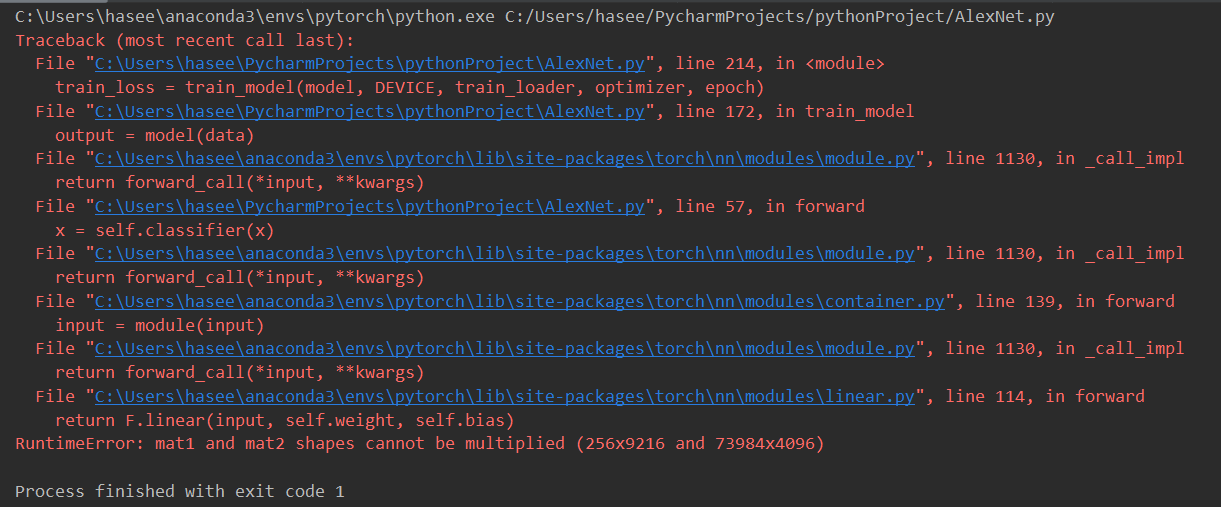
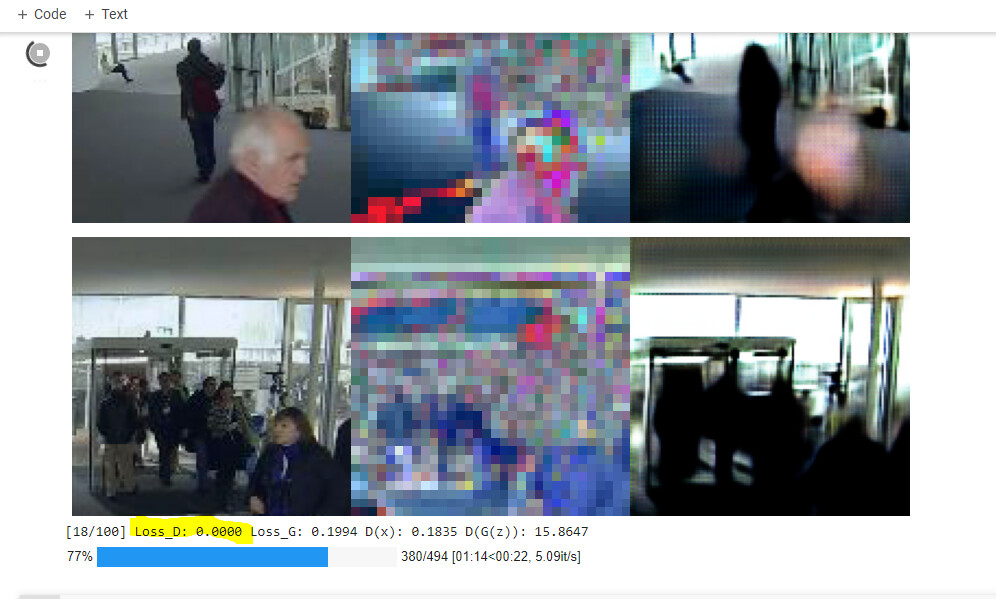
I have changed in_features=73984 in the first linear layer, but it still can’t work. Please help me find out where the problem is.
class AlexNet(nn.Module):
def __init__(self, num_classes=2, init_weights=False):
super(AlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 96, kernel_size=3, stride=3, padding=2), # input[3, 32, 32] output[96, 12, 12]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=1), # output[96, 10, 10]
nn.BatchNorm2d(96),
nn.Conv2d(96, 256, kernel_size=5, padding=2), # output[256, 10, 10]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=1), # output[256, 8, 8]
nn.BatchNorm2d(256),
nn.Conv2d(256, 384, kernel_size=3, padding=1), # output[384, 8, 8]
nn.ReLU(inplace=True),
nn.Conv2d(384, 384, kernel_size=3, padding=1), # output[384, 8, 8]
nn.ReLU(inplace=True),
nn.Conv2d(384, 256, kernel_size=3, padding=1), # output[256, 8, 8]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=1), # output[256, 6, 6],
)
self.classifier = torch.nn.Sequential(
nn.Linear(in_features=73984, out_features=4096, ),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(4096, num_classes),
)
if init_weights:
self._initialize_weights()
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, start_dim=1)
x = self.classifier(x)
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)