You are initializing the input features of the first linear layer with the number of samples:
self.fc1 = nn.Linear(x_train_tensor.shape[0], 50)
Use x_train_tensor.shape[1] and it should work as dim1 should correspond to the feature dimension.
You are initializing the input features of the first linear layer with the number of samples:
self.fc1 = nn.Linear(x_train_tensor.shape[0], 50)
Use x_train_tensor.shape[1] and it should work as dim1 should correspond to the feature dimension.
Hi,
I have this model architecture:
import torch
import torch.nn as nn
nz = 100 # Size of the latent vector
class netG(nn.Module):
def init(self, nz, ngf, nc):
super(netG, self).init()
self.main = nn.Sequential(
# Input: (nz, 1, 1)
nn.ConvTranspose2d(nz, ngf * 8, 4, 1, 0, bias=False),
nn.LayerNorm([ngf * 8, 4, 4]),
nn.ReLU(True),
# Output: (ngf * 8, 4, 4)
nn.ConvTranspose2d(ngf * 8, ngf * 4, 4, 2, 1, bias=False),
nn.LayerNorm([ngf * 4, 8, 8]),
nn.ReLU(True),
# Output: (ngf * 4, 8, 8)
nn.ConvTranspose2d(ngf * 4, ngf * 2, 4, 2, 1, bias=False),
nn.LayerNorm([ngf * 2, 16, 16]),
nn.ReLU(True),
# Output: (ngf * 2, 16, 16)
nn.ConvTranspose2d(ngf * 2, ngf, 4, 2, 1, bias=False),
nn.LayerNorm([ngf, 32, 32]),
nn.ReLU(True),
# Output: (ngf, 32, 32)
nn.ConvTranspose2d(ngf, nc, 4, 2, 1, bias=False),
nn.Tanh()
# Output: (nc, 64, 64)
)
def forward(self, input):
print(f"Input shape: {input.shape}")
x = self.main(input)
print(f"Output shape: {x.shape}")
return x
class netD(nn.Module):
def init(self, ndf, nc, nb_label):
super(netD, self).init()
self.main = nn.Sequential(
# Input: (nc, 64, 64)
nn.Conv2d(nc, ndf, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
nn.Dropout2d(0.25),
# Output: (ndf, 32, 32)
nn.Conv2d(ndf, ndf * 2, 4, 2, 1, bias=False),
nn.GroupNorm(num_groups=4, num_channels=ndf * 2),
nn.LeakyReLU(0.2, inplace=True),
nn.Dropout2d(0.25),
# Output: (ndf * 2, 16, 16)
nn.Conv2d(ndf * 2, ndf * 4, 4, 2, 1, bias=False),
nn.GroupNorm(num_groups=8, num_channels=ndf * 4),
nn.LeakyReLU(0.2, inplace=True),
nn.Dropout2d(0.25),
# Output: (ndf * 4, 8, 8)
nn.Conv2d(ndf * 4, ndf * 8, 4, 2, 1, bias=False),
nn.GroupNorm(num_groups=16, num_channels=ndf * 8),
nn.LeakyReLU(0.2, inplace=True),
nn.Dropout2d(0.25),
# Output: (ndf * 8, 4, 4)
nn.Conv2d(ndf * 8, ndf, 4, 1, 0, bias=False),
# Output: (ndf, 1, 1)
nn.Flatten(),
nn.Linear(ndf, 1),
nn.Sigmoid(),
nn.Linear(ndf, nb_label),
nn.Softmax(dim=1)
)
def forward(self, input):
print(f"Input shape: {input.shape}")
x = self.main(input)
output = x[:, :1]
aux_output = x[:, 1:]
print(f"Output shape: {output.shape}")
print(f"Aux output shape: {aux_output.shape}")
return output, aux_output
def weights_init(m):
classname = m.class.name
if classname.find(‘Conv’) != -1:
m.weight.data.normal_(0.0, 0.02)
elif classname.find(‘BatchNorm’) != -1:
m.weight.data.normal_(1.0, 0.02)
m.bias.data.fill_(0)
elif classname.find(‘GroupNorm’) != -1:
m.weight.data.normal_(1.0, 0.02)
m.bias.data.fill_(0)
elif classname.find(‘Linear’) != -1:
m.weight.data.normal_(0.0, 0.02)
m.bias.data.fill_(0)
and I am getting this error:
Traceback (most recent call last):
File “/root/cifar10_experiments/serveradv.py”, line 181, in
server.run()
