Your code is unfortunately quite hard to read as you haven’t formatted it properly.
You can post code snippets by wrapping them into three backticks ```, which would make debugging easier.
In any case, print the shape of intermediate activation tensors via print(tensor.shape) to narrow down the shape mismatch further.
I used this neural network and suceeded in using it.
‘’’
class Net(Module):
def init(self):
super(Net, self).init()
self.cnn_layers = Sequential(
# Defining a 2D convolution layer
Conv2d(1, 4, kernel_size=3, stride=1, padding=1),
BatchNorm2d(4),
ReLU(inplace=True),
MaxPool2d(kernel_size=2, stride=2),
# Defining another 2D convolution layer
Conv2d(4, 4, kernel_size=3, stride=1, padding=1),
BatchNorm2d(4),
ReLU(inplace=True),
MaxPool2d(kernel_size=2, stride=2),
)
#nn.LogSoftmax(dim=1),
self.linear_layers = Sequential(
Linear(4 * 7 * 7, 10)
)
# Defining the forward pass
def forward(self, x):
x = self.cnn_layers(x)
x = x.view(x.size(0), -1)
x = self.linear_layers(x)
return x
‘’’
But when i used some augmentation with the transform
transform=transforms.Compose(
[transforms.ToTensor(),
transforms.RandomVerticalFlip(p=0.5),
transforms.Normalize((0.5,), (0.5,)),
transforms.RandomResizedCrop(23, scale=(0.675, 1.0))
])
i get this error like others as well
RuntimeError: mat1 and mat2 shapes cannot be multiplied (100x100 and 196x10)
I dont know what i should change after augmentation
The shape mismatch is caused in self.linear_layers, which expects an activation input of [batch_size, 196] while you are passing [batch_size=100, 100] to it. Change the in_features to 100 and it should work.
Ok i got it working
Just wanted to confirm if using transforms like vertical crop and reducing pixel size actually make us change parameters?The above network works alright without any problems without any transfoms.
