Hi Ken_Jovan
could you find solution for your problem i faced the same thing. if possible could you share you experiences?
Hi Ken_Jovan
could you find solution for your problem i faced the same thing. if possible could you share you experiences?
I have encountered a similar problem with a multitask model for audio event detection task with trackwise output:
from numpy.core.fromnumeric import shape
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.nn.modules.container import Sequential
from methods.utils.model_utilities_transfer import (Transfer_Cnn14, PositionalEncoding, init_layer) #( CustomCNN, OrthogonalConv2d,PositionalEncoding, DoubleCNN, init_layer)
import torchaudio
from methods.utils.transfer_doa import(Transfer_Cnn14_d)
class EINV2(nn.Module):
def init(self, cfg, dataset):
super().init()
self.pe_enable = False # Ture | False
self.in_channels= 4
self.in_channels_doa = 7
freeze_base = False
if cfg[‘data’][‘audio_feature’] == ‘logmel&intensity’:
self.f_bins = cfg[‘data’][‘n_mels’]
# self.in_channels_doa = 7
# self.in_channels_sed = 4
self.downsample_ratio = 2 ** 2
self.sed = nn.Sequential(
Transfer_Cnn14(in_channels = 4, classes_num = 14, freeze_base = False), #nn.AvgPool2d(kernel_size=(2, 2)
nn.AvgPool2d(2, 2)
)
# self.sed = (Transfer_Cnn14(4, classes_num = 14, freeze_base = False),
# nn.AvgPool2d(kernel_size=(2, 2))
# )
self.doa= nn.Sequential(
Transfer_Cnn14_d(in_channels = 7, classes_num = 3, freeze_base = False),
nn.AvgPool2d(2, 2)
)
self.pe = PositionalEncoding(pos_len=100, d_model=2048, pe_type='t', dropout=0.0)
self.sed_trans_track1 = nn.TransformerEncoder(
nn.TransformerEncoderLayer(d_model=2048, nhead=8, dim_feedforward=1024, dropout=0.2), num_layers=2)
self.sed_trans_track2 = nn.TransformerEncoder(
nn.TransformerEncoderLayer(d_model=2048, nhead=8, dim_feedforward=1024, dropout=0.2), num_layers=2)
self.doa_trans_track1 = nn.TransformerEncoder(
nn.TransformerEncoderLayer(d_model=2048, nhead=8, dim_feedforward=1024, dropout=0.2), num_layers=2)
self.doa_trans_track2 = nn.TransformerEncoder(
nn.TransformerEncoderLayer(d_model=2048, nhead=8, dim_feedforward=1024, dropout=0.2), num_layers=2)
self.fc_sed_track1 = nn.Linear(1024, 14, bias=True)
self.fc_sed_track2 = nn.Linear(1024, 14, bias=True)
self.fc_doa_track1 = nn.Linear(1024, 3, bias=True)
self.fc_doa_track2 = nn.Linear(1024, 3, bias=True)
self.final_act_sed = nn.Sequential() # nn.Sigmoid()
self.final_act_doa = nn.Tanh()
self.init_weight()
for param in Transfer_Cnn14.parameters(self):
param.requires_grad = False
if freeze_base:
# Freeze AudioSet pretrained layers
for param in self.base.parameters():
param.requires_grad = False
self.init_weights()
for param in Transfer_Cnn14_d.parameters(self):
param.requires_grad = False
if freeze_base:
# Freeze AudioSet pretrained layers
for param in self.base.parameters():
param.requires_grad = False
self.init_weights()
# def init_weights(self):
# init_layer(self) #.fc_transfer
def load_from_pretrain(self, pretrained_checkpoint_path):
checkpoint = torch.load('/mnt/raid/ni/WALE_SEdl/EIN-SELD/Cnn14_DecisionLevelMax_mAP=0.385.pth') # pretrained_checkpoint_path
self.base.load_state_dict(checkpoint['model']) #model
def forward(self, input,mixup_lambda=None):
"""Input: (batch_size, data_length)
"""
output_dict = self.base(input, mixup_lambda)
embedding = output_dict['embedding']
def init_weight(self):
init_layer(self.fc_sed_track1)
init_layer(self.fc_sed_track2)
init_layer(self.fc_doa_track1)
init_layer(self.fc_doa_track2)
def forward(self, x):
"""
x: waveform, (batch_size, num_channels, data_length)
"""
x_sed = x[:, :4] #4
x_doa = x
# fc
x_sed_1 = self.final_act_sed(self.fc_sed_track1(x_sed)) #x_sed
x_sed_2 = self.final_act_sed(self.fc_sed_track2(x_sed))
x_sed = torch.stack((x_sed_1, x_sed_2), 2)
x_doa_1 = self.final_act_doa(self.fc_doa_track1(x_doa))
x_doa_2 = self.final_act_doa(self.fc_doa_track2(x_doa))
x_doa = torch.stack((x_doa_1, x_doa_2), 2)
output = {
'sed': x_sed,
'doa': x_doa,
}
return output
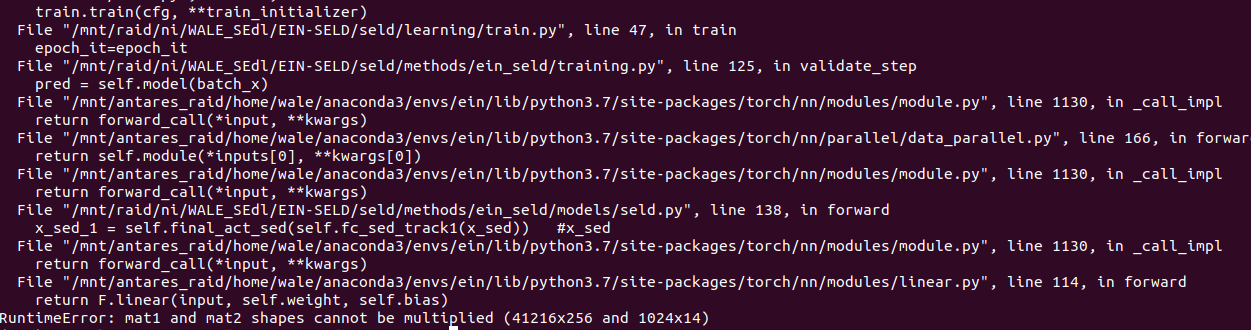
self.fc_sed_track1(x_sed) fails as 1024 input features are expected while x_sed contains 256.
Thanks, but how can I resolve this issue? please help. I have also observed that during model compilation, the number of parameters = 0, what is actually wrong? is there something odd about my model?
I have also the same problem, can you please help me with this. Here is my code:
class VisionTransformer(nn.Module):
def init(self, num_classes):
super(VisionTransformer, self).init()
# Define your ViT model architecture here
def forward(self, x):
# Implement the forward pass of the ViT model here
return x
class CNN(nn.Module):
def init(self, num_classes):
super(CNN, self).init()
# Define your CNN model architecture here
def forward(self, x):
# Implement the forward pass of the CNN model here
return x
batch_size = 2
feature_size = 150528
out_features = 5 # Number of classes
class CervicalCancerClassifier(nn.Module):
def init(self):
super(CervicalCancerClassifier, self).init()
self.vit = VisionTransformer(num_classes=out_features)
self.cnn = CNN(num_classes=out_features)
self.fc = nn.Linear(feature_size, out_features)
def forward(self, x):
x = self.vit(x)
x = self.cnn(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
here is the error:
strong text
You didn’t post the error message but I assume you are seeing a shape mismatch which would point to the linear layer. Check the activation shape as well as the features the linear layer expects and adapt the latter.