File “/root/cifar10_experiments/serveradv.py”, line 122, in run
client_weights_d, client_weights_g, _, _ = client.client_training()
File “/root/cifar10_experiments/clientadv.py”, line 111, in client_training
perturbed_data = fgsm_attack(self.discriminator, img, real_labels, 0.01, self.s_criterion, attack_output_idx=0)
File “/root/cifar10_experiments/adversarial_utils.py”, line 22, in fgsm_attack
outputs = model(data)
File “/root/cifar10_experiments/venv/lib/python3.10/site-packages/torch/nn/modules/module.py”, line 1532, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
File “/root/cifar10_experiments/venv/lib/python3.10/site-packages/torch/nn/modules/module.py”, line 1541, in _call_impl
return forward_call(*args, **kwargs)
File “/root/cifar10_experiments/model_GAN3.py”, line 82, in forward
x = self.main(input)
File “/root/cifar10_experiments/venv/lib/python3.10/site-packages/torch/nn/modules/module.py”, line 1532, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
File “/root/cifar10_experiments/venv/lib/python3.10/site-packages/torch/nn/modules/module.py”, line 1541, in _call_impl
return forward_call(*args, **kwargs)
File “/root/cifar10_experiments/venv/lib/python3.10/site-packages/torch/nn/modules/container.py”, line 217, in forward
input = module(input)
File “/root/cifar10_experiments/venv/lib/python3.10/site-packages/torch/nn/modules/module.py”, line 1532, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
File “/root/cifar10_experiments/venv/lib/python3.10/site-packages/torch/nn/modules/module.py”, line 1541, in _call_impl
return forward_call(*args, **kwargs)
File “/root/cifar10_experiments/venv/lib/python3.10/site-packages/torch/nn/modules/linear.py”, line 116, in forward
return F.linear(input, self.weight, self.bias)
RuntimeError: mat1 and mat2 shapes cannot be multiplied (16x1 and 64x10)
Your code is hard to read as it’s not properly formatted, but I would guess the issue is caused in nn.Linear(ndf, nb_label) since the previous layer outputs an activation with a single feature nn.Linear(ndf, 1) while the next one expects an activation with ndf features.
class A(nn.Module):
def init(self):
super().init()
self.intro_bn = nn.BatchNorm1d(32)
self.C11 = nn.Conv1d(32, 32, kernel_size=5, padding=2)
self.A11 = nn.ReLU()
self.C12 = nn.Conv1d(32, 32, kernel_size=5, padding=2)
self.A12 = nn.ReLU()
self.M11 = nn.MaxPool1d(kernel_size=5, stride=2)
def forward(self, x):
x = self.intro_bn(x)
C = x
x = self.C11(x)
x = self.A11(x)
x = self.C12(x)
x = x + C
x = self.A12(x)
x = self.M11(x)
return x
class Model(nn.Module):
def init(self):
super().init()
self.conv_in = nn.Conv1d(1, 32, kernel_size=5)
self.A_blocks = nn.ModuleList(A() for i in range(5))
self.avg_pool = nn.AvgPool1d(2)
self.fc1 = nn.Linear(32,32)
self.acc1 = nn.ReLU()
self.fc2 = nn.Linear(32,5)
def forward(self, x):
x = self.conv_in(x)
for i in range(5):
x = self.A_blocks[i](x)
x = self.avg_pool(x)
x = x.view(x.shape[0], -1)
x = self.fc1(x)
x = self.acc1(x)
x = self.fc2(x)
return x
i am facing the issue for the when i m doing the
It’s unclear what’s failing as you did not post any errors and your code is also not properly formatted.
