After fixing the if condition, the code runs fine and I don’t get any issues.
Based on your initial error I guess the shape mismatch is raised in a linear layer, which is not used in your model.
If you want to use self.linear comment it in again, set in_features to 65536, and use it in the forward method.
1 Like
Thanks a lot but I still have the same error with the same numbers when training ![]()
If it’s any help, here is the output of print(UNet):
UNet(
(encoder): ModuleList(
(0): DoubleConv2d(
(stack): Sequential(
(0): Conv2d(3, 112, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): Conv2d(112, 112, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU()
)
)
(1): DoubleConv2d(
(stack): Sequential(
(0): Conv2d(112, 224, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): Conv2d(224, 224, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU()
)
)
(2): DoubleConv2d(
(stack): Sequential(
(0): Conv2d(224, 448, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): Conv2d(448, 448, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU()
)
)
)
(bottom): DoubleConv2d(
(stack): Sequential(
(0): Conv2d(448, 896, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): Conv2d(896, 896, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU()
)
)
(decoder): ModuleList(
(0): ConvTranspose2d(896, 448, kernel_size=(2, 2), stride=(2, 2))
(1): DoubleConv2d(
(stack): Sequential(
(0): Conv2d(896, 448, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): Conv2d(448, 448, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU()
)
)
(2): ConvTranspose2d(448, 224, kernel_size=(2, 2), stride=(2, 2))
(3): DoubleConv2d(
(stack): Sequential(
(0): Conv2d(448, 224, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): Conv2d(224, 224, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU()
)
)
(4): ConvTranspose2d(224, 112, kernel_size=(2, 2), stride=(2, 2))
(5): DoubleConv2d(
(stack): Sequential(
(0): Conv2d(224, 112, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): Conv2d(112, 112, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU()
)
)
)
(end): Conv2d(112, 1, kernel_size=(1, 1), stride=(1, 1))
(maxpool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(linear): Linear(in_features=65536, out_features=10, bias=True)
)
This code works for me:
class DoubleConv2d(nn.Module):
def __init__(self, in_channels, out_channels):
super(DoubleConv2d, self).__init__()
self.stack = nn.Sequential(
nn.Conv2d(in_channels, out_channels, 3, 1, 1),
nn.ReLU(),
nn.Conv2d(out_channels, out_channels, 3, 1, 1),
nn.ReLU()
)
def forward(self, x):
return self.stack(x)
class UNet(nn.Module):
def __init__(self):
super(UNet, self).__init__()
inn = 3
out = 1
mid = [112, 224, 448]
self.encoder = nn.ModuleList()
self.bottom = DoubleConv2d(mid[-1], 2*mid[-1]) # should both be mid[-1]?
self.decoder = nn.ModuleList()
self.end = nn.Conv2d(mid[0], 1*out, 1)
self.maxpool = nn.MaxPool2d(2, 2)
self.linear = nn.Linear(65536, 10)
for dim in mid:
self.encoder.append(DoubleConv2d(inn, dim))
inn = dim
for dim in mid[::-1]:
self.decoder.append(nn.ConvTranspose2d(2*dim, dim, 2, 2))
self.decoder.append(DoubleConv2d(2*dim, dim))
def forward(self, x):
connections = []
for i in range(len(self.encoder)):
module = self.encoder[i]
x = module(x)
connections.append(x)
x = self.maxpool(x)
x = self.bottom(x)
for i in range(len(self.decoder)):
module = self.decoder[i]
x = module(x)
if i % 2 == 0: # ConvTranspose2d
connection = connections.pop()
x = torch.cat((connection, x), dim=1)
x = self.end(x)
x = x.view(x.size(0), -1)
x = self.linear(x)
return x
model = UNet()
x = torch.randn(2, 3, 256, 256)
out = model(x)
If you get stuck, please post a new minimal, executable code snippet showing the error.
1 Like
This is exactly the code that I have now, but I just realized I had passed another model in the training function ![]()
I got a few errors I could fix, but now I’m stuck on this one that I moved to a new topic: Target size (torch.Size([3, 3, 256, 256])) must be the same as input size (torch.Size([3, 65536]))
Thank you so much for the help though!