here is the error:
RuntimeError: Given groups=1, weight of size [64, 768, 3, 3], expected input[32, 1000, 1, 1] to have 768 channels, but got 1000 channels instead
and here is the updated code:
desired_output_channels = 12
transformer_output_size = 768
additional_conv = nn.Conv2d(in_channels=768, out_channels=64, kernel_size=3, stride=1, padding=1)
additional_fc = nn.Linear(in_features=64, out_features=desired_output_channels)
class ExtendedViTModel(nn.Module):
def init(self, vit_model, additional_conv, additional_fc):
super(ExtendedViTModel, self).init()
self.vit_model = vit_model
self.additional_conv = additional_conv
self.additional_fc = additional_fc
def forward(self, x):
# ViT forward pass
vit_output = self.vit_model(x)
# Additional convolutional layer
vit_output = vit_output.unsqueeze(-1).unsqueeze(-1) # Add height and width dimensions
model.additional_conv.out_channels = 1000
conv_output = self.additional_conv(vit_output)
conv_output = nn.functional.adaptive_avg_pool2d(conv_output, (1, 1))
# Flatten
conv_output = conv_output.view(conv_output.size(0), -1)
# Additional fully connected layer
fc_output = self.additional_fc(conv_output)
return fc_output
pretrained_vit = ExtendedViTModel(pretrained_vit, additional_conv, additional_fc).to(device)
print(pretrained_vit)
for i in range(0, 2034, 16):
for j in range(0, 2003, 16):
for k in range(0, 8182, 16):
sliced_data = crystal[i:i+16, j:j+16, k:k+16,:]
tensor_data=torch.as_tensor(sliced_data) #convert to tensor
tensor_data=torch.permute(tensor_data, (3, 0, 1, 2))
Y=model(tensor_data.float()) # pass through model
Error:
RuntimeError Traceback (most recent call last)
/scratch/14940477/ipykernel_1076915/2486182164.py in
5 tensor_data=torch.as_tensor(sliced_data) #convert to tensor
6 tensor_data=torch.permute(tensor_data, (3, 0, 1, 2))
----> 7 Y=model(tensor_data.float()) # pass through model
8 #vac conc
9 #x=i*vxl_size_x
/projects/academic/kreyes3/AtomicDL/YZTDL/model_training/my_env./lib/python3.9/site-packages/torch/nn/modules/module.py in _wrapped_call_impl(self, *args, **kwargs)
1516 return self._compiled_call_impl(*args, **kwargs) # type: ignore[misc]
1517 else:
→ 1518 return self._call_impl(*args, **kwargs)
1519
1520 def _call_impl(self, *args, **kwargs):
/projects/academic/kreyes3/AtomicDL/YZTDL/model_training/my_env./lib/python3.9/site-packages/torch/nn/modules/module.py in _call_impl(self, *args, **kwargs)
1525 or _global_backward_pre_hooks or _global_backward_hooks
1526 or _global_forward_hooks or _global_forward_pre_hooks):
→ 1527 return forward_call(*args, **kwargs)
1528
1529 try:
/projects/academic/kreyes3/AtomicDL/YZTDL/model_training/my_env./lib/python3.9/site-packages/vacancy_reconstruction/init.py in forward(self, x)
127
128 elif self.reconstruction_mode == ReconstructionMode.COUNTS:
→ 129 return self.head(z[-1]) # Dense network applied to latent features
130
131 else:
/projects/academic/kreyes3/AtomicDL/YZTDL/model_training/my_env./lib/python3.9/site-packages/torch/nn/modules/module.py in _wrapped_call_impl(self, *args, **kwargs)
1516 return self._compiled_call_impl(*args, **kwargs) # type: ignore[misc]
1517 else:
→ 1518 return self._call_impl(*args, **kwargs)
1519
1520 def _call_impl(self, *args, **kwargs):
/projects/academic/kreyes3/AtomicDL/YZTDL/model_training/my_env./lib/python3.9/site-packages/torch/nn/modules/module.py in _call_impl(self, *args, **kwargs)
1525 or _global_backward_pre_hooks or _global_backward_hooks
1526 or _global_forward_hooks or _global_forward_pre_hooks):
→ 1527 return forward_call(*args, **kwargs)
1528
1529 try:
/projects/academic/kreyes3/AtomicDL/YZTDL/model_training/my_env./lib/python3.9/site-packages/torch/nn/modules/container.py in forward(self, input)
213 def forward(self, input):
214 for module in self:
→ 215 input = module(input)
216 return input
217
/projects/academic/kreyes3/AtomicDL/YZTDL/model_training/my_env./lib/python3.9/site-packages/torch/nn/modules/module.py in _wrapped_call_impl(self, *args, **kwargs)
1516 return self._compiled_call_impl(*args, **kwargs) # type: ignore[misc]
1517 else:
→ 1518 return self._call_impl(*args, **kwargs)
1519
1520 def _call_impl(self, *args, **kwargs):
/projects/academic/kreyes3/AtomicDL/YZTDL/model_training/my_env./lib/python3.9/site-packages/torch/nn/modules/module.py in _call_impl(self, *args, **kwargs)
1525 or _global_backward_pre_hooks or _global_backward_hooks
1526 or _global_forward_hooks or _global_forward_pre_hooks):
→ 1527 return forward_call(*args, **kwargs)
1528
1529 try:
/projects/academic/kreyes3/AtomicDL/YZTDL/model_training/my_env./lib/python3.9/site-packages/torch/nn/modules/linear.py in forward(self, input)
112
113 def forward(self, input: Tensor) → Tensor:
→ 114 return F.linear(input, self.weight, self.bias)
115
116 def extra_repr(self) → str:
RuntimeError: mat1 and mat2 shapes cannot be multiplied (6x512 and 3072x4)
Your code is not properly formatted and hard to read. However, it seems the shape mismatch is raised in:
/projects/academic/kreyes3/AtomicDL/YZTDL/model_training/my_env./lib/python3.9/site-packages/vacancy_reconstruction/init.py in forward(self, x)
127
128 elif self.reconstruction_mode == ReconstructionMode.COUNTS:
→ 129 return self.head(z[-1]) # Dense network applied to latent features
so you might want to check which input self.head expects and why z does not fit.
Here, i am providing few chunk of my code where it gives error regarding matrix multiplication, i am new here, i am trying but unable to figure out its solution. if possible please help me out.
BP Weight_model start
Weight_classifier(
(weight_layer): MaskedLinear(in_features=215, out_features=215, bias=True)
(outlayer): Linear(in_features=215, out_features=215, bias=True)
)
batch_size_8,learning_rate_0.01,epoch_times_1
Traceback (most recent call last):
File "/home/bvs/neelam/input_ourmodel/input/4valid.py", line 1012, in <module>
validation(Terms[0], 5)
File "/home/bvs/neelam/input_ourmodel/input/4valid.py", line 994, in validation
each_fold_scores = Main(train_set, test_set, func=func)
File "/home/bvs/neelam/input_ourmodel/input/4valid.py", line 884, in Main
out = weight_model(weight_features)
File "/home/bvs/miniconda3/envs/crisprcasfinder/envs/envML/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1130, in _call_impl
return forward_call(*input, **kwargs)
File "/home/bvs/neelam/input_ourmodel/input/4valid.py", line 314, in forward
weight_out = self.weight_layer(weight_features)
File "/home/bvs/miniconda3/envs/crisprcasfinder/envs/envML/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1130, in _call_impl
return forward_call(*input, **kwargs)
File "/home/bvs/neelam/input_ourmodel/input/4valid.py", line 331, in forward
return F.linear(input, masked_weight, self.bias)
RuntimeError: mat1 and mat2 shapes cannot be multiplied (8x645 and 215x215)`
Here, I am providing link of all my input file that i am using in this model (4valid.py). (GitHub - neelam19051/DLmodel)
Thank you so much!
Double post from here.
Can Yo please help me solve this I am trying it from last three days
import pytorch_lightning as pl
import torch
import torch.nn as nn
import torch.nn.functional as F
class MFB(nn.Module):
def __init__(self,img_feat_size, ques_feat_size,is_first, MFB_K, MFB_O, DROPOUT_R):
super(MFB, self).__init__()
#self.__C = __C
self.MFB_K = MFB_K
self.MFB_O = MFB_O
self.DROPOUT_R = DROPOUT_R
self.is_first = is_first
self.proj_i = nn.Linear(img_feat_size, MFB_K * MFB_O)
self.proj_q = nn.Linear(ques_feat_size, MFB_K * MFB_O)
self.dropout = nn.Dropout(DROPOUT_R)
self.pool = nn.AvgPool1d(MFB_K, stride = MFB_K)
def forward(self, img_feat, ques_feat,exp_in=1):
batch_size = img_feat.shape[0]
img_feat = self.proj_i(img_feat) # (N, C, K*O)
ques_feat = self.proj_q(ques_feat) # (N, 1, K*O)
exp_out = img_feat * ques_feat # (N, C, K*O)
exp_out = self.dropout(exp_out) if self.is_first else self.dropout(exp_out * exp_in) # (N, C, K*O)
z = self.pool(exp_out) * self.MFB_K # (N, C, O)
z = torch.sqrt(F.relu(z)) - torch.sqrt(F.relu(-z))
z = F.normalize(z.view(batch_size, -1)) # (N, C*O)
z = z.view(batch_size, -1, self.MFB_O) # (N, C, O)
return z
class Classifier(pl.LightningModule):
def __init__(self):
super().__init__()
self.MFB = MFB(512,768,True,256,64,0.1)
self.loss_fn_emotion=torch.nn.KLDivLoss(reduction='batchmean',log_target=True)
self.fin_y_shape = torch.nn.Linear(768,512)
self.fin_old = torch.nn.Linear(64,2)
self.fin = torch.nn.Linear(16 * 768, 64)
self.fin_persuasive = torch.nn.Linear(16 * 768, 64)
self.fin_e1 = torch.nn.Linear(16 * 768, 64)
self.fin_e2 = torch.nn.Linear(16 * 768, 64)
self.fin_e3 = torch.nn.Linear(16 * 768, 64)
self.fin_e4 = torch.nn.Linear(16 * 768, 64)
self.fin_e5 = torch.nn.Linear(16 * 768, 64)
self.fin_e6 = torch.nn.Linear(16 * 768, 64)
self.fin_e7 = torch.nn.Linear(16 * 768, 64)
self.fin_e8 = torch.nn.Linear(16 * 768, 64)
self.fin_e9 = torch.nn.Linear(16 * 768, 64)
self.validation_step_outputs = []
self.test_step_outputs = []
def forward(self, x,y,rag):
x_,y_,rag_ = x,y,rag
print("x.shape", x.shape)
z = self.MFB(torch.unsqueeze(y, axis=1), torch.unsqueeze(x, axis=1))
#cross_attention= (rag and x/y)