In any case, check if self.fc1 is failing and adapt its in_features as described in previous posts in this topic.
Hi @ptrblck … I am getting similar error …Could you please guide me in the below problem
I am running FL setup on SVHN dataset and having error :RuntimeError: mat1 and mat2 shapes cannot be multiplied (32768x3 and 20480*2048
)
My sample input shape is : (32, 32, 3) with 10 outputs and I am running it on model:
class Net(nn.Module):
def init(self):
super(Net, self).init()
self.fc1 = nn.Linear(32,2048)
self.fc2 = nn.Linear(2048,64)
self.fc3 = nn.Linear(64,10)
self.dropout = nn.Dropout(0.10)
def forward(self, x):
x = self.fc1(x)
x = F.relu(x)
print(“x.shape”,x.shape)
x = self.dropout(x)
x = self.fc2(x)
x = F.relu(x)
x = self.fc3(x)
x = F.relu(x)
output = F.log_softmax(x, dim=-1)
return output
nn.Linear layers expect the feature dimension of the activation to be the last dimension, so 3 in your case of using an input in the shape [32, 32, 3]. I’m not familiar with your use case and don’t know if you want to pass a 3D tensor to these layers, but you should either permute the tensor or flatten it.
Could you describe what the input tensor represents? If it’s an image tensor, you might want to flatten it.
Thanks @ptrblck …
Its a image tensor and I have added conv layers to the model and now i am getting another error: *Given groups=1, weight of size [32, 3, 3, 3], expected input[64, 32, 32, 3] to have 3 channels, but got 32 channels instead. The input is zip object of dataloader_images and dataloader_labels of svhn dataset.
The model is:
class Net(nn.Module):
def init(self):
super(Net, self).init()
self.conv1 = nn.Conv2d(3, 32, kernel_size=3, stride=2, padding=1)
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, stride=2, padding=1)
self.conv3 = nn.Conv2d(64, 128, kernel_size=3, stride=2, padding=1)
# self.dropout1 = nn.Dropout2d(0.25)
self.fc1 = nn.Linear(2048, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.conv2(x)
x = F.relu(x)
x = self.conv3(x)
x = F.relu(x)
# x = self.dropout1(x)
x = torch.flatten(x, 1)
x = self.fc1(x)
x = F.relu(x)
x = self.fc2(x)
output = F.log_softmax(x, dim=1)
return output
You would have to permute the input to create the channels-first memory layout as currently your input is in channels-last.
I am learning this for the first time I did apply permute but it failed again.
Below is the configuration of my dataset and I am passing the zip object to the Net model as shown below … Could you please guide me here.
x_train_full = train_images[0:tot_used_for_training]
y_train_full = Y_train[0:tot_used_for_training]
x_test_full = test_images[0:tot_used_for_testing]
y_test_full = Y_test[0:tot_used_for_testing]
x_train_partitions = np.array_split(x_train_full, num_of_clients)
y_train_partitions = np.array_split(y_train_full, num_of_clients)
tensor_x_train.append((torch.tensor(x_train_partitions[i])).type(torch.FloatTensor))
y_train_reverse_onehot = np.array( [ np.argmax ( y, axis=None, out=None ) for y in y_train_partitions[i] ] )
tensor_y_train.append((torch.tensor(y_train_reverse_onehot)).type(torch.LongTensor))
for i in client_idx:
dataloaders_train = torch.utils.data.DataLoader(tensor_x_train[i], batch_size=64)
dataloaders_labels= torch.utils.data.DataLoader(tensor_y_train[i], batch_size=64)
[loss,acc]= fl.client_update(client_models[i], opt[i], zip(dataloaders_train, dataloaders_labels), epoch=epochs
Assuming tensor_x_train[i] contains image tensors in channels-last layout (and its shape is [batch_size, height, width, channels]), use tensor_x_train[i].permute(0, 3, 1, 2) to transform it to channels-first layout in the shape [batch_size, channels, height, width].