I am getting similar error: The input dimensions are 6 and here is the observation space:
low = np.array([2, 0, 0, 0, 3, 2]).astype(np.float32)
high = np.array([3, 10, 10, 1, 30, 20]).astype(np.float32)
self.observation_space = spaces.Box(low, high)
Following is the code for model:
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
import torch as T
import os
import torch.optim as optim
import numpy as np
EPS = 0.003
def fanin_init(size, fanin=None):
fanin = fanin or size[0]
v = 1. / np.sqrt(fanin)
return torch.Tensor(size).uniform_(-v, v)
class Critic(nn.Module):
def __init__(self, state_dim, action_dim):
"""
:param state_dim: Dimension of input state (int)
:param action_dim: Dimension of input action (int)
:return:
"""
super(Critic, self).__init__()
self.state_dim = state_dim
self.action_dim = action_dim
self.fcs1 = nn.Linear(state_dim,256)
self.fcs1.weight.data = fanin_init(self.fcs1.weight.data.size())
self.fcs2 = nn.Linear(256,128)
self.fcs2.weight.data = fanin_init(self.fcs2.weight.data.size())
self.fca1 = nn.Linear(action_dim,128)
self.fca1.weight.data = fanin_init(self.fca1.weight.data.size())
self.fc2 = nn.Linear(256,128)
self.fc2.weight.data = fanin_init(self.fc2.weight.data.size())
self.fc3 = nn.Linear(128,1)
self.fc3.weight.data.uniform_(-EPS,EPS)
def forward(self, state, action):
"""
returns Value function Q(s,a) obtained from critic network
:param state: Input state (Torch Variable : [n,state_dim] )
:param action: Input Action (Torch Variable : [n,action_dim] )
:return: Value function : Q(S,a) (Torch Variable : [n,1] )
"""
s1 = F.relu(self.fcs1(state))
s2 = F.relu(self.fcs2(s1))
a1 = F.relu(self.fca1(action))
x = torch.cat((s2,a1),dim=1)
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
class Actor(nn.Module):
def __init__(self, state_dim, action_dim, action_lim):
"""
:param state_dim: Dimension of input state (int)
:param action_dim: Dimension of output action (int)
:param action_lim: Used to limit action in [-action_lim,action_lim]
:return:
"""
super(Actor, self).__init__()
self.state_dim = state_dim
self.action_dim = action_dim
self.action_lim = action_lim
self.fc1 = nn.Linear(state_dim,256)
self.fc1.weight.data = fanin_init(self.fc1.weight.data.size())
self.fc2 = nn.Linear(256,128)
self.fc2.weight.data = fanin_init(self.fc2.weight.data.size())
self.fc3 = nn.Linear(128,64)
self.fc3.weight.data = fanin_init(self.fc3.weight.data.size())
self.fc4 = nn.Linear(64,action_dim)
self.fc4.weight.data.uniform_(-EPS,EPS)
def forward(self, obs):
"""
returns policy function Pi(s) obtained from actor network
this function is a gaussian prob distribution for all actions
with mean lying in (-1,1) and sigma lying in (0,1)
The sampled action can , then later be rescaled
:param state: Input state (Torch Variable : [n,state_dim] )
:return: Output action (Torch Variable: [n,action_dim] )
"""
# state = T.tensor(obs, dtype=T.float)
x = F.relu(self.fc1(obs))
x = F.relu(self.fc2(x))
x = F.relu(self.fc3(x))
action = F.tanh(self.fc4(x))
# action = action * self.action_lim
return action
This is the error I get:
File "c:\Users\MY\Documents\Slicing\envs\model.py", line 102, in forward
x = F.relu(self.fc1(obs))
File "C:\Users\MY\anaconda3\lib\site-packages\torch\nn\modules\module.py", line 1102, in _call_impl
return forward_call(*input, **kwargs)
File "C:\Users\MY\anaconda3\lib\site-packages\torch\nn\modules\linear.py", line 103, in forward
return F.linear(input, self.weight, self.bias)
File "C:\Users\MY\anaconda3\lib\site-packages\torch\nn\functional.py", line 1848, in linear
return torch._C._nn.linear(input, weight, bias)
RuntimeError: mat1 and mat2 shapes cannot be multiplied (1x0 and 6x256)
If seems the input activation is empty as it has a shape of [1, 0] while the linear layer expects 6 input features. Check the shape of all intermediate activations and make sure they are not pooled or reduced to an empty tensor.
