Hello, thank you a lot for your answer, after the modification the error message has disappeared.
However I’m facing a new issue. Now I want to had extra layer to my FNN, and the issue with RuntimeError: mat1 and mat2 shapes cannot be multiplied persist…
Here a new sketch of my code :
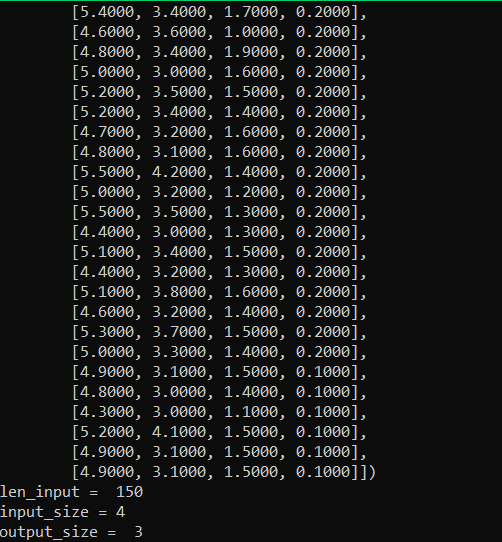
train_input = df.iloc[:, 0:5].values.astype('float32')
print(train_input.shape)
ti = torch.tensor(train_input)
print("ti shape",ti.shape)
train_output = df.iloc[:, 38].values.astype('float32')
to = torch.tensor(train_output)
to = to.view(1750,1)
print("to.shape",to.shape)
#Training and Validation Split
ti, val_i, to, val_o = train_test_split(ti, to, random_state=2020,test_size=0.2)
class NeuralNetwork(nn.Module):
def __init__(self):
super().__init__()
tch.manual_seed(2020)
self.fc1 = nn.Linear(5,10)
self.fc2 = nn.Linear(10,20)
self.fc3 = nn.Linear(20,1)
self.relu1 = nn.ReLU()
self.final = nn.Sigmoid()
def forward(self, x):
op = self.fc1(x)
op = self.relu1(op)
op = self.fc2(op)
op = self.relu1(op)
op = self.fc3(x)
op = self.relu1(op)
y = self.final(op)
return y
def train_network(model, optimizer, loss_function, num_epochs, batch_size, ti, to):
# Explicitly start model training
model.train()
loss_across_epochs = []
for epochs in range(num_epochs):
train_loss = 0.0
for i in range(0, ti.shape[0], batch_size):
# Extract train batch from X and Y
input_data = ti [i:min(ti.shape[0], i + batch_size)]
labels = to [i:min(to.shape[0], i + batch_size)]
# set the gradients to zero before starting to do backpropragation
optimizer.zero_grad()
# Forward pass
output_data = model(input_data)
# Caculate loss
loss = loss_function(output_data, labels)
# Backpropogate
loss.backward()
# Update weights
optimizer.step()
train_loss += loss.item() * batch_size
print("Epoch: {} - Loss:{:.4f}".format(epochs + 1, train_loss))
loss_across_epochs.extend([train_loss])
#Predict
y_test_pred = model(val_i)
a = np.where(y_test_pred>=0,1, 0)
return loss_across_epochs
# Create an object of the Neural Network class
model = NeuralNetwork()
# Define loss function
loss_function = nn.MSELoss() # Squared Error
# Define Optimizer
adam_optimizer = tch.optim.Adam(model.parameters(), lr=0.001)
# Define epochs and batch size
num_epochs = 10
batch_size =1
# Calling the function for training and pass model, optimizer, loss and related parameters
adam_loss = train_network(model, adam_optimizer, loss_function, num_epochs, batch_size, ti, to)
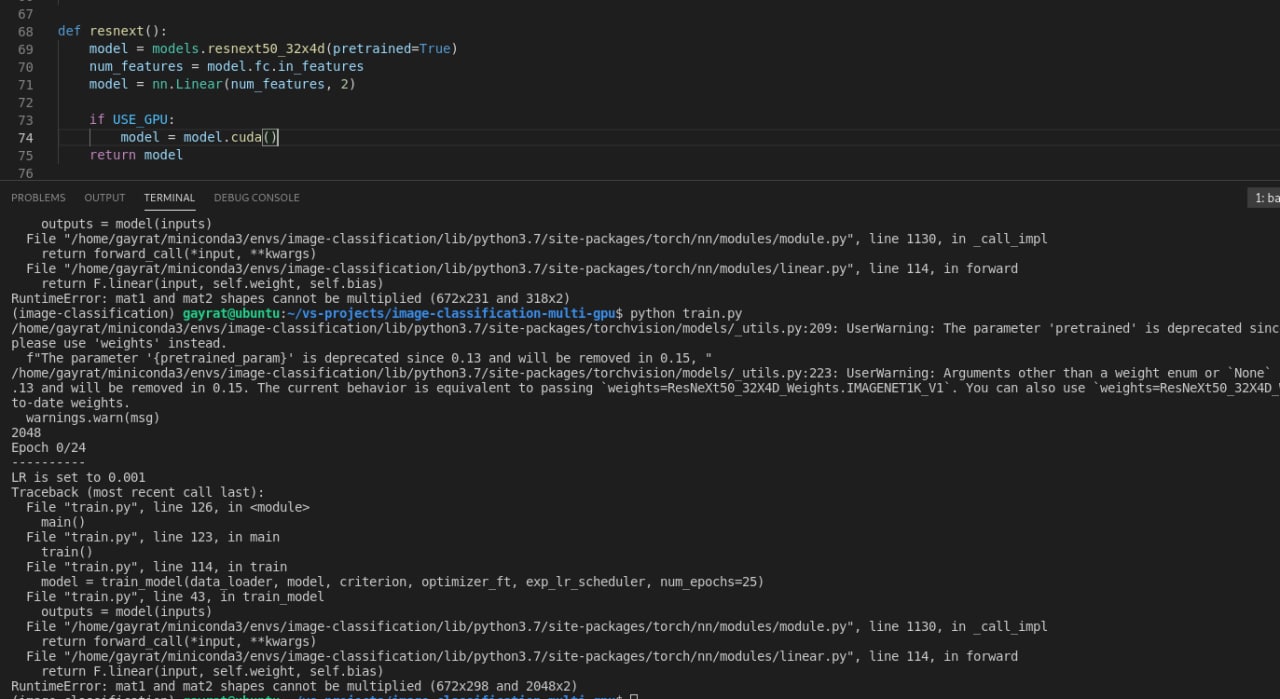