z_new = torch.squeeze(z, dim=1)
c = self.fin_old(z_new)
c_e1 = self.fin_e1(torch.squeeze(z,dim=1))
c_v = self.fin_persuasive(torch.squeeze(z,dim=1))
c_e2 = self.fin_e2(torch.squeeze(z,dim=1))
c_e3 = self.fin_e3(torch.squeeze(z,dim=1))
c_e4 = self.fin_e4(torch.squeeze(z,dim=1))
c_e5 = self.fin_e5(torch.squeeze(z,dim=1))
c_e6 = self.fin_e6(torch.squeeze(z,dim=1))
c_e7 = self.fin_e7(torch.squeeze(z,dim=1))
c_e8 = self.fin_e8(torch.squeeze(z,dim=1))
c_e9 = self.fin_e9(torch.squeeze(z,dim=1))
c = torch.log_softmax(c, dim=1)
c_v = torch.log_softmax(c_v, dim=1)
c_e1 = torch.log_softmax(c_e1, dim=1)
c_e2 = torch.log_softmax(c_e2, dim=1)
c_e3 = torch.log_softmax(c_e3, dim=1)
c_e4 = torch.log_softmax(c_e4, dim=1)
c_e5 = torch.log_softmax(c_e5, dim=1)
c_e6 = torch.log_softmax(c_e6, dim=1)
c_e7 = torch.log_softmax(c_e7, dim=1)
c_e8 = torch.log_softmax(c_e8, dim=1)
c_e9 = torch.log_softmax(c_e9, dim=1)
return z,c,c_v,c_e1,c_e2,c_e3,c_e4,c_e5,c_e6,c_e7,c_e8,c_e9
def cross_entropy_loss(self, logits, labels):
return F.nll_loss(logits, labels)
def training_step(self, train_batch, batch_idx):
lab,txt,rag,img,name,perin,per,iro,alli,ana,inv,meta,puns,sat,hyp= train_batch
lab = train_batch[lab]
#print(lab)
name= train_batch[name]
txt = train_batch[txt]
rag = train_batch[rag]
img = train_batch[img]
perin = train_batch[perin]
per = train_batch[per]
iro= train_batch[iro]
alli = train_batch[alli]
ana = train_batch[ana]
inv = train_batch[inv]
meta = train_batch[meta]
puns = train_batch[puns]
sat = train_batch[sat]
hyp = train_batch[hyp]
gt_emotion = torch.cat((torch.unsqueeze(per,1),torch.unsqueeze(iro,1),torch.unsqueeze(alli,1),\
torch.unsqueeze(ana,1),torch.unsqueeze(inv,1),torch.unsqueeze(meta,1),\
torch.unsqueeze(puns,1),torch.unsqueeze(sat,1),torch.unsqueeze(hyp,1)),1)
z,logit_offen,logit_perin,a,b,c,d,e,f,g,h,i= self.forward(txt,img,rag) # logit_target is logits of target
# logit_offen= self.forward(txt,img,rag)
loss23=self.cross_entropy_loss(logit_perin,perin)
loss1 = self.cross_entropy_loss(logit_offen, lab)
loss2 = self.cross_entropy_loss(a,per)
loss3 = self.cross_entropy_loss(b,iro)
loss4 = self.cross_entropy_loss(c, alli)
loss5 = self.cross_entropy_loss(d,ana)
loss6 = self.cross_entropy_loss(e,inv)
loss7 = self.cross_entropy_loss(f,meta)
loss8 = self.cross_entropy_loss(g,puns)
loss9 = self.cross_entropy_loss(h,sat)
loss10 = self.cross_entropy_loss(i,hyp)
# loss = loss1 + loss2 + loss3 + loss4 + loss5 + loss6 + loss7 + loss8 +loss9 + loss10
loss_emo_mult = F.binary_cross_entropy_with_logits(gt_emotion.float())
loss=loss1+loss_emo_mult
self.log('train_loss', loss)
return loss
def validation_step(self, val_batch, batch_idx):
lab,txt,rag,img,name,perin,per,iro,alli,ana,inv,meta,puns,sat,hyp = val_batch
lab = val_batch[lab]
#print(lab)
txt = val_batch[txt]
rag = val_batch[rag]
img = val_batch[img]
name = val_batch[name]
perin = val_batch[perin]
per = val_batch[per]
iro = val_batch[iro]
alli = val_batch[alli]
ana = val_batch[ana]
inv = val_batch[inv]
meta = val_batch[meta]
puns = val_batch[puns]
sat = val_batch[sat]
hyp = val_batch[hyp]
gt_emotion = torch.cat((torch.unsqueeze(per,1),torch.unsqueeze(iro,1),torch.unsqueeze(alli,1),\
torch.unsqueeze(ana,1),torch.unsqueeze(inv,1),torch.unsqueeze(meta,1),\
torch.unsqueeze(puns,1),torch.unsqueeze(sat,1),torch.unsqueeze(hyp,1)),1)
logits,logit_perin,a,b,c,d,e,f,g,h,i = self.forward(txt,img,rag)
# logits= self.forward(txt,img,rag)
logits=logits.float()
tmp = np.argmax(logits.detach().cpu().numpy(),axis=-1)
loss = self.cross_entropy_loss(logits, lab)
lab = lab.detach().cpu().numpy()
self.log('val_acc', accuracy_score(lab,tmp))
self.log('val_roc_auc',roc_auc_score(lab,tmp))
self.log('val_loss', loss)
tqdm_dict = {'val_acc': accuracy_score(lab,tmp)}
self.validation_step_outputs.append({'progress_bar': tqdm_dict,'val_f1 offensive': f1_score(lab,tmp,average='macro')})
return {
'progress_bar': tqdm_dict,
'val_f1 offensive': f1_score(lab,tmp,average='macro'),
'val_f1 personification': f1_score(per,tmp,average='macro'),
'val_f1 irony': f1_score(iro,tmp,average='macro'),
'val_f1 alliteration': f1_score(alli,tmp,average='macro'),
'val_f1 analogies': f1_score(ana,tmp,average='macro'),
'val_f1 invective': f1_score(inv,tmp,average='macro'),
'val_f1 metaphor': f1_score(meta,tmp,average='macro'),
'val_f1 punsandplay': f1_score(puns,tmp,average='macro'),
'val_f1 satire': f1_score(sat,tmp,average='macro'),
'val_f1 hyperboles': f1_score(hyp,tmp,average='macro')
}
def on_validation_epoch_end(self):
outs = []
outs14=[]
for out in self.validation_step_outputs:
outs.append(out['progress_bar']['val_acc'])
outs14.append(out['val_f1 offensive'])
self.log('val_acc_all_offn', sum(outs)/len(outs))
self.log('val_f1 offensive', sum(outs14)/len(outs14))
print(f'***val_acc_all_offn at epoch end {sum(outs)/len(outs)}****')
print(f'***val_f1 offensive at epoch end {sum(outs14)/len(outs14)}****')
self.validation_step_outputs.clear()
def test_step(self, batch, batch_idx):
# lab,txt,e1,e2,e3,e4,e5,e6,e7,e8,e9,e10,e11,e12, e13,e14, e15,e16,img,name= batch
lab,txt,rag,img,name,per,iro,alli,ana,inv,meta,puns,sat,hyp= batch
lab = batch[lab]
#print(lab)
rag = batch[rag]
txt = batch[txt]
img = batch[img]
name = batch[name]
per = batch[per]
iro = batch[iro]
alli = batch[alli]
ana = batch[ana]
inv = batch[inv]
meta = batch[meta]
puns = batch[puns]
sat = batch[sat]
hyp = batch[hyp]
gt_emotion = torch.cat((torch.unsqueeze(e1,1),torch.unsqueeze(e2,1),torch.unsqueeze(e3,1),torch.unsqueeze(e4,1),torch.unsqueeze(e5,1),torch.unsqueeze(e6,1),\
torch.unsqueeze(e7,1),torch.unsqueeze(e8,1),torch.unsqueeze(e9,1)),1)
_,logits,a,b,c,d,e,f,g,h,i= self.forward(txt,img,rag)
logits = logits.float()
tmp = np.argmax(logits.detach().cpu().numpy(force=True),axis=-1)
loss = self.cross_entropy_loss(logits, lab)
lab = lab.detach().cpu().numpy()
self.log('test_acc', accuracy_score(lab,tmp))
self.log('test_roc_auc',roc_auc_score(lab,tmp))
self.log('test_loss', loss)
tqdm_dict = {'test_acc': accuracy_score(lab,tmp)}
self.test_step_outputs.append({'progress_bar': tqdm_dict,'test_acc': accuracy_score(lab,tmp), 'test_f1_score': f1_score(lab,tmp,average='macro')})
return {
'progress_bar': tqdm_dict,
'test_acc': accuracy_score(lab,tmp),
'test_f1_score': f1_score(lab,tmp,average='macro'),
'test_f1_score': f1_score(lab,tmp,average='macro'),
'test_f1_score': f1_score(lab,tmp,average='macro'),
'test_f1_score': f1_score(lab,tmp,average='macro'),
'test_f1_score': f1_score(lab,tmp,average='macro'),
'test_f1_score': f1_score(lab,tmp,average='macro'),
'test_f1_score': f1_score(lab,tmp,average='macro')
}
def on_test_epoch_end(self):
# OPTIONAL
outs = []
outs1,outs2,outs3,outs4,outs5,outs6,outs7,outs8,outs9,outs10,outs11,outs12,outs13,outs14 = \
[],[],[],[],[],[],[],[],[],[],[],[],[],[]
for out in self.test_step_outputs:
outs.append(out['test_acc'])
outs2.append(out['test_f1_score'])
self.log('test_acc', sum(outs)/len(outs))
self.log('test_f1_score', sum(outs2)/len(outs2))
self.test_step_outputs.clear()
def configure_optimizers(self):
# optimizer = torch.optim.Adam(self.parameters(), lr=3e-2)
optimizer = torch.optim.Adam(self.parameters(), lr=1e-5)
return optimizer
"""
Main Model:
Initialize
Forward Pass
Training Step
Validation Step
Testing Step
Pp
"""
class HmDataModule(pl.LightningDataModule):
def setup(self, stage):
self.hm_train = t_p
self.hm_val = v_p
# self.hm_test = test
self.hm_test = te_p
def train_dataloader(self):
return DataLoader(self.hm_train, batch_size=20, drop_last=True)
def val_dataloader(self):
return DataLoader(self.hm_val, batch_size=20, drop_last=True)
def test_dataloader(self):
return DataLoader(self.hm_test, batch_size=20, drop_last=True)
data_module = HmDataModule()
checkpoint_callback = ModelCheckpoint(
monitor='val_acc_all_offn',
dirpath='mrinal/',
filename='epoch{epoch:02d}-val_f1_all_offn{val_acc_all_offn:.2f}',
auto_insert_metric_name=False,
save_top_k=1,
mode="max",
)
all_callbacks = []
all_callbacks.append(checkpoint_callback)
# train
from pytorch_lightning import seed_everything
seed_everything(42, workers=True)
hm_model = Classifier()
gpus=1
#if torch.cuda.is_available():gpus=0
trainer = pl.Trainer(deterministic=True,max_epochs=10,precision=16,callbacks=all_callbacks)
trainer.fit(hm_model, data_module)
RuntimeError Traceback (most recent call last)
in <cell line: 285>()
283 #if torch.cuda.is_available():gpus=0
284 trainer = pl.Trainer(deterministic=True,max_epochs=10,precision=16,callbacks=all_callbacks)
→ 285 trainer.fit(hm_model, data_module)
14 frames
/usr/local/lib/python3.10/dist-packages/torch/nn/modules/linear.py in forward(self, input)
112
113 def forward(self, input: Tensor) → Tensor:
→ 114 return F.linear(input, self.weight, self.bias)
115
116 def extra_repr(self) → str:
RuntimeError: mat1 and mat2 shapes cannot be multiplied (20x64 and 12288x64)
I am not getting what’s wrong I am doing
It seems z should have a shape of [batch_size, -1, 64] here:
z = self.MFB(torch.unsqueeze(y, axis=1), torch.unsqueeze(x, axis=1))
based on:
z = z.view(batch_size, -1, self.MFB_O) # (N, C, O)
return z
and will thus use 64 input features (dim1 is squeezed later).