What is meant by “input activation is empty” ? I am new to this so maybe I don’t understand some terms.
This is the observation space which has a dimension size of 6
low = np.array([2, 0, 0, 0, 3, 2]).astype(np.float32)
high = np.array([3, 10, 10, 1, 30, 20]).astype(np.float32)
self.observation_space = spaces.Box(low, high)
The error message shows that the input activation is a tensor with a shape of [1, 0] which does not contain any values and is thus empty.
Here is a small code snippet to reproduce the error:
x = torch.randn(1, 0)
print(x.shape)
# torch.Size([1, 0])
print(x) # empty tensor, i.e. no values stored
# tensor([], size=(1, 0))
lin = nn.Linear(6, 256)
out = lin(x)
# RuntimeError: mat1 and mat2 shapes cannot be multiplied (1x0 and 6x256)
1 Like
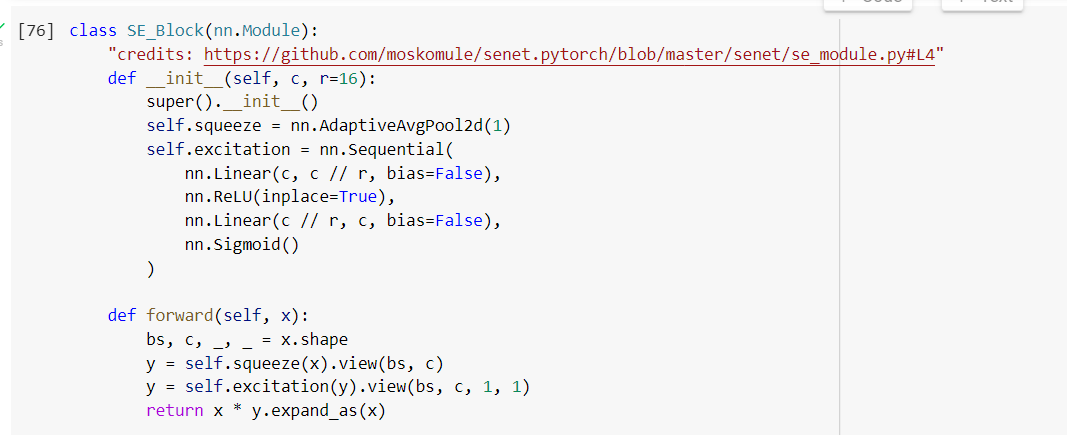
RuntimeError: mat1 and mat2 shapes cannot be multiplied (25x256 and 64x4)
Could anyone please help me with these errors
Based on the error message I would guess that the first linear layer is raising it and it seems c might be set to 64 while the input would have a shape of [batch_size=25, features=256].
Make sure the input has 64 features or set c to 256.
PS: you can post code snippets by wrapping them into three backticks ``` ![]()
1 Like
Thanks a lot for the reply, but I am new to DL and having difficulties debugging the code.I am trying to build a few shot algorithm implemented with prototypical networks with a resnet50 backbone along with SENet.I am attaching few more code snippets.I would be greatly obliged if you could take a look and suggest some changes. Thanks
"credits: https://github.com/moskomule/senet.pytorch/blob/master/senet/se_module.py#L4"
def __init__(self, c, r=16):
super().__init__()
self.squeeze = nn.AdaptiveAvgPool2d(1)
self.excitation = nn.Sequential(
nn.Linear(c, c // r, bias=False),
nn.ReLU(inplace=True),
nn.Linear(c // r, c, bias=False),
nn.Sigmoid()
)
def forward(self, x):
bs, c, _, _ = x.shape
y = self.squeeze(x).view(bs, c)
y = self.excitation(y).view(bs, c, 1, 1)
return x * y.expand_as(x)
The code for the Squeeze and excitation block
```class SEBottleneck(nn.Module):
