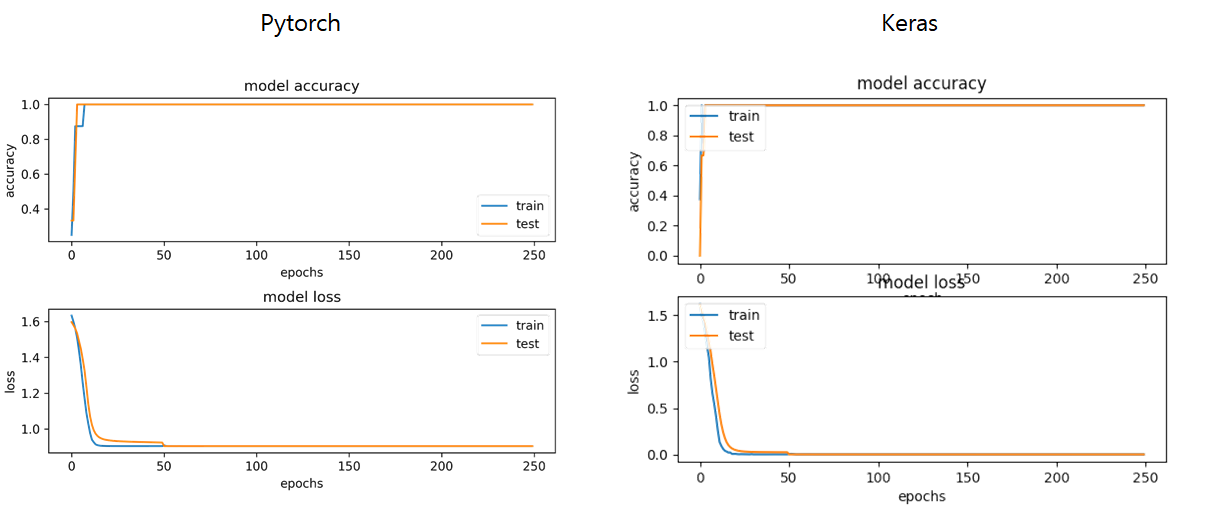
I converted Keras model to Pytorch. And I try to get same results.
The accuracy shows the same result but loss is quite different.
The trend of decreasing loss is same but those values are different.
Keras reaches to the 0 but Torch doesn’t go under the bottom at 0.90.
[Keras model]
from keras.layers import Dense, Dropout
from keras.models import Sequential
from keras.optimizers import Adam
import keras
class SoftMax():
def __init__(self, input_shape, num_classes):
self.input_shape = input_shape
self.num_classes = num_classes
def build(self):
model = Sequential()
model.add(Dense(1024, activation='relu', input_shape=self.input_shape))
model.add(Dropout(0.5))
model.add(Dense(1024, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(self.num_classes, activation='softmax'))
optimizer = Adam()
model.compile(loss=keras.losses.categorical_crossentropy,
optimizer=optimizer,
metrics=['accuracy'])
return model
[Pytorch model]
import numpy as np
import torch
use_cuda = torch.cuda.is_available()
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
class embedding_classifier(nn.Module):
def __init__(self, input_shape, num_classes):
super(embedding_classifier, self).__init__()
self.input_shape = input_shape
self.num_classes = num_classes
## softmax classifier
fc1 = nn.Linear(in_features=self.input_shape, out_features=1024, bias=True)
BN1 = nn.BatchNorm1d(num_features=1024)
relu1 = nn.ReLU()
dropout1 = nn.Dropout(p=0.5)
fc2 = nn.Linear(in_features=1024, out_features=1024, bias=True)
BN2 = nn.BatchNorm1d(num_features=1024)
relu2 = nn.ReLU()
dropout2 = nn.Dropout(p=0.5)
out = nn.Linear(in_features=1024, out_features=self.num_classes)
self.fc_module = nn.Sequential(
#layer1
fc1,
BN1,
relu1,
dropout1,
#layer2
fc2,
BN2,
relu2,
dropout2,
#output
out
)
if use_cuda:
self.fc_module = self.fc_module.cuda()
def forward(self, input_data):
out = self.fc_module(input_data)
out = F.softmax(out, dim=1)
return out.cuda()
I trained those two models wth 5-fold cross validation as below:
[Keras]
import pickle
import argparse
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import KFold
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import OneHotEncoder
from architecture.embedding_learner_keras import SoftMax
def main(args):
## Load face embeddings
embedding_data = pickle.loads(open(args['embeddings_path'], 'rb').read())
print("[INFO] embedding data has been loaded...")
