertions.
Traceback (most recent call last):
File “D:\stable-diffusion-webui\venv\lib\site-packages\gradio\routes.py”, line 488, in run_predict
output = await app.get_blocks().process_api(
File “D:\stable-diffusion-webui\venv\lib\site-packages\gradio\blocks.py”, line 1431, in process_api
result = await self.call_function(
File “D:\stable-diffusion-webui\venv\lib\site-packages\gradio\blocks.py”, line 1103, in call_function
prediction = await anyio.to_thread.run_sync(
File “D:\stable-diffusion-webui\venv\lib\site-packages\anyio\to_thread.py”, line 33, in run_sync
return await get_asynclib().run_sync_in_worker_thread(
File “D:\stable-diffusion-webui\venv\lib\site-packages\anyio_backends_asyncio.py”, line 877, in run_sync_in_worker_thread
return await future
File “D:\stable-diffusion-webui\venv\lib\site-packages\anyio_backends_asyncio.py”, line 807, in run
result = context.run(func, *args)
File “D:\stable-diffusion-webui\venv\lib\site-packages\gradio\utils.py”, line 707, in wrapper
response = f(*args, **kwargs)
File “D:\stable-diffusion-webui\modules\call_queue.py”, line 77, in f
devices.torch_gc()
File “D:\stable-diffusion-webui\modules\devices.py”, line 51, in torch_gc
torch.cuda.empty_cache()
File “D:\stable-diffusion-webui\venv\lib\site-packages\torch\cuda\memory.py”, line 133, in empty_cache
torch._C._cuda_emptyCache()
RuntimeError: CUDA error: an illegal instruction was encountered
CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
Compile with TORCH_USE_CUDA_DSA to enable device-side assertions.