# Bottleneck in torchvision places the stride for downsampling at 3x3 convolution(self.conv2)
# while original implementation places the stride at the first 1x1 convolution(self.conv1)
# according to "Deep residual learning for image recognition"https://arxiv.org/abs/1512.03385.
# This variant is also known as ResNet V1.5 and improves accuracy according to
# https://ngc.nvidia.com/catalog/model-scripts/nvidia:resnet_50_v1_5_for_pytorch.
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None, groups=1,
base_width=64, dilation=1, norm_layer=None, r=16):
super(SEBottleneck, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
width = int(planes * (base_width / 64.)) * groups
# Both self.conv2 and self.downsample layers downsample the input when stride != 1
self.conv1 = conv1x1(inplanes, width)
self.bn1 = norm_layer(width)
self.conv2 = conv3x3(width, width, stride, groups, dilation)
self.bn2 = norm_layer(width)
self.conv3 = conv1x1(width, planes * self.expansion)
self.bn3 = norm_layer(planes * self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
# Add SE block
self.se = SE_Block(planes, r)
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
# Add SE operation
out = self.se(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out```
The resnet50 bottle neck added with one extra line of code i.e. **out = self.se(out)**.
The code works fine without the Squeeze and Excitation operation i.e. when I comment out the **out=self.se(out)** line.
But when included it gives this error
```RuntimeError: mat1 and mat2 shapes cannot be multiplied (25x256 and 64x4)```I am also facing similar issue
import numpy as np
import torch as th
from torch import nn as nn
import torch.nn.functional as F
from torch import tensor
from stable_baselines3.common.vec_env import VecTransposeImage
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.features_extractor = nn.Flatten(start_dim=1, end_dim=-1)
self.mlp_extractor = nn.Sequential(
nn.Linear(in_features=9, out_features=64, bias=True),
nn.Tanh(),
nn.Linear(in_features=64, out_features=64, bias=True),
nn.Tanh()
)
self.action_net = nn.Sequential(
nn.Linear(in_features=64, out_features=9, bias=True),
)
def forward(self, x):
x = self.features_extractor(x)
x = self.mlp_extractor(x)
x = self.action_net(x)
x = x.argmax()
return x
def getMove(obs):
model = Net()
model = model.float()
model.load_state_dict(state_dict)
model = model.to('cpu')
model = model.eval()
obs = th.as_tensor(obs).to('cpu').float()
obs = obs.unsqueeze(1)
action = model(obs)
return action
and i am getting this error -
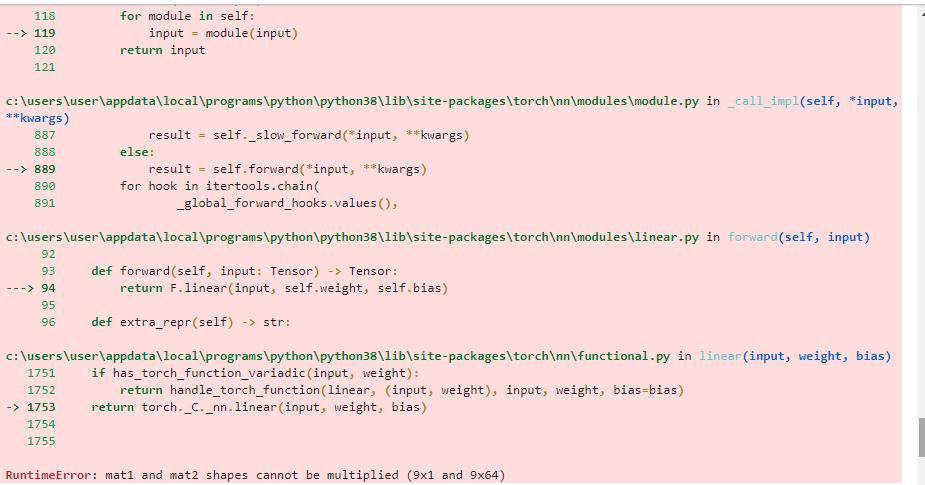
for line -
x = self.mlp_extractor(x)how can i fix it?