The error message is still the same:
(1750, 5)
ti shape torch.Size([1750, 5])
to.shape torch.Size([1750, 1])
Traceback (most recent call last):
File "/home2/baptiste/anaconda3/envs/pythonProject1/lib/python3.10/site-packages/IPython/core/interactiveshell.py", line 3398, in run_code
exec(code_obj, self.user_global_ns, self.user_ns)
File "<ipython-input-2-c6c09d76d5ce>", line 1, in <cell line: 1>
runfile('/home2/baptiste/PycharmProjects/pythonProject/pythonProject1/PV project/Test FNN 1.py', wdir='/home2/baptiste/PycharmProjects/pythonProject/pythonProject1/PV project')
File "/home2/baptiste/.local/share/JetBrains/Toolbox/apps/PyCharm-P/ch-0/221.5080.212/plugins/python/helpers/pydev/_pydev_bundle/pydev_umd.py", line 198, in runfile
pydev_imports.execfile(filename, global_vars, local_vars) # execute the script
File "/home2/baptiste/.local/share/JetBrains/Toolbox/apps/PyCharm-P/ch-0/221.5080.212/plugins/python/helpers/pydev/_pydev_imps/_pydev_execfile.py", line 18, in execfile
exec(compile(contents+"\n", file, 'exec'), glob, loc)
File "/home2/baptiste/PycharmProjects/pythonProject/pythonProject1/PV project/Test FNN 1.py", line 115, in <module>
adam_loss = train_network(model, adam_optimizer, loss_function, num_epochs, batch_size, ti, to)
File "/home2/baptiste/PycharmProjects/pythonProject/pythonProject1/PV project/Test FNN 1.py", line 76, in train_network
output_data = model(input_data)
File "/home2/baptiste/anaconda3/envs/pythonProject1/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1110, in _call_impl
return forward_call(*input, **kwargs)
File "/home2/baptiste/PycharmProjects/pythonProject/pythonProject1/PV project/Test FNN 1.py", line 46, in forward
op = self.fc3(x)
File "/home2/baptiste/anaconda3/envs/pythonProject1/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1110, in _call_impl
return forward_call(*input, **kwargs)
File "/home2/baptiste/anaconda3/envs/pythonProject1/lib/python3.10/site-packages/torch/nn/modules/linear.py", line 103, in forward
return F.linear(input, self.weight, self.bias)
RuntimeError: mat1 and mat2 shapes cannot be multiplied (1x5 and 20x1)
Why when I had one extra layer, everything goes wrong, furthermore I’m getting confuse with the correct Batch size that i should choose as well as this part in my code:
#Predict
y_test_pred = model(val_i)
a = np.where(y_test_pred>=0,1, 0)
return loss_across_epoch
which is really not clear…
Thanks in advance for any tips or subjection that you could made