Or while making comparison should i always work with(196,100)in my case?
It depends on your model architecture and its flexibility to different input shapes.
I.e. conv layers are flexible regarding the spatial size of the input (as long as the input is large enough) but require the input to have the specified channel dimension size. Linear layers need an activation with the specified feature dimension. If you are changing the input shape, the input activation to the linear layer might have a different shape and would thus yield a shape mismatch error.
Common models in torchvision use adaptive pooling layers to make sure the input activation to the first linear layer has the right shape. If you are not using these layers, you would need to change the model for different input shapes or would need to stick to the original input shape.
1 Like
Understood,thanks so much .It is clear now.
Hi! Please I’m desperate, I know you have already answered this question multiple times but I really don’t understand how to correct this error in my code. (I want to compute regression on the age of the people in the photos)
The images are resized 128x128. (batch size 32)
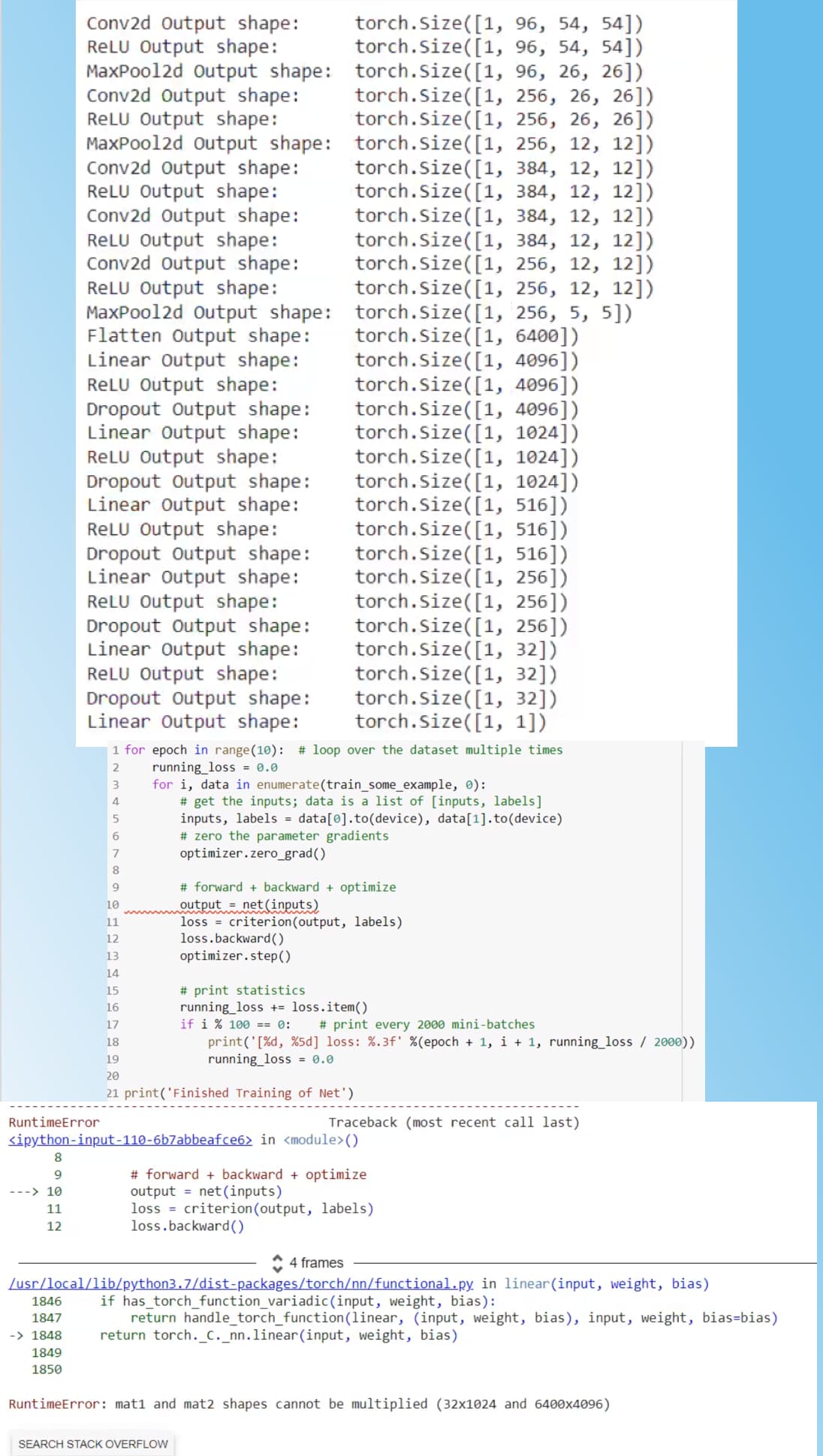
Thank you in advance
I don’t know if you are flattening the activation before passing it to the first linear layer, but you are hitting the same issue other users were running into in this thread: the feature dimension of the activation doesn’t fit the in_features of the first linear layer.
If you are already flattening the activation, change in_features to 1024, if not flatten the activation and see if it’s working.
Also, it’s better to post code snippets by wrapping them into three backticks ``` as it makes debugging easier.
Thank you very much, you’re very kind.