Your input seems to use a shape of [batch_size=9, features=1] while features=9 is expected in the first linear layer.
Either make sure the input has 9 features or set in_features of the first linear layer to 1.
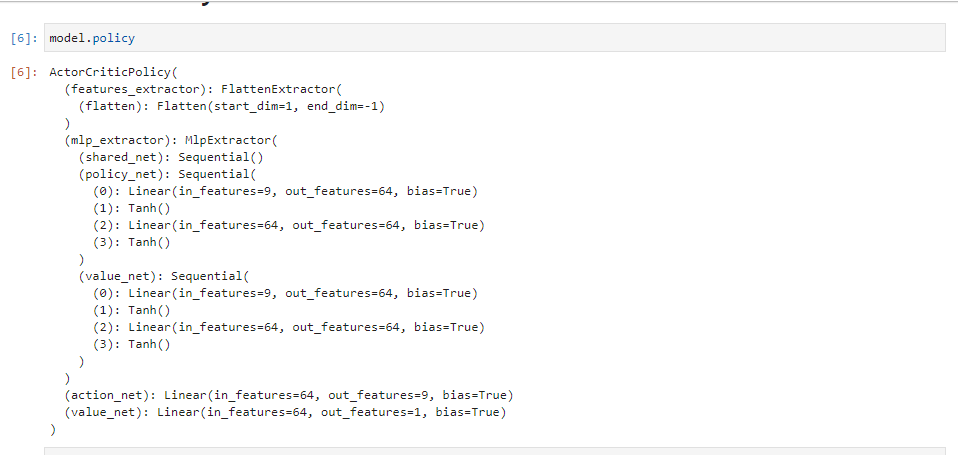
Yes, I know as you’ve already shared the model definition.
In that case your input is wrong and I assume you might need to permute it.
how can i do that? i am totally beginner
x = x.t() should work assuming the dimensions are permuted.
Since I’m not familiar with your use case I would still recommend to check the root cause of this issue and narrow down why the shape is wrong at all.
but during the training period it was same so what can be the cause?
Hello. I have the same problem, and I try lots of things without find anything which works.
I’m working on ‘Iris flower data set’
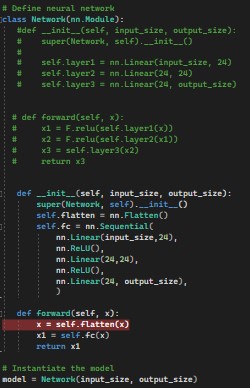
When first part his uncomment, it provides this error :
RuntimeError: mat1 and mat2 shapes cannot be multiplied (96x32 and 4x24)
When the second part running, it provides this error :
RuntimeError: mat1 and mat2 shapes cannot be multiplied (1x3072 and 4x24)
First of all, I don’t understand from where come the numbers 96x32 and 1x3072, and then I can’t resolve the issue.
Here the complete code if you need it.
Thank you!
import torch
import torch.nn as nn
import pandas as pd
from torch.utils.data import random_split, DataLoader, TensorDataset
import torch.nn.functional as F
import numpy as np
import torch.optim as optim
from torch.optim import Adam
//from multiprocessing import freeze_support
// Loading the Data
df = pd.read_excel(r’C:\Users\gurva\source\repos\Iris de Fisher sol\Iris_dataset.xlsx’)
print(‘Take a look at sample from the dataset:’)
print(df.head())
// Let’s verify if our data is balanced and what types of species we have
print(‘\nOur dataset is balanced and has the following values to predict:’)
print(df[‘Iris_Type’].value_counts())
// Convert Iris species into numeric types: Iris-setosa=0, Iris-versicolor=1, Iris-virginica=2.
