Hello,
I am trying to train a model on a Ubuntu 14.04 with a Nvidia 1080 ti, Cuda 8.0 and Pytorch 0.4. I have never been able to train an 200 epochs. The computer reboots after a random time from 1 to 90 epochs.
I have investigated the problem:
- It is not a PSU max power problem because the computer can run other programs (with pytorch 0.3) with its 4 GPUs
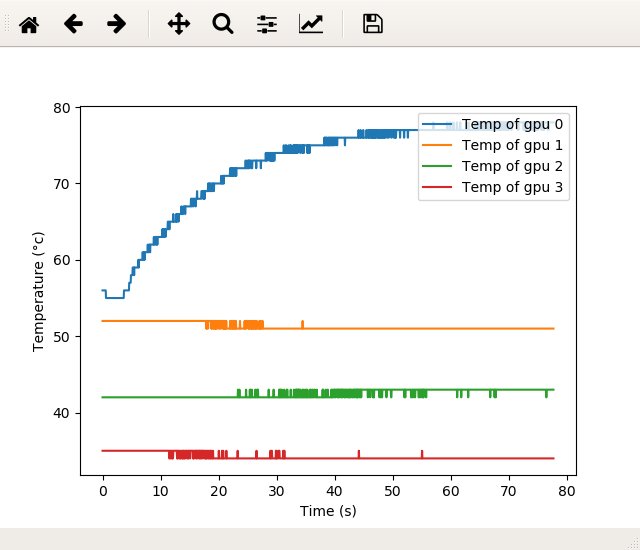
- Overheating: I have ran a script that monitor nvidia-smi every 0.05s and when the crash occurs, the temperature of the 4 GPUs is 78°, 51°, 43° and 34° and their power consumption is 90W, 13W, 11W and 9W (when training on GPU 0)
- I have also monitored the CPU and GPU memory utilization and everything is stable
- I have experienced the crash when training on GPU 0 and GPU 2 so it is not a specific hardware issue.
- Similar to Automatically reboot when set cudnn.benchmark to True I set cudnn.benchmark = False and still got the crash.
- I was able to complete the training multiple times on another computer with the same hardware (except a smaller PSU) and Ubuntu 16.04 and Cuda 9.1.
One possible explanation is the one of Reliably repeating pytorch system crash/reboot when using imagenet examples · Issue #3022 · pytorch/pytorch · GitHub large power variation causing crashes. I ran my program with a finer image resolution in order to have a constant 100% utilization of the GPU and I got a huge increase in power consumption (still with large power variation) but I experienced no crash. Since the crash appears after a random time up to 6 hours, maybe I have just not waited long enough.
Do you think this is the explanation ? The more Powerful PSU on this computer is in fact more sensible to power variations and shuts off. Do you think it is a software problem with Cuda 8 and pytorch 0.4 ?
Thank you for your help
EDIT: Add a plot the temperature for a training that crashed