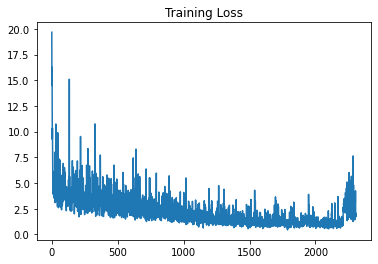
Hello,
So as the title states, I am having peaks in the loss when I resume training eventhough I am saving everything in the checkpoint : model state, optimizer state, and having a manual seed. like indicated below.
Dataloaders:
a function that returns the dataloaders at the start of my training program.
torch.manual_seed(1)
indices = torch.randperm(len(train_dataset)).tolist()
train_idx, valid_idx, test_idx = indices[val_size + test_size:], indices[:val_size], indices[
val_size:test_size + val_size]
train_sampler = SubsetRandomSampler(train_idx)
val_sampler = SubsetRandomSampler(valid_idx)
test_sampler = SubsetRandomSampler(test_idx)
train_loader = DataLoader(train_dataset, batch_size=batch_size, sampler=train_sampler,
pin_memory=torch.cuda.is_available(), num_workers=4)
val_loader = DataLoader(val_dataset, batch_size=batch_size, sampler=val_sampler,
pin_memory=torch.cuda.is_available(), num_workers=4)
test_loader = DataLoader(val_dataset, batch_size=batch_size, sampler=test_sampler,
pin_memory=torch.cuda.is_available(), num_workers=4)
Saving:
I save the checkpoint just after the training pass, and before doing validation or test, means the model is still model.train().
torch.save({
'epoch': e,
'model_state_dict': mymodel.state_dict(),
'best_loss': best_loss,
'optimizer_state_dict': optim.state_dict(),
}, os.path.join("Checkpoints", path, 'training_state.pt'))
Loading:
I check if there is a checkpoint at a given directory, and load it at the start of my training program.
starting_epoch = 0
best_loss = 100000
if os.path.exists(os.path.join("Checkpoints", path, 'training_state.pt')):
checkpoint = torch.load(os.path.join("Checkpoints", path, 'training_state.pt'), map_location=device)
mymodel.load_state_dict(checkpoint['model_state_dict'])
optim.load_state_dict(checkpoint['optimizer_state_dict'])
starting_epoch = checkpoint['epoch']
best_loss = checkpoint['best_loss']
Do you guys see anything that may cause peaks in the loss after resuming training ? it goes for example from 0.54 to 0.7 when resumed