labels = {‘Iris-setosa’:0, ‘Iris-versicolor’:1, ‘Iris-virginica’:2}
df[‘IrisType_num’] = df[‘Iris_Type’] # Create a new column “IrisType_num”
df.IrisType_num = [labels[item] for item in df.IrisType_num] # Convert the values to numeric ones
// Define input and output datasets
input = df.iloc[:, 1:-2] # We drop the first column and the two last ones, i.e. .iloc = we take all into what we put in
print(‘\nInput values are:’)
print(input.head())
print(‘###########################’)
test = df.loc[:, ‘petal length in cm’]
print(df.head())
print(‘\n###’)
print(test.head())
print(‘###########################’)
output = df.loc[:, ‘IrisType_num’] # Output Y is the last column, i.e. .loc = we take the column (or line) we want with ‘…’
print(‘\nThe output value is:’)
print(output.head())
// Convert Input and Output data to Tensors and create a TensorDataset
input = torch.Tensor(input.to_numpy()) # Create tensor of type torch.float32
print('\nInput format: ', input.shape, input.dtype) # Input format: torch.Size([150, 4]) torch.float32
output = torch.tensor(output.to_numpy()) # Create tensor type torch.int64
print('Output format: ', output.shape, output.dtype) # Output format: torch.Size([150]) torch.int64
data = TensorDataset(input, output) # Create a torch.utils.data.TensorDataset object for further data manipulation
// Split to Train, Validate and Test sets using random_split
train_batch_size = 10
number_rows = len(input) # The size of our dataset or the number of rows in excel table.
test_split = int(number_rows0.3)
validate_split = int(number_rows0.2)
train_split = number_rows - test_split - validate_split
train_set, validate_set, test_set = random_split(
data, [train_split, validate_split, test_split])
// Create Dataloader to read the data within batch sizes and put into memory.
train_loader = DataLoader(train_set, batch_size = train_batch_size, shuffle = True)
validate_loader = DataLoader(validate_set, batch_size = 1)
test_loader = DataLoader(test_set, batch_size = 1)
// Define model parameters
input_size = list(input.shape)[1] # = 4. The input depends on how many features we initially feed the model. In our case, there are 4 features for every predict value
print(‘input_size =’, input_size)
learning_rate = 0.01
output_size = len(labels) # The output is prediction results for three types of Irises.
print('output_size = ', output_size)
// Define neural network
class Network(nn.Module):
def init(self, input_size, output_size):
super(Network, self).init()
self.layer1 = nn.Linear(input_size, 24)
self.layer2 = nn.Linear(24, 24)
self.layer3 = nn.Linear(24, output_size)
def forward(self, x):
x1 = F.relu(self.layer1(x))
x2 = F.relu(self.layer2(x1))
x3 = self.layer3(x2)
return x3
//
def init(self, input_size, output_size):
super(Network, self).init()
self.flatten = nn.Flatten()
self.fc = nn.Sequential(
nn.Linear(input_size,24),
nn.ReLU(),
nn.Linear(24,24),
nn.ReLU(),
nn.Linear(24, output_size),
)
def forward(self, x):
x = self.flatten(x)
x1 = self.fc(x)
return x1
// Instantiate the model
model = Network(input_size, output_size)
// Define your execution device
device = torch.device(“cuda:0” if torch.cuda.is_available() else “cpu”)
print(“The model will be running on”, device, “device\n”)
model.to(device) # Convert model parameters and buffers to CPU or Cuda
// Function to save the model
def saveModel():
path = “./NetModel.pth”
torch.save(model.state_dict(), path)
// Define the loss function with Classification Cross-Entropy loss and an optimizer with Adam optimizer
loss_fn = nn.CrossEntropyLoss()
optimizer = Adam(model.parameters(), lr=0.001, weight_decay=0.0001)
// Training Function
def train(num_epochs):
best_accuracy = 0.0
print("Begin training...")