Thanks @ptrblck …although the workaround worked perfectly fine but I had got a very low accuracy with that model I am working on svhn dataset and now using the below model…
def init(self):
super(Net, self).init():
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(32x16x5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
print(x.shape)
x = x.view(-1, 32 * 16 * 5)
# x = x.view(x.size(0),-1)
print(x.shape)
x = F.relu(self.fc1(x))
print(x.shape)
print(x.shape)
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
Now I am getting error ValueError: Expected input batch_size (10) to match target batch_size (64).
The x. shape along with the shape of output and target in loss function is as follows:
torch.Size([32, 16, 5, 5])
torch.Size([5, 2560])
torch.Size([5, 120])
torch.Size([32, 16, 5, 5])
torch.Size([5, 2560])
torch.Size([5, 120])
torch.Size([10, 10])---- output
torch.Size([64])----target
Could you please help me?
The shapes look wrong from the beginning and the input does not seem to match the target.
Just to recap: nn.Conv2d layers expect an input activation in the shape [batch_size, channels, height, width]. Make sure to permute the tensor if needed and to double check the dimensions are set in the right order.
Using x = x.view(-1, 32 * 16 * 5) can change the batch size, so use x = x.view(x.size(0), -1) instead and fix potential shape mismatches in the next linear layer.
Here the batch size of the input and target does not even match, so check your data loading and make sure the input to the model contains the same number of samples as the target.
Thanks @ptrblck … I figured the error but the model has low efficiency again…Could you please guide me what are the keypoints while deciding the layers and neurons of the model… I am working on svhn dataset for the first time…
class Mlp(nn.Module):
def init(self, in_features, hidden_features=None, act_layer=nn.GELU, drop=0., pred=True):
super().init()
#out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.q = nn.Linear(in_features, in_features)
self.k = nn.Linear(in_features, in_features)
self.v = nn.Linear(in_features, in_features)