The self.fin_eX layers however expect an activation input with 16 * 768 input features and will this fail.
sir,How should I solve this, can you please tell me little bit more.
import os
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
from pathlib import Path
from typing import Union
class SineReLU(nn.Module):
def forward(self, x):
return torch.sin(F.relu(x))
class HighwayNetwork(nn.Module):
def init(self, size):
super().init()
self.W1 = nn.Linear(size, size)
self.W2 = nn.Linear(size, size)
self.W1.bias.data.fill_(0.)
def forward(self, x):
x1 = self.W1(x)
x2 = self.W2(x)
g = torch.sigmoid(x2)
# Replace F.relu(x1) with SineReLU in the HighwayNetwork class
y = g * SineReLU()(x1) + (1. - g) * x
return y
class Encoder(nn.Module):
def init(self, embed_dims, num_chars, encoder_dims, K, num_highways, dropout):
super().init()
prenet_dims = (encoder_dims, encoder_dims)
cbhg_channels = encoder_dims
self.embedding = nn.Embedding(num_chars, embed_dims)
self.pre_net = PreNet(embed_dims, fc1_dims=prenet_dims[0], fc2_dims=prenet_dims[1],
dropout=dropout)
self.cbhg = CBHG(K=K, in_channels=cbhg_channels, channels=cbhg_channels,
proj_channels=[cbhg_channels, cbhg_channels],
num_highways=num_highways)
def forward(self, x, speaker_embedding=None):
x = self.embedding(x)
x = self.pre_net(x)
x.transpose_(1, 2)
x = self.cbhg(x)
if speaker_embedding is not None:
x = self.add_speaker_embedding(x, speaker_embedding)
return x
def add_speaker_embedding(self, x, speaker_embedding):
# SV2TTS
# The input x is the encoder output and is a 3D tensor with size (batch_size, num_chars, tts_embed_dims)
# When training, speaker_embedding is also a 2D tensor with size (batch_size, speaker_embedding_size)
# (for inference, speaker_embedding is a 1D tensor with size (speaker_embedding_size))
# This concats the speaker embedding for each char in the encoder output
# Save the dimensions as human-readable names
batch_size = x.size()[0]
num_chars = x.size()[1]
if speaker_embedding.dim() == 1:
idx = 0
else:
idx = 1
# Start by making a copy of each speaker embedding to match the input text length
# The output of this has size (batch_size, num_chars * tts_embed_dims)
speaker_embedding_size = speaker_embedding.size()[idx]
e = speaker_embedding.repeat_interleave(num_chars, dim=idx)
# Reshape it and transpose
e = e.reshape(batch_size, speaker_embedding_size, num_chars)
e = e.transpose(1, 2)
# Concatenate the tiled speaker embedding with the encoder output
x = torch.cat((x, e), 2)
return x
class BatchNormConv(nn.Module):
def init(self, in_channels, out_channels, kernel, relu=True):
super().init()
self.conv = nn.Conv1d(in_channels, out_channels, kernel, stride=1, padding=kernel // 2, bias=False)
self.bnorm = nn.BatchNorm1d(out_channels)
self.relu = SineReLU()
def forward(self, x):
x = self.conv(x)
x = F.relu(x) if self.relu is True else x
return self.bnorm(x)
class CBHG(nn.Module):
def init(self, K, in_channels, channels, proj_channels, num_highways):
super().init()
# List of all rnns to call `flatten_parameters()` on
self._to_flatten = []
self.bank_kernels = [i for i in range(1, K + 1)]
self.conv1d_bank = nn.ModuleList()
for k in self.bank_kernels:
conv = BatchNormConv(in_channels, channels, k)
self.conv1d_bank.append(conv)
self.maxpool = nn.MaxPool1d(kernel_size=2, stride=1, padding=1)
self.conv_project1 = BatchNormConv(len(self.bank_kernels) * channels, proj_channels[0], 3)
self.conv_project2 = BatchNormConv(proj_channels[0], proj_channels[1], 3, relu=False)
# Fix the highway input if necessary
if proj_channels[-1] != channels:
self.highway_mismatch = True
self.pre_highway = nn.Linear(proj_channels[-1], channels, bias=False)
else:
self.highway_mismatch = False
self.highways = nn.ModuleList()
for i in range(num_highways):
hn = HighwayNetwork(channels)
self.highways.append(hn)
self.rnn = nn.GRU(channels, channels // 2, batch_first=True, bidirectional=True)
self._to_flatten.append(self.rnn)
# Avoid fragmentation of RNN parameters and associated warning
self._flatten_parameters()
def forward(self, x):
# Although we `_flatten_parameters()` on init, when using DataParallel
# the model gets replicated, making it no longer guaranteed that the
# weights are contiguous in GPU memory. Hence, we must call it again
self._flatten_parameters()
# Save these for later
residual = x
seq_len = x.size(-1)
conv_bank = []
# Convolution Bank
for conv in self.conv1d_bank:
c = conv(x) # Convolution
conv_bank.append(c[:, :, :seq_len])
# Stack along the channel axis
conv_bank = torch.cat(conv_bank, dim=1)
# dump the last padding to fit residual
x = self.maxpool(conv_bank)[:, :, :seq_len]
# Conv1d projections
x = self.conv_project1(x)
x = self.conv_project2(x)
# Residual Connect
x = x + residual
# Through the highways
x = x.transpose(1, 2)
if self.highway_mismatch is True:
x = self.pre_highway(x)
for h in self.highways: x = h(x)
# And then the RNN
x, _ = self.rnn(x)
return x
def _flatten_parameters(self):
"""Calls `flatten_parameters` on all the rnns used by the WaveRNN. Used
to improve efficiency and avoid PyTorch yelling at us."""