I have autoencoder for reconstructing the images of different people data. The model takes in image of [3, 64, 64] size and gives out image of size [3, 28,28], That triggers error of mismatch between input image and target image. The size of tensor a (64) must match the size of tensor b (28) at non-singleton dimension 3
The configuration of autoencoder is given below. please help
nn.Conv2d(3, 8, 3, stride=2, padding=1),
nn.ReLU(True),
nn.Conv2d(8, 16, 3, stride=2, padding=1),
nn.BatchNorm2d(16),
nn.ReLU(True),
nn.Conv2d(16, 32, 3, stride=2, padding=0),
nn.ReLU(True)
)
### Flatten layer
self.flatten = nn.Flatten(start_dim=1)
### Linear section
self.encoder_lin = nn.Sequential(
nn.Linear(1568, 128),
nn.ReLU(True),
nn.Linear(128, self.bottleneck_size)
)
self.decoder_lin = nn.Sequential(
nn.Linear(self.bottleneck_size, 128),
nn.ReLU(True),
nn.Linear(128, 3 * 3 * 32),
nn.ReLU(True)
)
self.unflatten = nn.Unflatten(dim=1,
unflattened_size=(32, 3, 3))
self.decoder_conv = nn.Sequential(
nn.ConvTranspose2d(32, 16, 3,
stride=2, output_padding=0),
nn.BatchNorm2d(16),
nn.ReLU(True),
nn.ConvTranspose2d(16, 8, 3, stride=2,
padding=1, output_padding=1),
nn.BatchNorm2d(8),
nn.ReLU(True),
nn.ConvTranspose2d(8, 1, 3, stride=2,
padding=1, output_padding=1)
)
I don’t know which loss function you are using but based on the error message it seems that the number of elements of the output and target are expected to be equal.
E.g. if you are using nn.MSELoss this would be the case. Could you explain your use case a bit more and also explain how the loss should be (theoretically) calculated for these provided tensor shapes?
Yes, I got the point… I checked and size of input and target are different.
fixed.
Thank you,
problem resolved
Hi I am facing an error in the below code for CIFAR10 dataset:
class Net(Module):
def init(self):
super().init()
self.conv1 = Conv2d(1, 2, kernel_size=5)
self.conv2 = Conv2d(2, 16, kernel_size=5)
self.dropout = Dropout2d()
self.fc1 = Linear(256, 64)
self.fc2 = Linear(64, 2)
self.fc3 = Linear(1, 1)
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.max_pool2d(x, 2)
x = F.relu(self.conv2(x))
x = F.max_pool2d(x, 2)
x = self.dropout(x)
x = x.view(x.shape[0], -1)
x = F.relu(self.fc1(x))
x = self.fc2(x)
x = self.fc3(x)
return cat((x, 1 - x), -1)
model4 = Net()
CIFAR10 data is using 3 channels so you might want to change the in_channels of the first nn.Conv2d layer to 3.
After fixing this issue, you will run into a shape mismatch in self.fc3:
RuntimeError: mat1 and mat2 shapes cannot be multiplied (2x2 and 1x1)
as self.fc3 expects a single feature while self.fc2 outputs 2.
Change in_features of self.fc3 to 2 and it should work.
I also have this error and I can’t find the exact culprit ![]()
mat1 and mat2 shapes cannot be multiplied (3x196608 and 784x512)
I’m new to Machine Learning and it’s my first time with PyTorch.
I’m trying to build the following UNet: UNet
{kind=link}
First, here’s how I’m building the dataset:
class TissueDataset(Dataset):
def __init__(self, img_path, target_path):
super().__init__()
self.imgs = glob(os.path.join(img_path, "*.jpg"))
self.targets = glob(os.path.join(target_path, "*.jpg"))
def __getitem__(self, idx):
size = (3, 256, 256)
image = imread(self.imgs[idx])
label = imread(self.targets[idx])
image = resize(image, size, order = 1, preserve_range = True)
label = resize(label, size, order = 0, preserve_range = True).astype(int)
return image, label
def __len__(self):
return len(self.imgs)
trainloader = DataLoader(TissueDataset(
img_path = f'data/tissue/train/jpg',
target_path = f'data/tissue/train/lbl'
), batch_size = 3, shuffle = True)
Here is an example image: Image
{kind=link}
And here is the UNet model - I’ve tried different things but all end up with the same error while training.