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.pred = pred
if pred==True:
self.fc2 = nn.Linear(hidden_features,1)
else:
self.fc2 = nn.Linear(hidden_features, in_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x0 = x
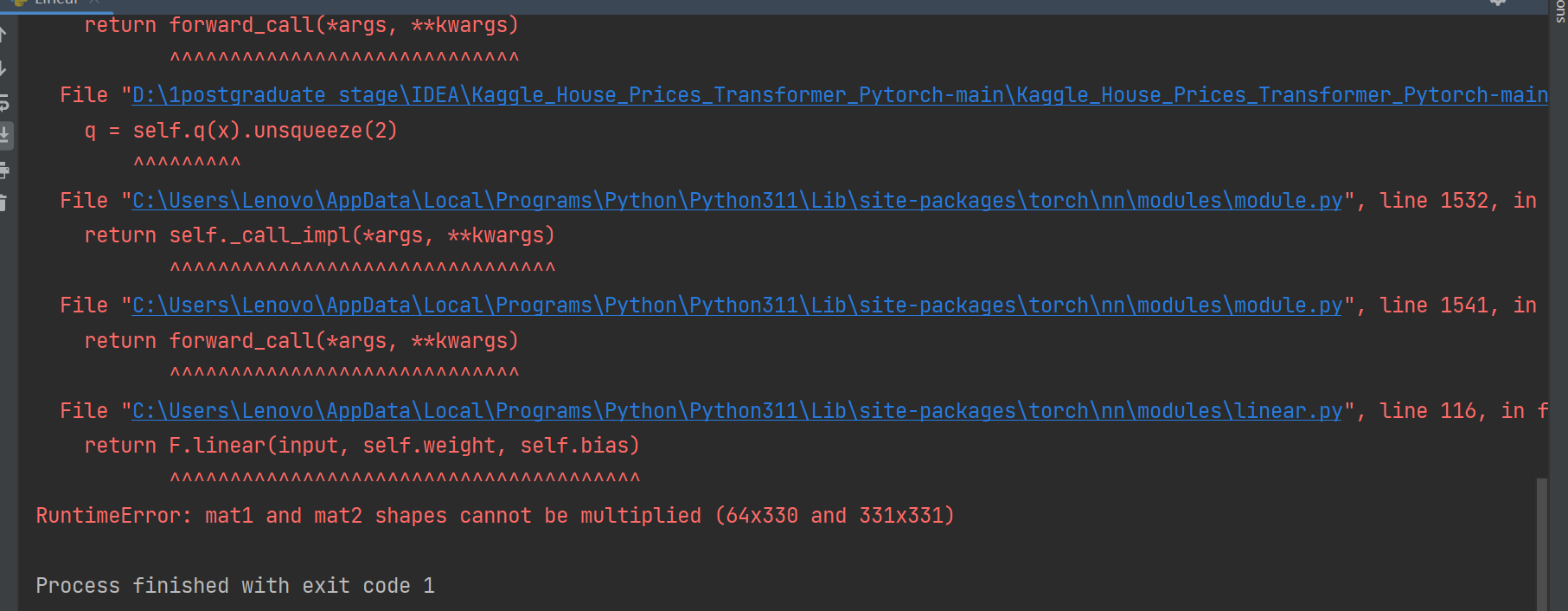
q = self.q(x).unsqueeze(2)
k = self.k(x).unsqueeze(2)
v = self.v(x).unsqueeze(2)
print("Shape of q tensor:", q.shape)
print("Shape of k tensor:", k.shape)
print("Shape of v tensor:", v.shape)
attn = (q @ k.transpose(-2, -1))
#print(attn.size())
attn = attn.softmax(dim=-1)
x = (attn @ v).squeeze(2)
#print(x.size())
x += x0
x1 = x
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
if self.pred==False:
x += x1
x = x.squeeze(0)
return x
class TF(nn.Module):
def init(self, in_features, drop=0.):
super().init()
self.Block1 = Mlp(in_features=in_features, hidden_features=64, act_layer=nn.GELU, drop=drop, pred=False)
# self.Block1_1 = Mlp(in_features=in_features, hidden_features=64, act_layer=nn.GELU, drop=drop, pred=False)
# self.Block1_2 = Mlp(in_features=in_features, hidden_features=64, act_layer=nn.GELU, drop=drop, pred=False)
# self.Block1_3 = Mlp(in_features=in_features, hidden_features=64, act_layer=nn.GELU, drop=drop, pred=False)
# self.Block1_1 = Mlp(in_features=in_features, hidden_features=64, act_layer=nn.GELU, drop=drop, pred=False)
# self.Block1_1 = Mlp(in_features=in_features, hidden_features=64, act_layer=nn.GELU, drop=drop, pred=False)
# self.Block1_1 = Mlp(in_features=in_features, hidden_features=64, act_layer=nn.GELU, drop=drop, pred=False)
self.Block2 = Mlp(in_features=in_features, hidden_features=64, act_layer=nn.GELU, drop=drop, pred=True)
def forward(self, x):
return self.Block2(self.Block1(x))
train_raw = pd.read_csv(‘train.csv’)
test_raw = pd.read_csv(‘test.csv’)
print(train_raw.shape, test_raw.shape)
(1460, 81) (1459, 80)
[/details]
[/spoiler]
i am getting this error,thanks
Hello, I have same problem.
I’ve read other people’s questions and answers, but I don’t quite understand, so I’m asking a question. I also asked a question to chat GPT, but the same error keeps occurring and I don’t know what part to fix.