[m.flatten_parameters() for m in self._to_flatten]
class PreNet(nn.Module):
def init(self, in_dims, fc1_dims=256, fc2_dims=128, dropout=0.5):
super().init()
self.fc1 = nn.Linear(in_dims, fc1_dims)
self.fc2 = nn.Linear(fc1_dims, fc2_dims)
self.p = dropout
def forward(self, x):
x = self.fc1(x)
x = F.relu(x)
x = F.dropout(x, self.p, training=True)
x = self.fc2(x)
x = F.relu(x)
x = F.dropout(x, self.p, training=True)
return x
class Attention(nn.Module):
def init(self, attn_dims):
super().init()
self.W = nn.Linear(attn_dims, attn_dims, bias=False)
self.v = nn.Linear(attn_dims, 1, bias=False)
def forward(self, encoder_seq_proj, query, t):
# print(encoder_seq_proj.shape)
# Transform the query vector
query_proj = self.W(query).unsqueeze(1)
# Compute the scores
u = self.v(torch.tanh(encoder_seq_proj + query_proj))
scores = F.softmax(u, dim=1)
return scores.transpose(1, 2)
class LSA(nn.Module):
def init(self, attn_dim, kernel_size=31, filters=32):
super().init()
self.conv = nn.Conv1d(1, filters, padding=(kernel_size - 1) // 2, kernel_size=kernel_size, bias=True)
self.L = nn.Linear(filters, attn_dim, bias=False)
self.W = nn.Linear(attn_dim, attn_dim, bias=True) # Include the attention bias in this term
self.v = nn.Linear(attn_dim, 1, bias=False)
self.cumulative = None
self.attention = None
def init_attention(self, encoder_seq_proj):
device = next(self.parameters()).device # use same device as parameters
b, t, c = encoder_seq_proj.size()
self.cumulative = torch.zeros(b, t, device=device)
self.attention = torch.zeros(b, t, device=device)
def forward(self, encoder_seq_proj, query, t, chars):
if t == 0: self.init_attention(encoder_seq_proj)
processed_query = self.W(query).unsqueeze(1)
location = self.cumulative.unsqueeze(1)
processed_loc = self.L(self.conv(location).transpose(1, 2))
u = self.v(torch.tanh(processed_query + encoder_seq_proj + processed_loc))
u = u.squeeze(-1)
# Mask zero padding chars
u = u * (chars != 0).float()
# Smooth Attention
# scores = torch.sigmoid(u) / torch.sigmoid(u).sum(dim=1, keepdim=True)
scores = F.softmax(u, dim=1)
self.attention = scores
self.cumulative = self.cumulative + self.attention
return scores.unsqueeze(-1).transpose(1, 2)
class Decoder(nn.Module):
# Class variable because its value doesn’t change between classes
# yet ought to be scoped by class because its a property of a Decoder
max_r = 20
def init(self, n_mels, encoder_dims, decoder_dims, lstm_dims,
dropout, speaker_embedding_size):
super().init()
self.register_buffer(“r”, torch.tensor(1, dtype=torch.int))
self.n_mels = n_mels
prenet_dims = (decoder_dims * 2, decoder_dims * 2)
self.prenet = PreNet(n_mels, fc1_dims=prenet_dims[0], fc2_dims=prenet_dims[1],
dropout=dropout)
self.attn_net = LSA(decoder_dims)
self.attn_rnn = nn.GRUCell(encoder_dims + prenet_dims[1] + speaker_embedding_size, decoder_dims)
self.rnn_input = nn.Linear(encoder_dims + decoder_dims + speaker_embedding_size, lstm_dims)
self.res_rnn1 = nn.LSTMCell(lstm_dims, lstm_dims)
self.res_rnn2 = nn.LSTMCell(lstm_dims, lstm_dims)
self.mel_proj = nn.Linear(lstm_dims, n_mels * self.max_r, bias=False)
self.stop_proj = nn.Linear(encoder_dims + speaker_embedding_size + lstm_dims, 1)
def zoneout(self, prev, current, p=0.1):
device = next(self.parameters()).device # Use same device as parameters
mask = torch.zeros(prev.size(), device=device).bernoulli_(p)
return prev * mask + current * (1 - mask)
def forward(self, encoder_seq, encoder_seq_proj, prenet_in,
hidden_states, cell_states, context_vec, t, chars):
# Need this for reshaping mels
batch_size = encoder_seq.size(0)
# Unpack the hidden and cell states
attn_hidden, rnn1_hidden, rnn2_hidden = hidden_states
rnn1_cell, rnn2_cell = cell_states
# PreNet for the Attention RNN
prenet_out = self.prenet(prenet_in)
# Compute the Attention RNN hidden state
attn_rnn_in = torch.cat([context_vec, prenet_out], dim=-1)
attn_hidden = self.attn_rnn(attn_rnn_in.squeeze(1), attn_hidden)
# Compute the attention scores
scores = self.attn_net(encoder_seq_proj, attn_hidden, t, chars)
# Dot product to create the context vector
context_vec = scores @ encoder_seq
context_vec = context_vec.squeeze(1)
# Concat Attention RNN output w. Context Vector & project
x = torch.cat([context_vec, attn_hidden], dim=1)
x = self.rnn_input(x)
# Compute first Residual RNN
rnn1_hidden_next, rnn1_cell = self.res_rnn1(x, (rnn1_hidden, rnn1_cell))
if self.training:
rnn1_hidden = self.zoneout(rnn1_hidden, rnn1_hidden_next)
else:
rnn1_hidden = rnn1_hidden_next
x = x + rnn1_hidden
# Compute second Residual RNN
rnn2_hidden_next, rnn2_cell = self.res_rnn2(x, (rnn2_hidden, rnn2_cell))
if self.training:
rnn2_hidden = self.zoneout(rnn2_hidden, rnn2_hidden_next)
else:
rnn2_hidden = rnn2_hidden_next
x = x + rnn2_hidden
# Project Mels
mels = self.mel_proj(x)
mels = mels.view(batch_size, self.n_mels, self.max_r)[:, :, :self.r]
hidden_states = (attn_hidden, rnn1_hidden, rnn2_hidden)
cell_states = (rnn1_cell, rnn2_cell)
# Stop token prediction
s = torch.cat((x, context_vec), dim=1)
s = self.stop_proj(s)
stop_tokens = torch.sigmoid(s)
return mels, scores, hidden_states, cell_states, context_vec, stop_tokens
class Tacotron(nn.Module):
def init(self, embed_dims, num_chars, encoder_dims, decoder_dims, n_mels,
fft_bins, postnet_dims, encoder_K, lstm_dims, postnet_K, num_highways,
dropout, stop_threshold, speaker_embedding_size):
super().init()
self.n_mels = n_mels
self.lstm_dims = lstm_dims
self.encoder_dims = encoder_dims
self.decoder_dims = decoder_dims
self.speaker_embedding_size = speaker_embedding_size
self.encoder = Encoder(embed_dims, num_chars, encoder_dims,
encoder_K, num_highways, dropout)
self.encoder_proj = nn.Linear(encoder_dims + speaker_embedding_size, decoder_dims, bias=False)
self.decoder = Decoder(n_mels, encoder_dims, decoder_dims, lstm_dims,
dropout, speaker_embedding_size)
self.postnet = CBHG(postnet_K, n_mels, postnet_dims,
[postnet_dims, fft_bins], num_highways)
self.post_proj = nn.Linear(postnet_dims, fft_bins, bias=False)
self.init_model()
self.num_params()
self.register_buffer("step", torch.zeros(1, dtype=torch.long))
self.register_buffer("stop_threshold", torch.tensor(stop_threshold, dtype=torch.float32))
@property
def r(self):
return self.decoder.r.item()
@r.setter
def r(self, value):
self.decoder.r = self.decoder.r.new_tensor(value, requires_grad=False)
def forward(self, x, m, speaker_embedding):
device = next(self.parameters()).device # use same device as parameters
self.step += 1
batch_size, _, steps = m.size()
# Initialise all hidden states and pack into tuple
attn_hidden = torch.zeros(batch_size, self.decoder_dims, device=device)
rnn1_hidden = torch.zeros(batch_size, self.lstm_dims, device=device)
rnn2_hidden = torch.zeros(batch_size, self.lstm_dims, device=device)
hidden_states = (attn_hidden, rnn1_hidden, rnn2_hidden)
# Initialise all lstm cell states and pack into tuple
rnn1_cell = torch.zeros(batch_size, self.lstm_dims, device=device)
rnn2_cell = torch.zeros(batch_size, self.lstm_dims, device=device)
cell_states = (rnn1_cell, rnn2_cell)
# <GO> Frame for start of decoder loop
go_frame = torch.zeros(batch_size, self.n_mels, device=device)
# Need an initial context vector
context_vec = torch.zeros(batch_size, self.encoder_dims + self.speaker_embedding_size, device=device)
# SV2TTS: Run the encoder with the speaker embedding
# The projection avoids unnecessary matmuls in the decoder loop
encoder_seq = self.encoder(x, speaker_embedding)
print("Encoder sequence shape:", encoder_seq.shape)
encoder_seq_proj = self.encoder_proj(encoder_seq)
