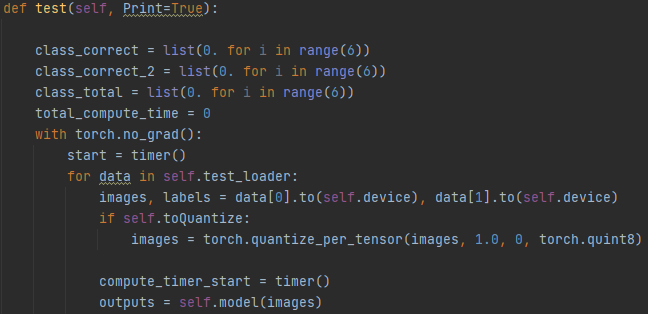
I am trying to run quantization on a model. The model I am using is the pretrained wide_resnet101_2. The code is running on CPU. Before quantization, the model is 510MB and after quantization it is down to 129MB. It seems like the quantization is working. The problem arises when the quantized model is called later in the code to run the tester.
The error is in the line 70: RuntimeError: Could not run ‘aten::add_.Tensor’ with arguments from the ‘QuantizedCPU’ backend. This could be because the operator doesn’t exist for this backend, or was omitted during the selective/custom build process (if using custom build). If you are a Facebook employee using PyTorch on mobile, please visit Internal Login for possible resolutions. ‘aten::add_.Tensor’ is only available for these backends: [CPU, MkldnnCPU, SparseCPU, Meta, BackendSelect, Named, AutogradOther, AutogradCPU, AutogradCUDA, AutogradXLA, AutogradNestedTensor, UNKNOWN_TENSOR_TYPE_ID, AutogradPrivateUse1, AutogradPrivateUse2, AutogradPrivateUse3, Tracer, Autocast, Batched, VmapMode].
This means the input of aten::add_ is a quantized Tensor. To address the problem you can either
(1). place a DequantStub and QuantStub around the aten::add_ op.
e.g.