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision.transforms as transforms
from torch.utils.data import DataLoader, Dataset
from torchvision.models import vit_b_16
import os
from PIL import Image
# Dataset path
data_dir = 'D:\\transformer\\gray_pano'
# Data preprocessing
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
# Load multi-class dataset
class MultiClassDentalDataset(Dataset):
def __init__(self, root_dir, transform=None):
self.root_dir = root_dir
self.transform = transform
self.classes = [d.name for d in os.scandir(root_dir) if d.is_dir()]
self.image_paths = []
self.labels = []
for idx, class_name in enumerate(self.classes):
class_dir = os.path.join(root_dir, class_name)
for img_name in os.listdir(class_dir):
if img_name.endswith('.png') or img_name.endswith('.jpg'):
self.image_paths.append(os.path.join(class_dir, img_name))
self.labels.append(idx)
if not self.image_paths:
raise ValueError(f"No images found in the directory: {root_dir}")
def __len__(self):
return len(self.image_paths)
def __getitem__(self, idx):
img_path = self.image_paths[idx]
image = Image.open(img_path).convert("RGB")
label = self.labels[idx]
if self.transform:
image = self.transform(image)
return image, label
# Define dataset and dataloader
dataset = MultiClassDentalDataset(data_dir, transform)
data_loader = DataLoader(dataset, batch_size=32, shuffle=True)
# Define DCGAN Generator
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.main = nn.Sequential(
nn.ConvTranspose2d(100, 512, 4, 1, 0, bias=False),
nn.BatchNorm2d(512),
nn.ReLU(True),
nn.ConvTranspose2d(512, 256, 4, 2, 1, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(True),
nn.ConvTranspose2d(256, 128, 4, 2, 1, bias=False),
nn.BatchNorm2d(128),
nn.ReLU(True),
nn.ConvTranspose2d(128, 3, 4, 2, 1, bias=False),
nn.Tanh()
)
def forward(self, input):
return self.main(input)
# Define DCGAN Discriminator
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.main = nn.Sequential(
nn.Conv2d(3, 128, 4, 2, 1, bias=False), # (224 - 4 + 2*1) / 2 + 1 = 112
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(128, 256, 4, 2, 1, bias=False), # (112 - 4 + 2*1) / 2 + 1 = 56
nn.BatchNorm2d(256),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(256, 512, 4, 2, 1, bias=False), # (56 - 4 + 2*1) / 2 + 1 = 28
nn.BatchNorm2d(512),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(512, 1024, 4, 2, 1, bias=False), # (28 - 4 + 2*1) / 2 + 1 = 14
nn.BatchNorm2d(1024),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(1024, 1, 4, 2, 1, bias=False), # (14 - 4 + 2*1) / 2 + 1 = 7
nn.Flatten()
)
self.fc = nn.Linear(in_features=49, out_features=1) # Output size after flattening
def forward(self, input):
x = self.main(input)
x = x.view(x.size(0), -1) # Reshape to (batch size, 49)
return torch.sigmoid(self.fc(x))
# Check output size of the discriminator
dummy_input = torch.randn(1, 3, 224, 224)
model = Discriminator()
output = model(dummy_input)
print(output.shape) # Output: torch.Size([1, 1])
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
generator = Generator().to(device)
discriminator = Discriminator().to(device)
# Define loss function and optimizers
criterion = nn.BCELoss()
optimizerG = optim.Adam(generator.parameters(), lr=0.0002, betas=(0.5, 0.999))
optimizerD = optim.Adam(discriminator.parameters(), lr=0.0002, betas=(0.5, 0.999))
# DCGAN training loop
num_epochs = 100
noise_dim = 100
for epoch in range(num_epochs):
for i, (images, _) in enumerate(data_loader):
batch_size = images.size(0)
images = images.to(device)
# Define real and fake labels
real_labels = torch.ones(batch_size, 1, device=device)
fake_labels = torch.zeros(batch_size, 1, device=device)
# Train discriminator
optimizerD.zero_grad()
outputs = discriminator(images)
d_loss_real = criterion(outputs, real_labels)
d_loss_real.backward()
noise = torch.randn(batch_size, noise_dim, 1, 1, device=device)
fake_images = generator(noise)
outputs = discriminator(fake_images.detach())
d_loss_fake = criterion(outputs, fake_labels)
d_loss_fake.backward()
optimizerD.step()
# Train generator
optimizerG.zero_grad()
outputs = discriminator(fake_images)
g_loss = criterion(outputs, real_labels)
g_loss.backward()
optimizerG.step()
print(f'Epoch [{epoch+1}/{num_epochs}], d_loss: {d_loss_real.item() + d_loss_fake.item()}, g_loss: {g_loss.item()}')
same error sentence…
RuntimeError: mat1 and mat2 shapes cannot be multiplied (32x1 and 49x1)
Please help me !!!