## Encode the labels
sklearn_label_encoder = LabelEncoder()
labels = sklearn_label_encoder.fit_transform(embedding_data['names'])
num_classes = len(np.unique(labels))
labels = labels.reshape(-1, 1)
one_hot_encoder = OneHotEncoder(categories='auto')
labels = one_hot_encoder.fit_transform(labels).toarray()
embeddings = np.array(embedding_data['embeddings'])
## Initialize classifier arguments
BATCH_SIZE = args['batch_size']
EPOCHS = args['epochs']
input_shape = embeddings.shape[1]
# Build sofmax classifier
softmax = SoftMax(input_shape=(input_shape,), num_classes=num_classes)
model = softmax.build()
# Create KFold
cv = KFold(n_splits = 5, random_state = 31, shuffle=True)
history = {'acc': [], 'val_acc': [], 'loss': [], 'val_loss': []}
# Train
for train_idx, valid_idx in cv.split(embeddings):
X_train, X_val, y_train, y_val = embeddings[train_idx], embeddings[valid_idx], labels[train_idx], labels[valid_idx]
his = model.fit(x=X_train, y=y_train, batch_size=BATCH_SIZE, epochs=EPOCHS, verbose=1, validation_data=(X_val, y_val))
print(his.history['accuracy'])
history['acc'] += his.history['accuracy']
history['val_acc'] += his.history['val_accuracy']
history['loss'] += his.history['loss']
history['val_loss'] += his.history['val_loss']
[Pytorch]
## Load Packages
import cv2
import torch
use_cuda = torch.cuda.is_available()
import pickle
import argparse
import numpy as np
import torchsummary
import matplotlib.pyplot as plt
from sklearn.model_selection import KFold
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import OneHotEncoder
from torch.utils.data import TensorDataset, DataLoader
from architecture.embedding_learner_pytorch import embedding_classifier
## Define custom dataloader
def custom_dataloader(x, y, batch_size):
if batch_size > len(y):
batch_size = len(y)
tensor_x = torch.tensor(x)
tensor_y = torch.tensor(y, dtype=torch.long)
if use_cuda:
tensor_x = tensor_x.cuda()
tensor_y = tensor_y.cuda()
# one-hot label to class
tensor_y = torch.argmax(tensor_y, dim=1)
my_tensor_dataset = TensorDataset(tensor_x, tensor_y)
return DataLoader(my_tensor_dataset, batch_size=batch_size, shuffle=True)
## Layer weight initialization
def weights_init(m):
if isinstance(m, torch.nn.Linear):
torch.nn.init.xavier_uniform_(m.weight)
torch.nn.init.zeros_(m.bias)
## Do train
def main(args):
## Set epoch and batch_size
EPOCHS = args['epochs']
BATCH_SIZE = args['batch_size']
##Load face embeddings
embedding_data = pickle.loads(open(args['input_embedding_path'], 'rb').read())
print("[INFO] embedding data has been loaded...")