I don’t know where exactly is the error, or if what I’m doing even corresponds to the image.
class DoubleConv2d(Module):
def __init__(self, in_channels, out_channels):
super(DoubleConv2d, self).__init__()
self.stack = Sequential(
Conv2d(in_channels, out_channels, 3, 1, 1),
ReLU(),
Conv2d(out_channels, out_channels, 3, 1, 1),
ReLU()
)
def forward(self, x):
return self.stack(x)
class UNet(Module):
def __init__(self):
super(UNet, self).__init__()
inn = 3
out = 1
mid = [112, 224, 448]
self.encoder = ModuleList()
self.bottom = DoubleConv2d(mid[-1], 2*mid[-1]) # should both be mid[-1]?
self.decoder = ModuleList()
self.end = Conv2d(mid[0], 1*out, 1)
self.maxpool = MaxPool2d(2, 2)
# self.linear = Linear(32*7*7, 10)
for dim in mid:
self.encoder.append(DoubleConv2d(inn, dim))
inn = dim
for dim in mid[::-1]:
self.decoder.append(ConvTranspose2d(2*dim, dim, 2, 2))
self.decoder.append(DoubleConv2d(2*dim, dim))
def forward(self, x):
connections = []
for i in range(len(self.encoder)):
module = self.encoder[i]
x = module(x)
connections.append(x)
x = self.maxpool(x)
x = self.bottom(x)
for i in range(len(self.decoder)):
module = self.decoder[i]
x = module(x)
if i % 0 == 0: # ConvTranspose2d
connection = connections.pop()
x = torch.cat((connection, x), dim=1)
x = self.end(x)
x = x.view(x.size(0), -1)
return x
print(UNet())
Any help or pointers would be greately appreciated ![]()
Your current code fails with:
if i % 0 == 0: # ConvTranspose2d
ZeroDivisionError: integer division or modulo by zero
After removing this line of code it fails with:
x = torch.cat((connection, x), dim=1)
RuntimeError: Sizes of tensors must match except in dimension 1. Expected size 128 but got size 64 for tensor number 1 in the list.
Based on your Dataset transformations it seem you are using an input of [batch_size, 3, 256, 256]. Could you check your code and make it executable, please?
1 Like
Oops, it should have been i % 2 == 0! Thanks. I wonder why it did not give me an error.
I’m doing this because I want to use torch.cat on the ConvTranspose2d modules only in the self.decoder module list, which are every 2 elements.
But the error is still exactly the same when training ![]()
If it matters, here is my training function (removed some irrelevant code from it):
def train_unet(net, trainloader, valloader, optimizer, loss_function, n_epochs):
t_size = len(trainloader.dataset)
v_size = len(valloader.dataset)
for epoch in range(1, n_epochs+1):
net.train()
for X_batch, (X, y) in enumerate(trainloader):
X, y = X.to(device), y.to(device)
y_pred = net(X)
y_loss = loss_function(y_pred, y)
y_dice = dice(y, y_pred)
optimizer.zero_grad()
y_loss.backward()
optimizer.step()
if X_batch % 100 == 0:
net.eval()
for V_batch, (V, w) in enumerate(valloader):
V, w = V.to(device), w.to(device)
w_pred = net(V)
w_loss = loss_function(w_pred, w)
w_dice += dice(w, w_pred)
w_loss = w_loss / v_size
w_dice = w_dice / v_size
unet = UNet()
optimizer = Adam(unet.parameters(), lr=0.001)
loss = BCEWithLogitsLoss()
n_epochs = 10
train_unet(mlp_net, trainloader, valloader, optimizer, loss, n_epochs)Hi! I have torch.Size([1, 28, 28]) data, in batches of 10, and the following network:
class Net(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(8 * 8 * 16, 400)
self.fc2 = nn.Linear(400, 100)
self.fc3 = nn.Linear(100, 24)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = torch.flatten(x, 1) # flatten all dimensions except batch
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
the program gives RuntimeError: mat1 and mat2 shapes cannot be multiplied (10x256 and 1024x400). I flattened the tensor dimension before the linear layer, and I calculated that the data size is 1 * 8 * 8 after the second Conv, and given that tere are 16 layers, that should be 8 * 8 * 16 = 1024, and not 256. What might be the problem? I tried it with 256, it did not work either.
You have applied self.pool two times.
# x = 10x1x28x28
x = self.pool(F.relu(self.conv1(x))) # x = 10x6x12x12
x = self.pool(F.relu(self.conv2(x))) # x = 10x16x4x4
1 Like
Thanks!! Somehow I managed to miss that… ![]()