Thanks !
Your Generator is not returning the expected activation shape needed by the Discriminator.
While the Discriminator expects an input in the shape [batch_size, 3, 224, 224], the Generator returns an activation in the shape [batch_size, 3, 32, 32].
Thank you for the reply!
I modified the Generator part as shown below, but the numbers have changed, but the same error still occurs.
RuntimeError: mat1 and mat2 shapes cannot be multiplied (32x64 and 49x1)
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision.transforms as transforms
from torch.utils.data import DataLoader, Dataset
import os
from PIL import Image
# Dataset path
data_dir = 'D:\\transformer\\gray_pano'
# Data preprocessing
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
# Load multi-class dataset
class MultiClassDentalDataset(Dataset):
def __init__(self, root_dir, transform=None):
self.root_dir = root_dir
self.transform = transform
self.classes = [d.name for d in os.scandir(root_dir) if d.is_dir()]
self.image_paths = []
self.labels = []
for idx, class_name in enumerate(self.classes):
class_dir = os.path.join(root_dir, class_name)
for img_name in os.listdir(class_dir):
if img_name.endswith('.png') or img_name.endswith('.jpg'):
self.image_paths.append(os.path.join(class_dir, img_name))
self.labels.append(idx)
if not self.image_paths:
raise ValueError(f"No images found in the directory: {root_dir}")
def __len__(self):
return len(self.image_paths)
def __getitem__(self, idx):
img_path = self.image_paths[idx]
image = Image.open(img_path).convert("RGB")
label = self.labels[idx]
if self.transform:
image = self.transform(image)
return image, label
# Define dataset and dataloader
dataset = MultiClassDentalDataset(data_dir, transform)
data_loader = DataLoader(dataset, batch_size=32, shuffle=True)
# Define DCGAN Generator
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.main = nn.Sequential(
nn.ConvTranspose2d(100, 1024, 4, 1, 0, bias=False), # (4x4)
nn.BatchNorm2d(1024),
nn.ReLU(True),
nn.ConvTranspose2d(1024, 512, 4, 2, 1, bias=False), # (8x8)
nn.BatchNorm2d(512),
nn.ReLU(True),
nn.ConvTranspose2d(512, 256, 4, 2, 1, bias=False), # (16x16)
nn.BatchNorm2d(256),
nn.ReLU(True),
nn.ConvTranspose2d(256, 128, 4, 2, 1, bias=False), # (32x32)
nn.BatchNorm2d(128),
nn.ReLU(True),
nn.ConvTranspose2d(128, 64, 4, 2, 1, bias=False), # (64x64)
nn.BatchNorm2d(64),
nn.ReLU(True),
nn.ConvTranspose2d(64, 32, 4, 2, 1, bias=False), # (128x128)
nn.BatchNorm2d(32),
nn.ReLU(True),
nn.ConvTranspose2d(32, 3, 4, 2, 1, bias=False), # (224x224)
nn.Tanh()
)
def forward(self, input):
return self.main(input)
# Define DCGAN Discriminator
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.main = nn.Sequential(
nn.Conv2d(3, 128, 4, 2, 1, bias=False), # (224 - 4 + 2*1) / 2 + 1 = 112
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(128, 256, 4, 2, 1, bias=False), # (112 - 4 + 2*1) / 2 + 1 = 56
nn.BatchNorm2d(256),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(256, 512, 4, 2, 1, bias=False), # (56 - 4 + 2*1) / 2 + 1 = 28
nn.BatchNorm2d(512),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(512, 1024, 4, 2, 1, bias=False), # (28 - 4 + 2*1) / 2 + 1 = 14
nn.BatchNorm2d(1024),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(1024, 1, 4, 2, 1, bias=False), # (14 - 4 + 2*1) / 2 + 1 = 7
nn.Flatten()
)
self.fc = nn.Linear(7 * 7, 1) # Output size after flattening
def forward(self, input):
x = self.main(input)