input_embeddings = np.array(embedding_data['embeddings'])
## Encode the labels
sklearn_label_encoder = LabelEncoder()
labels = sklearn_label_encoder.fit_transform(embedding_data['names'])
num_classes = len(np.unique(labels))
labels = labels.reshape(-1, 1)
one_hot_encoder = OneHotEncoder(categories='auto')
labels = one_hot_encoder.fit_transform(labels).toarray()
## Set model
model = embedding_classifier(input_shape=input_embeddings.shape[1], num_classes=num_classes)
model.apply(weights_init)
torchsummary.summary(model, (input_embeddings.shape[1], ))
## define loss
criterion = torch.nn.CrossEntropyLoss()
## define optimizer
optimizer = torch.optim.Adam(model.parameters())
## Create K-Fold
cross_validation = KFold(n_splits=5, random_state=31, shuffle=True)
## Initialize list of training information
history = {'train_acc': [], 'val_acc': [], 'train_loss': [], 'val_loss': []}
## Do training
cv_idx = 0
for train_idx, valid_idx in cross_validation.split(input_embeddings):
cv_idx += 1
print([f'[INFO] {cv_idx}-th cross validation start...'])
X_train, X_val, y_train, y_val = input_embeddings[train_idx], input_embeddings[valid_idx], labels[train_idx], labels[valid_idx]
## Set train Data Loader
train_data_loader = custom_dataloader(x=X_train, y=y_train, batch_size=BATCH_SIZE)
## Set validation Data Loader
valid_data_loader = custom_dataloader(x=X_val, y=y_val, batch_size=BATCH_SIZE)
for epoch in range(EPOCHS):
train_loss = 0.0
train_acc = 0.0
val_loss = 0.0
val_acc = 0.0
for i, data in enumerate(train_data_loader):
x, y = data
## grad init
optimizer.zero_grad()
## forward propagation
model_output = model(x)
## calculate loss
loss = criterion(model_output, y)
## back propagation
loss.backward()
## weight update
optimizer.step()
## calculate trainig loss and accuracy
train_loss += loss.item()
train_preds = torch.argmax(model_output, dim=1)
train_acc += train_preds.eq(y).float().mean().cpu().numpy()
## delete some variables for memory issue
del loss
del model_output
## Print training and validation summary
with torch.no_grad():
for j, val_data in enumerate(valid_data_loader):
model.eval()
val_x, val_y = val_data
val_output = model(val_x)
v_loss = criterion(val_output, val_y)
val_loss += v_loss.item()
## calculate trainig accuracy
val_preds = torch.argmax(val_output, dim=1)
val_acc += val_preds.eq(val_y).float().mean().cpu().numpy()
epoch_train_accuracy = train_acc / len(train_data_loader)
epoch_train_loss = train_loss / len(train_data_loader)
epoch_val_accuracy = val_acc / len(valid_data_loader)
epoch_val_loss = val_loss / len(valid_data_loader)
history['train_acc'].append(epoch_train_accuracy)
history['train_loss'].append(epoch_train_loss)
history['val_acc'].append(epoch_val_accuracy)
history['val_loss'].append(epoch_val_loss)
print("{}-th cross validation | epoch: {}/{} | training loss: {:.4f} | training acc: {:.4f} | val loss: {:.4f}, val acc: {:.4f}".format(
cv_idx, epoch+1, EPOCHS, epoch_train_loss, epoch_train_accuracy, epoch_val_loss, epoch_val_accuracy))
# train_loss = 0.0
# train_acc = 0.0
# val_loss = 0.0
# val_acc = 0.0
## Save the pytorch embedding classifier
torch.save(model.state_dict(), args["model_save_path"])
## Save label encoder
f = open(args["encoded_label_save_path"], "wb")
f.write(pickle.dumps(sklearn_label_encoder))
f.close()
## Plot performance figure
fig, axes = plt.subplots(2, 1, constrained_layout=True)
axes[0].plot(history['train_acc'])
axes[0].plot(history['val_acc'])
axes[0].set_title('model accuracy')
axes[0].set_ylabel('accuracy')
axes[0].set_xlabel('epochs')
axes[0].legend(['train', 'test'], loc='best')
# Summary history for loss
axes[1].plot(history['train_loss'])
axes[1].plot(history['val_loss'])
axes[1].set_title('model loss')
axes[1].set_ylabel('loss')
axes[1].set_xlabel('epochs')
axes[1].legend(['train', 'test'], loc='best')
plt.savefig(args['figure_save_path'], dpi=300)
plt.show()
Thanks for your comments in advance.