print(encoder_seq.shape, self.encoder_proj.weight.shape, self.encoder_proj.bias.shape)
# Need a couple of lists for outputs
mel_outputs, attn_scores, stop_outputs = [], [], []
# Run the decoder loop
for t in range(0, steps, self.r):
prenet_in = m[:, :, t - 1] if t > 0 else go_frame
mel_frames, scores, hidden_states, cell_states, context_vec, stop_tokens = \
self.decoder(encoder_seq, encoder_seq_proj, prenet_in,
hidden_states, cell_states, context_vec, t, x)
mel_outputs.append(mel_frames)
attn_scores.append(scores)
stop_outputs.extend([stop_tokens] * self.r)
# Concat the mel outputs into sequence
mel_outputs = torch.cat(mel_outputs, dim=2)
# Post-Process for Linear Spectrograms
postnet_out = self.postnet(mel_outputs)
linear = self.post_proj(postnet_out)
linear = linear.transpose(1, 2)
# For easy visualisation
attn_scores = torch.cat(attn_scores, 1)
# attn_scores = attn_scores.cpu().data.numpy()
stop_outputs = torch.cat(stop_outputs, 1)
return mel_outputs, linear, attn_scores, stop_outputs
def generate(self, x, speaker_embedding=None, steps=2000):
self.eval()
device = next(self.parameters()).device # use same device as parameters
batch_size, _ = x.size()
# Need to initialise all hidden states and pack into tuple for tidyness
attn_hidden = torch.zeros(batch_size, self.decoder_dims, device=device)
rnn1_hidden = torch.zeros(batch_size, self.lstm_dims, device=device)
rnn2_hidden = torch.zeros(batch_size, self.lstm_dims, device=device)
hidden_states = (attn_hidden, rnn1_hidden, rnn2_hidden)
# Need to initialise all lstm cell states and pack into tuple for tidyness
rnn1_cell = torch.zeros(batch_size, self.lstm_dims, device=device)
rnn2_cell = torch.zeros(batch_size, self.lstm_dims, device=device)
cell_states = (rnn1_cell, rnn2_cell)
# Need a <GO> Frame for start of decoder loop
go_frame = torch.zeros(batch_size, self.n_mels, device=device)
# Need an initial context vector
context_vec = torch.zeros(batch_size, self.encoder_dims + self.speaker_embedding_size, device=device)
# SV2TTS: Run the encoder with the speaker embedding
# The projection avoids unnecessary matmuls in the decoder loop
encoder_seq = self.encoder(x, speaker_embedding)
encoder_seq_proj = self.encoder_proj(encoder_seq)
# Need a couple of lists for outputs
mel_outputs, attn_scores, stop_outputs = [], [], []
# Run the decoder loop
for t in range(0, steps, self.r):
prenet_in = mel_outputs[-1][:, :, -1] if t > 0 else go_frame
mel_frames, scores, hidden_states, cell_states, context_vec, stop_tokens = \
self.decoder(encoder_seq, encoder_seq_proj, prenet_in,
hidden_states, cell_states, context_vec, t, x)
mel_outputs.append(mel_frames)
attn_scores.append(scores)
stop_outputs.extend([stop_tokens] * self.r)
# Stop the loop when all stop tokens in batch exceed threshold
if (stop_tokens > 0.5).all() and t > 10: break
# Concat the mel outputs into sequence
mel_outputs = torch.cat(mel_outputs, dim=2)
# Post-Process for Linear Spectrograms
postnet_out = self.postnet(mel_outputs)
linear = self.post_proj(postnet_out)
linear = linear.transpose(1, 2)
# For easy visualisation
attn_scores = torch.cat(attn_scores, 1)
stop_outputs = torch.cat(stop_outputs, 1)
self.train()
return mel_outputs, linear, attn_scores
def init_model(self):
for p in self.parameters():
if p.dim() > 1: nn.init.xavier_uniform_(p)
def get_step(self):
return self.step.data.item()
def reset_step(self):
# assignment to parameters or buffers is overloaded, updates internal dict entry
self.step = self.step.data.new_tensor(1)
def log(self, path, msg):
with open(path, "a") as f:
print(msg, file=f)
def load(self, path, optimizer=None):
# Use device of model params as location for loaded state
device = next(self.parameters()).device
checkpoint = torch.load(str(path), map_location=device)
self.load_state_dict(checkpoint["model_state"])
if "optimizer_state" in checkpoint and optimizer is not None:
optimizer.load_state_dict(checkpoint["optimizer_state"])
def save(self, path, optimizer=None):
if optimizer is not None:
torch.save({
"model_state": self.state_dict(),
"optimizer_state": optimizer.state_dict(),
}, str(path))
else:
torch.save({
"model_state": self.state_dict(),
}, str(path))
def num_params(self, print_out=True):
parameters = filter(lambda p: p.requires_grad, self.parameters())
parameters = sum([np.prod(p.size()) for p in parameters]) / 1_000_000
if print_out:
print("Trainable Parameters: %.3fM" % parameters)
return parameters
RuntimeError: mat1 and mat2 shapes cannot be multiplied (1788x320 and 512x128)
—can someone guide me with this error?
RuntimeError: mat1 and mat2 shapes cannot be multiplied (10x2048 and 64x2)
I am trying to concat the X,Y and Rag Feature But it is Giving me erorr I have use the simple concat but it is Giving me error I just want to concat the x,y,rag feature in the forward function, can Anyone help me to solve the Problem
How do I fix an error when concatenating x, y, and rag in the forward function using torch.cat, ensuring matching dimensions and device types?
import torch
import torch.nn as nn
import torch.nn.functional as F
class MFB(nn.Module):
def __init__(self,img_feat_size, ques_feat_size, is_first, MFB_K, MFB_O, DROPOUT_R):
super(MFB, self).__init__()
#self.__C = __C
self.MFB_K = MFB_K
self.MFB_O = MFB_O
self.DROPOUT_R = DROPOUT_R
self.is_first = is_first
self.proj_i = nn.Linear(img_feat_size, MFB_K * MFB_O)
self.proj_q = nn.Linear(ques_feat_size, MFB_K * MFB_O)
self.dropout = nn.Dropout(DROPOUT_R)
self.pool = nn.AvgPool1d(MFB_K, stride = MFB_K)
def forward(self, img_feat, ques_feat, exp_in=1):
batch_size = img_feat.shape[0]
img_feat = self.proj_i(img_feat) # (N, C, K*O)
ques_feat = self.proj_q(ques_feat) # (N, 1, K*O)
exp_out = img_feat * ques_feat # (N, C, K*O)
exp_out = self.dropout(exp_out) if self.is_first else self.dropout(exp_out * exp_in) # (N, C, K*O)
z = self.pool(exp_out) * self.MFB_K # (N, C, O)
z = torch.sqrt(F.relu(z)) - torch.sqrt(F.relu(-z))
z = F.normalize(z.view(batch_size, -1)) # (N, C*O)
z = z.view(batch_size, -1, self.MFB_O) # (N, C, O)
return z
#MFB -> Multimodal Factorized Bilinear Pooling
#used to model complex interactions between features like image and text
#MFB_K -> Number Of factors, MFB_O -> Output size,
#Init initializes linear projection layers for image and question features , dropout layer and average pooling layer
#Forward:
#exp_in = input expansion factor (default - 1)
#Linear projection of image and question features to factorized bilinear form
#Element-wise multiplication of image and question features
#APply Dropout
#Average pooling along the factorized dimension (MFB_K) to reduce the size of the output tensor
#Element-wise operations to compute the final output (z) using square root and normalization using Relu.
#The final output represents the fused representation of image and question features.
data = data[~data['Name'].isin(outliers)]
len(sample_dataset_new)
torch.manual_seed(123)
t_p,v_p = torch.utils.data.random_split(sample_dataset_new,[450,50])
# torch.manual_seed(123)
t_p,te_p = torch.utils.data.random_split(t_p,[340,110])
t_p[1]["processed_img"].shape
t_p[1]['processed_txt'].shape
t_p[1]['processed_rag'].shape
(768,)
class Classifier(pl.LightningModule):
def __init__(self):
super().__init__()
self.MFB = MFB(512,768,True,256,64,0.1)
self.fin_y_shape = torch.nn.Linear(768,512)
self.fin_old = torch.nn.Linear(64,2)
self.fin = torch.nn.Linear(16 * 768, 64)
self.fin_inten = torch.nn.Linear(2048,6)
self.fin_e1 = torch.nn.Linear(64,2)
self.fin_e2 = torch.nn.Linear(64,2)
self.fin_e3 = torch.nn.Linear(64,2)
self.fin_e4 = torch.nn.Linear(64,2)