x = x.view(x.size(0), -1) # Reshape to (batch size, 49)
return torch.sigmoid(self.fc(x))
# Check output size of the discriminator
dummy_input = torch.randn(1, 3, 224, 224)
model = Discriminator()
output = model(dummy_input)
print(output.shape) # Output: torch.Size([1, 1])
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
generator = Generator().to(device)
discriminator = Discriminator().to(device)
# Define loss function and optimizers
criterion = nn.BCELoss()
optimizerG = optim.Adam(generator.parameters(), lr=0.0002, betas=(0.5, 0.999))
optimizerD = optim.Adam(discriminator.parameters(), lr=0.0002, betas=(0.5, 0.999))
# DCGAN training loop
num_epochs = 100
noise_dim = 100
for epoch in range(num_epochs):
for i, (images, _) in enumerate(data_loader):
batch_size = images.size(0)
images = images.to(device)
# Define real and fake labels
real_labels = torch.ones(batch_size, 1, device=device)
fake_labels = torch.zeros(batch_size, 1, device=device)
# Train discriminator
optimizerD.zero_grad()
outputs = discriminator(images)
d_loss_real = criterion(outputs, real_labels)
d_loss_real.backward()
noise = torch.randn(batch_size, noise_dim, 1, 1, device=device)
fake_images = generator(noise)
outputs = discriminator(fake_images.detach())
d_loss_fake = criterion(outputs, fake_labels)
d_loss_fake.backward()
optimizerD.step()
# Train generator
optimizerG.zero_grad()
outputs = discriminator(fake_images)
g_loss = criterion(outputs, real_labels)
g_loss.backward()
optimizerG.step()
print(f'Epoch [{epoch+1}/{num_epochs}], d_loss: {d_loss_real.item() + d_loss_fake.item()}, g_loss: {g_loss.item()}')
The error message also changed and shows the layer now fails with the new shapes, so the generator output is still not in the expected shape of [batch_size, 3, 224, 224].
Hello all. This is my 1st time using PyTorch and I found similar issues. I am trying to implement Multiagent Reinforcement Learning. My error code is:
Traceback (most recent call last):
File “/Users/piao/Documents/Seafile/Seafile/MARL(Python)/main.py”, line 52, in
action_1 = agent_1.act(state_TE)
File “/Users/piao/Documents/Seafile/Seafile/MARL(Python)/MARL/ddpg_agent.py”, line 118, in act
acts[0, :] = self.actor_local(state).cpu().data.numpy()
File “/Users/piao/Documents/PythonProjects/MARL_TEM/venv/lib/python3.9/site-packages/torch/nn/modules/module.py”, line 1532, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
File “/Users/piao/Documents/PythonProjects/MARL_TEM/venv/lib/python3.9/site-packages/torch/nn/modules/module.py”, line 1541, in _call_impl
return forward_call(*args, **kwargs)
File “/Users/piao/Documents/Seafile/Seafile/MARL(Python)/MARL/model.py”, line 50, in forward
x = F.relu(self.fc1(state))
File “/Users/piao/Documents/PythonProjects/MARL_TEM/venv/lib/python3.9/site-packages/torch/nn/modules/module.py”, line 1532, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
File “/Users/piao/Documents/PythonProjects/MARL_TEM/venv/lib/python3.9/site-packages/torch/nn/modules/module.py”, line 1541, in _call_impl
return forward_call(*args, **kwargs)
File “/Users/piao/Documents/PythonProjects/MARL_TEM/venv/lib/python3.9/site-packages/torch/nn/modules/linear.py”, line 116, in forward
return F.linear(input, self.weight, self.bias)
RuntimeError: mat1 and mat2 shapes cannot be multiplied (1x49 and 2x400)
Does this error has someting to do with the forward_call function? Thank you very much for help!