for epoch in range(1, num_epochs+1):
running_train_loss = 0.0
running_accuracy = 0.0
running_vall_loss = 0.0
total = 0
# Training Loop
for data in train_loader:
#for data in enumerate(train_loader, 0):
inputs, outputs = data # get the input and real species as outputs; data is a list of [inputs, outputs]
optimizer.zero_grad() # zero the parameter gradients
predicted_outputs = model(inputs) # predict output from the model
train_loss = loss_fn(predicted_outputs, outputs) # calculate loss for the predicted output
train_loss.backward() # backpropagate the loss
optimizer.step() # adjust parameters based on the calculated gradients
running_train_loss +=train_loss.item() # track the loss value
# Calculate training loss value
train_loss_value = running_train_loss/len(train_loader)
# Validation Loop
with torch.no_grad():
model.eval()
for data in validate_loader:
inputs, outputs = data
predicted_outputs = model(inputs)
val_loss = loss_fn(predicted_outputs, outputs)
# The label with the highest value will be our prediction
_, predicted = torch.max(predicted_outputs, 1)
running_vall_loss += val_loss.item()
total += outputs.size(0)
running_accuracy += (predicted == outputs).sum().item()
# Calculate validation loss value
val_loss_value = running_vall_loss/len(validate_loader)
# Calculate accuracy as the number of correct predictions in the validation batch divided by the total number of predictions done.
accuracy = (100 * running_accuracy / total)
# Save the model if the accuracy is the best
if accuracy > best_accuracy:
saveModel()
best_accuracy = accuracy
# Print the statistics of the epoch
print('Completed training batch', epoch, 'Training Loss is: %.4f' %train_loss_value, 'Validation Loss is: %.4f' %val_loss_value, 'Accuracy is %d %%' % (accuracy))
// Function to test the model
def test():
# Load the model that we saved at the end of the training loop
model = Network(input_size, output_size)
path = “NetModel.pth”
model.load_state_dict(torch.load(path))
running_accuracy = 0
total = 0
with torch.no_grad():
for data in test_loader:
inputs, outputs = data
outputs = outputs.to(torch.float32)
predicted_outputs = model(inputs)
_, predicted = torch.max(predicted_outputs, 1)
total += outputs.size(0)
running_accuracy += (predicted == outputs).sum().item()
print('Accuracy of the model based on the test set of', test_split ,'inputs is: %d %%' % (100 * running_accuracy / total))
// Optional: Function to test which species were easier to predict
def test_species():
# Load the model that we saved at the end of the training loop
model = Network(input_size, output_size)
path = “NetModel.pth”
model.load_state_dict(torch.load(path))
labels_length = len(labels) # how many labels of Irises we have. = 3 in our database.
labels_correct = list(0. for i in range(labels_length)) # list to calculate correct labels [how many correct setosa, how many correct versicolor, how many correct virginica]
labels_total = list(0. for i in range(labels_length)) # list to keep the total # of labels per type [total setosa, total versicolor, total virginica]
with torch.no_grad():
for data in test_loader:
inputs, outputs = data
predicted_outputs = model(inputs)
_, predicted = torch.max(predicted_outputs, 1)
label_correct_running = (predicted == outputs).squeeze()
label = outputs[0]
if label_correct_running.item():
labels_correct[label] += 1
labels_total[label] += 1
label_list = list(labels.keys())
for i in range(output_size):
print('Accuracy to predict %5s : %2d %%' % (label_list[i], 100 * labels_correct[i] / labels_total[i]))
#Function to Convert to ONNX
def convert():
# set the model to inference mode
model.eval()
# Let's create a dummy input tensor
dummy_input = torch.randn(1, 3, 32, 32, requires_grad=True)
# Export the model
print('test1')
torch.onnx.export(model, # model being run
dummy_input, # model input (or a tuple for multiple inputs)
"Network.onnx", # where to save the model
export_params=True, # store the trained parameter weights inside the model file
opset_version=11, # the ONNX version to export the model to
do_constant_folding=True, # whether to execute constant folding for optimization
input_names = ['input'], # the model's input names
output_names = ['output'], # the model's output names
dynamic_axes={'input' : {0 : 'batch_size'}, # variable length axes
'output' : {0 : 'batch_size'}})
print('test2')
print(" ")
print('Model has been converted to ONNX')
if name == “main”:
num_epochs = 20
train(num_epochs)
print(‘Finished Training\n’)
test()
test_species()
convert()
The first error is created in:
self.layer1 = nn.Linear(input_size, 24)
as input_size seems to be set to 4 while your input has 32 features.
Change input_size to 32 and it should work.
PS: you can post code snippet by wrapping it into three backticks ```, as your current code is a bit hard to read ![]()