self.fin_e5 = torch.nn.Linear(64,2)
self.fin_e6 = torch.nn.Linear(64,2)
self.fin_e7 = torch.nn.Linear(64,2)
self.fin_e8 = torch.nn.Linear(64,2)
self.fin_e9 = torch.nn.Linear(64,2)
# self.reduce_x = torch.nn.Linear(768, 512)
# self.reduce_rag = torch.nn.Linear(768, 512)
self.validation_step_outputs = []
self.test_step_outputs = []
def forward(self, x,y,rag):
x_,y_,rag_ = x,y,rag
print("x.shape", x.shape)
print("y.shape",y.shape)
print("rag.shape",rag.shape)
# x = self.reduce_x(x)
# rag = self.reduce_rag(rag)
# print("x.shape", x.shape)
# print("y.shape",y.shape)
# print("rag.shape",rag.shape)
# z = self.MFB(torch.unsqueeze(y, axis=1), torch.unsqueeze(rag, axis=1))
# z_rag = self.MFB(torch.unsqueeze(y, axis=1),torch.unsqueeze(rag, axis=1))
# z_con = torch.cat((z, z_rag), dim=1)
# Concatenate x with y and then with rag
z= torch.cat((torch.cat((x, y), dim=1), rag), dim=1)
# Pass concatenated x with y and x with rag through your network
z_new = torch.squeeze(z,dim=1)
print("z_new shape",z_new)
c_inten = self.fin_inten(z_new)
c_e1 = self.fin_e1(z_new)
c_e2 = self.fin_e2(z_new)
c_e3 = self.fin_e3(z_new)
c_e4 = self.fin_e4(z_new)
c_e5 = self.fin_e5(z_new)
c_e6 = self.fin_e6(z_new)
c_e7 = self.fin_e7(z_new)
c_e8 = self.fin_e8(z_new)
c_e9 = self.fin_e9(z_new)
c = self.fin_old(z_new)
# print("z.shape",z.shape)
# print("z_new shape",z_new.shape)
# print("intensity error:", c_inten.shape)
# print("output:", c.shape)
# print("c_e1:", c_e1.shape)
# print("c_e2:", c_e2.shape)
# print("c_e3:", c_e3.shape)
# print("c_e4:", c_e4.shape)
# print("c_e5:", c_e5.shape)
# print("c_e6:", c_e6.shape)
# print("c_e7:", c_e7.shape)
# print("c_e8:", c_e8.shape)
# print("c_e9:", c_e9.shape)
# print("logits.shape",logits.shape)
output = torch.log_softmax(c, dim=1)
c_inten = torch.log_softmax(c_inten, dim=1)
c_e1 = torch.log_softmax(c_e1, dim=1)
c_e2 = torch.log_softmax(c_e2, dim=1)
c_e3 = torch.log_softmax(c_e3, dim=1)
c_e4 = torch.log_softmax(c_e4, dim=1)
c_e5 = torch.log_softmax(c_e5, dim=1)
c_e6 = torch.log_softmax(c_e6, dim=1)
c_e7 = torch.log_softmax(c_e7, dim=1)
c_e8 = torch.log_softmax(c_e8, dim=1)
c_e9 = torch.log_softmax(c_e9, dim=1)
return output,c_inten,c_e1,c_e2,c_e3,c_e4,c_e5,c_e6,c_e7,c_e8,c_e9
def cross_entropy_loss(self, logits, labels):
print("logits.shape",logits.shape)
return F.nll_loss(logits, labels)
def training_step(self, train_batch, batch_idx):
#lab,txt,rag,img,name,per,iro,alli,ana,inv,meta,puns,sat,hyp= train_batch
lab,txt,rag,img,name,intensity,e1,e2,e3,e4,e5,e6,e7,e8,e9= train_batch
#logit_offen,a,b,c,d,e,f,g,h,i,logit_inten_target= self.forward(txt,img,rag)
lab = train_batch[lab].unsqueeze(1)
#print(lab)
txt = train_batch[txt]
rag = train_batch[rag]
img = train_batch[img]
name= train_batch[name]
intensity = train_batch[intensity].unsqueeze(1)
e1 = train_batch[e1].unsqueeze(1)
e2 = train_batch[e2].unsqueeze(1)
e3 = train_batch[e3].unsqueeze(1)
e4 = train_batch[e4].unsqueeze(1)
e5 = train_batch[e5].unsqueeze(1)
e6 = train_batch[e6].unsqueeze(1)
e7 = train_batch[e7].unsqueeze(1)
e8 = train_batch[e8].unsqueeze(1)
e9 = train_batch[e9].unsqueeze(1)
lab = F.one_hot(lab, num_classes=2)
intensity = torch.abs(intensity)
intensity = F.one_hot(intensity, num_classes=6) # Assuming you have 6 classes
e1 = F.one_hot(e1,num_classes = 2)
e2 = F.one_hot(e2,num_classes = 2)
e3 = F.one_hot(e3,num_classes = 2)
e4 = F.one_hot(e4,num_classes = 2)
e5 = F.one_hot(e5,num_classes = 2)
e6 = F.one_hot(e6,num_classes = 2)
e7 = F.one_hot(e7,num_classes = 2)
e8 = F.one_hot(e8,num_classes = 2)
e9 = F.one_hot(e9,num_classes = 2)
lab = lab.squeeze(dim=1)
intensity = intensity.squeeze(dim=1)
e1 = e1.squeeze(dim=1)
e2 = e2.squeeze(dim=1)
e3 = e3.squeeze(dim=1)
e4 = e4.squeeze(dim=1)
e5 = e5.squeeze(dim=1)
e6 = e6.squeeze(dim=1)
e7 = e7.squeeze(dim=1)
e8 = e8.squeeze(dim=1)
e9 = e9.squeeze(dim=1)
logit_offen,logit_inten_target,a,b,c,d,e,f,g,h,i= self.forward(txt,img,rag)
loss1 = self.cross_entropy_loss(logit_offen, lab)
loss17 = self.cross_entropy_loss(logit_inten_target, intensity)
loss4 = self.cross_entropy_loss(a, e1)
loss5 = self.cross_entropy_loss(b, e2)
loss6 = self.cross_entropy_loss(c, e3)
loss7 = self.cross_entropy_loss(d, e4)
loss8 = self.cross_entropy_loss(e, e5)
loss9 = self.cross_entropy_loss(f, e6)
loss10 = self.cross_entropy_loss(g, e7)
loss11 = self.cross_entropy_loss(h, e8)
loss12 = self.cross_entropy_loss(i, e9)
loss = loss1 + loss4 + loss5 + loss6 + loss7 + loss8 +loss9 + loss10 +loss11 +loss12 + loss17
self.log('train_loss', loss)
return loss
def validation_step(self, val_batch, batch_idx):
#lab,txt,rag,img,name,per,iro,alli,ana,inv,meta,puns,sat,hyp = val_batch
lab,txt,rag,img,name,intensity,e1,e2,e3,e4,e5,e6,e7,e8,e9= val_batch
lab = val_batch[lab].unsqueeze(1)
#print(lab)
txt = val_batch[txt]
rag = val_batch[rag]
img = val_batch[img]
name = val_batch[name]
intensity = val_batch[intensity].unsqueeze(1)
e1 = val_batch[e1].unsqueeze(1)
e2 = val_batch[e2].unsqueeze(1)
e3 = val_batch[e3].unsqueeze(1)
e4 = val_batch[e4].unsqueeze(1)
e5 = val_batch[e5].unsqueeze(1)
e6 = val_batch[e6].unsqueeze(1)
e7 = val_batch[e7].unsqueeze(1)
e8 = val_batch[e8].unsqueeze(1)
e9 = val_batch[e9].unsqueeze(1)
lab = F.one_hot(lab, num_classes=2)
intensity = torch.abs(intensity)
intensity = F.one_hot(intensity, num_classes=6)
e1 = F.one_hot(e1,num_classes = 2)
e2 = F.one_hot(e2,num_classes = 2)
e3 = F.one_hot(e3,num_classes = 2)
e4 = F.one_hot(e4,num_classes = 2)
e5 = F.one_hot(e5,num_classes = 2)
e6 = F.one_hot(e6,num_classes = 2)
e7 = F.one_hot(e7,num_classes = 2)
e8 = F.one_hot(e8,num_classes = 2)
e9 = F.one_hot(e9,num_classes = 2)
lab = lab.squeeze(dim=1)
intensity = intensity.squeeze(dim = 1)
e1 = e1.squeeze(dim=1)
e2 = e2.squeeze(dim=1)
e3 = e3.squeeze(dim=1)
e4 = e4.squeeze(dim=1)
e5 = e5.squeeze(dim=1)
e6 = e6.squeeze(dim=1)
e7 = e7.squeeze(dim=1)
e8 = e8.squeeze(dim=1)
e9 = e9.squeeze(dim=1)
logits,inten,a,b,c,d,e,f,g,h,i = self.forward(txt,img,rag)
logits=logits.float()
tmp = np.argmax(logits.detach().cpu().numpy(),axis=1)
loss = self.cross_entropy_loss(logits, lab)
lab = lab.detach().cpu().numpy()
self.log('val_acc', accuracy_score(lab,tmp))
self.log('val_roc_auc',roc_auc_score(lab,tmp))
self.log('val_loss', loss)
tqdm_dict = {'val_acc': accuracy_score(lab,tmp)}
self.validation_step_outputs.append({'progress_bar': tqdm_dict,'val_f1 offensive': f1_score(lab,tmp,average='macro')})
return {
'progress_bar': tqdm_dict,
'val_f1 offensive': f1_score(lab,tmp,average='macro')
}
def on_validation_epoch_end(self):
outs = []
outs14=[]
for out in self.validation_step_outputs:
outs.append(out['progress_bar']['val_acc'])
outs14.append(out['val_f1 offensive'])
self.log('val_acc_all_offn', sum(outs)/len(outs))
self.log('val_f1 offensive', sum(outs14)/len(outs14))
print(f'***val_acc_all_offn at epoch end {sum(outs)/len(outs)}****')
print(f'***val_f1 offensive at epoch end {sum(outs14)/len(outs14)}****')
self.validation_step_outputs.clear()
def test_step(self, batch, batch_idx):
lab,txt,rag,img,name,intensity,e1,e2,e3,e4,e5,e6,e7,e8,e9= batch
lab = batch[lab].unsqueeze(1)
#print(lab)
txt = batch[txt]
rag = batch[rag]
img = batch[img]
name = batch[name]
intensity = batch[intensity].unsqueeze(1)
e1 = batch[e1].unsqueeze(1)
e2 = batch[e2].unsqueeze(1)
e3 = batch[e3].unsqueeze(1)
e4 = batch[e4].unsqueeze(1)
e5 = batch[e5].unsqueeze(1)
e6 = batch[e6].unsqueeze(1)
e7 = batch[e7].unsqueeze(1)
e8 = batch[e8].unsqueeze(1)
e9 = batch[e9].unsqueeze(1)
lab = F.one_hot(lab, num_classes=2)
intensity = F.one_hot(intensity, num_classes=6)
e1 = F.one_hot(e1,num_classes = 2)
e2 = F.one_hot(e2,num_classes = 2)
e3 = F.one_hot(e3,num_classes = 2)
e4 = F.one_hot(e4,num_classes = 2)
e5 = F.one_hot(e5,num_classes = 2)
e6 = F.one_hot(e6,num_classes = 2)
e7 = F.one_hot(e7,num_classes = 2)
e8 = F.one_hot(e8,num_classes = 2)
e9 = F.one_hot(e9,num_classes = 2)
lab = lab.squeeze(dim=1)
intensity = intensity.squeeze(dim=1)
e1 = e1.squeeze(dim=1)
e2 = e2.squeeze(dim=1)
e3 = e3.squeeze(dim=1)
e4 = e4.squeeze(dim=1)
e5 = e5.squeeze(dim=1)
e6 = e6.squeeze(dim=1)
e7 = e7.squeeze(dim=1)
e8 = e8.squeeze(dim=1)
e9 = e9.squeeze(dim=1)
logits,inten,a,b,c,d,e,f,g,h,i= self.forward(txt,img,rag)
logits = logits.float()
tmp = np.argmax(logits.detach().cpu().numpy(force=True),axis=-1)
loss = self.cross_entropy_loss(logits, lab)
lab = lab.detach().cpu().numpy()
self.log('test_acc', accuracy_score(lab,tmp))
self.log('test_roc_auc',roc_auc_score(lab,tmp))
self.log('test_loss', loss)
tqdm_dict = {'test_acc': accuracy_score(lab,tmp)}
self.test_step_outputs.append({'progress_bar': tqdm_dict,'test_acc': accuracy_score(lab,tmp), 'test_f1_score': f1_score(lab,tmp,average='macro')})
return {
'progress_bar': tqdm_dict,
'test_acc': accuracy_score(lab,tmp),
'test_f1_score': f1_score(lab,tmp,average='macro')
}
def on_test_epoch_end(self):
# OPTIONAL
outs = []
outs1,outs2,outs3,outs4,outs5,outs6,outs7,outs8,outs9,outs10,outs11,outs12,outs13,outs14 = \
[],[],[],[],[],[],[],[],[],[],[],[],[],[]
for out in self.test_step_outputs:
outs.append(out['test_acc'])
outs2.append(out['test_f1_score'])
self.log('test_acc', sum(outs)/len(outs))
self.log('test_f1_score', sum(outs2)/len(outs2))
self.test_step_outputs.clear()
def configure_optimizers(self):
# optimizer = torch.optim.Adam(self.parameters(), lr=3e-2)
optimizer = torch.optim.Adam(self.parameters(), lr=1e-5)
return optimizer
"""
Main Model:
Initialize
Forward Pass
Training Step
Validation Step
Testing Step
Pp
"""
class HmDataModule(pl.LightningDataModule):
def setup(self, stage):
self.hm_train = t_p
self.hm_val = v_p
# self.hm_test = test
self.hm_test = te_p
def train_dataloader(self):
return DataLoader(self.hm_train, batch_size=10, drop_last=True)
def val_dataloader(self):
return DataLoader(self.hm_val, batch_size=10, drop_last=True)
def test_dataloader(self):
return DataLoader(self.hm_test, batch_size=10, drop_last=True)
data_module = HmDataModule()
checkpoint_callback = ModelCheckpoint(
monitor='val_acc_all_offn',
dirpath='mrinal/',
filename='epoch{epoch:02d}-val_f1_all_offn{val_acc_all_offn:.2f}',
auto_insert_metric_name=False,
save_top_k=1,
mode="max",
)
all_callbacks = []
all_callbacks.append(checkpoint_callback)
# train
from pytorch_lightning import seed_everything
seed_everything(42, workers=True)
hm_model = Classifier()
gpus=1
#if torch.cuda.is_available():gpus=0
trainer = pl.Trainer(deterministic=True,max_epochs=10,precision=16,callbacks=all_callbacks)
trainer.fit(hm_model, data_module)
INFO:lightning_fabric.utilities.seed:Seed set to 42
/usr/local/lib/python3.10/dist-packages/lightning_fabric/connector.py:563: `precision=16` is supported for historical reasons but its usage is discouraged. Please set your precision to 16-mixed instead!
/usr/local/lib/python3.10/dist-packages/pytorch_lightning/trainer/connectors/accelerator_connector.py:556: You passed `Trainer(accelerator='cpu', precision='16-mixed')` but AMP with fp16 is not supported on CPU. Using `precision='bf16-mixed'` instead.
INFO:pytorch_lightning.utilities.rank_zero:Using bfloat16 Automatic Mixed Precision (AMP)
INFO:pytorch_lightning.utilities.rank_zero:GPU available: False, used: False
INFO:pytorch_lightning.utilities.rank_zero:TPU available: False, using: 0 TPU cores
INFO:pytorch_lightning.utilities.rank_zero:IPU available: False, using: 0 IPUs
INFO:pytorch_lightning.utilities.rank_zero:HPU available: False, using: 0 HPUs
WARNING:pytorch_lightning.loggers.tensorboard:Missing logger folder: /content/LLaVA/lightning_logs
INFO:pytorch_lightning.callbacks.model_summary:
| Name | Type | Params
----------------------------------------
0 | MFB | MFB | 21.0 M
1 | fin_y_shape | Linear | 393 K
2 | fin_old | Linear | 130
3 | fin | Linear | 786 K
4 | fin_inten | Linear | 12.3 K
5 | fin_e1 | Linear | 130
6 | fin_e2 | Linear | 130
7 | fin_e3 | Linear | 130
8 | fin_e4 | Linear | 130
9 | fin_e5 | Linear | 130
10 | fin_e6 | Linear | 130
11 | fin_e7 | Linear | 130
12 | fin_e8 | Linear | 130
13 | fin_e9 | Linear | 130
----------------------------------------
22.2 M Trainable params
0 Non-trainable params
22.2 M Total params
88.792 Total estimated model params size (MB)
Sanity Checking DataLoader 0: 0%
0/2 [00:00<?, ?it/s]
x.shape torch.Size([10, 768])
y.shape torch.Size([10, 512])
rag.shape torch.Size([10, 768])
z_new shape tensor([[ 0.0144, -0.1677, 0.1100, ..., -0.1818, 0.4250, -0.2985],
[-0.2105, -0.1002, -0.0113, ..., -0.0639, 0.3789, -0.0553],
[-0.1221, -0.1026, -0.3277, ..., -0.3724, 0.1562, 0.0286],
...,
[-0.0950, 0.3957, 0.3603, ..., -0.2121, 0.6465, -0.1983],
[ 0.0080, 0.2380, -0.0409, ..., -0.2565, 0.0946, -0.1098],
[ 0.1351, -0.3463, 0.3371, ..., -0.2283, 0.4667, 0.0087]])
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<ipython-input-29-279b4c8e1163> in <cell line: 369>()
367 #if torch.cuda.is_available():gpus=0
368 trainer = pl.Trainer(deterministic=True,max_epochs=10,precision=16,callbacks=all_callbacks)
--> 369 trainer.fit(hm_model, data_module)
14 frames
/usr/local/lib/python3.10/dist-packages/torch/nn/modules/linear.py in forward(self, input)
112
113 def forward(self, input: Tensor) -> Tensor:
--> 114 return F.linear(input, self.weight, self.bias)
115
116 def extra_repr(self) -> str:
RuntimeError: mat1 and mat2 shapes cannot be multiplied (10x2048 and 64x2)
Double post from here.
Hi, I’m getting the following error. I believe it’s from my input and output shapes mismatching like the others in this thread but I am confused on what to change them to. My x_train_tensor.shape is 1117157, 8, train_dataloader is 32, 8, and net.fc1.weight.shape is 50, 1117157.
RuntimeError: mat1 and mat2 shapes cannot be multiplied (32x8 and 1117157x50)
class NetFc(nn.Module):
def __init__(self):
super(NetFc, self).__init__()
self.fc1 = nn.Linear(x_train_tensor.shape[0], 50)
self.fc2 = nn.Linear(50, 50)
self.fc3 = nn.Linear(50, 50)
self.fc4 = nn.Linear(50, 50)
self.fc5 = nn.Linear(50, 50)
self.fc6 = nn.Linear(50, 50)
self.fc7 = nn.Linear(50, 50)
self.fc8 = nn.Linear(50, y_train_tensor.shape[0])
def forward(self, x):
x = torch.flatten(x, 1)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = F.relu(self.fc3(x))
x = F.relu(self.fc4(x))
x = F.relu(self.fc5(x))
x = F.relu(self.fc6(x))
x = F.relu(self.fc7(x))
x = self.fc8(x)
#Softmax layer should always be last
output = F.log_softmax(x, dim=1)
# Return the output of the network
return output
def trainMyModel(net,lr,train_dataloader,n_epochs):
# define loss and optimizer
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=lr)
for epoch in range(n_epochs): # loop over number of epochs
running_loss = 0.0
for data, target in train_dataloader:
optimizer.zero_grad() # zero gradient buffers
outputs = net(data.float()) # forward prop
loss = criterion(outputs, target) # calculate loss
loss.backward() # backward prop
optimizer.step() # optimize
# print statistics
running_loss += loss.item()
if i % 100 == 99: # print every 100 mini-batches
print(f'[{epoch + 1}, {i +1:5d}] loss: {running_loss / 100:.3f}')
running_loss = 0.0
print('Finished Training')
return net
# Train your model.
net = NetFc();
lr = 1e-2;
n_epochs = 2;
trainedNet = trainMyModel(net,lr,train_dataloader,n_epochs);