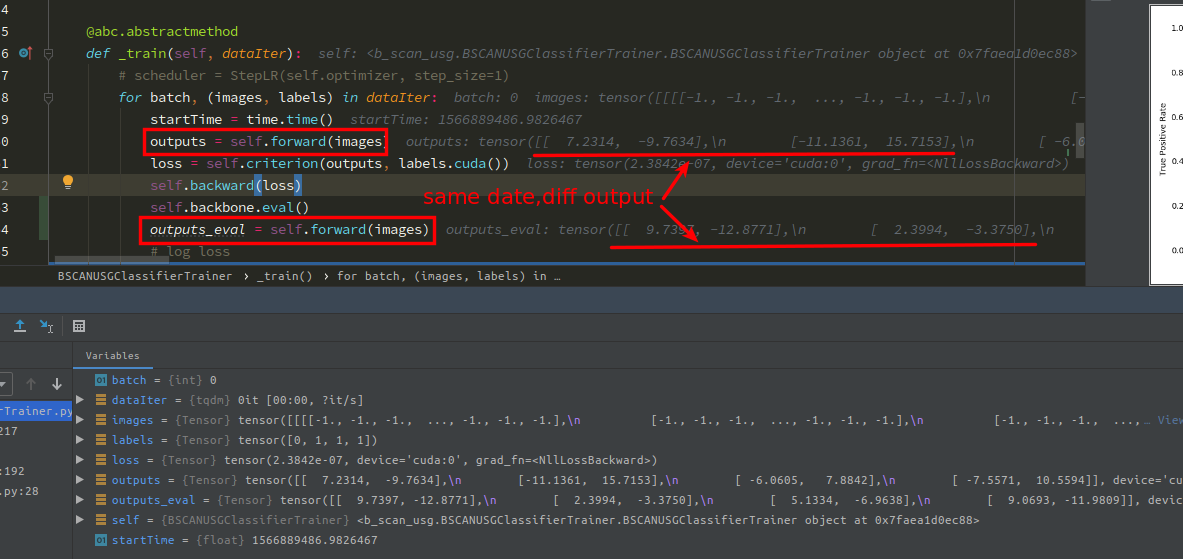
It probably cause by train mode and eval mode are in same for loop.
After one training it updates parameters of your model has, so different result is presented on eval after the train.
If your model has BatchNorm or DropOut modules this behavior is normal. They dont have same behavior in training and eval mode that is why you have different results
My suggestion is to make different loop for train and eval. After finishing for-loop for the train you obtain trained parameters, so you can verify your parameters and your model too.
As @111137 suggested, I think that you should separate the two for loops. That could be something like:
for e in range(nb_epochs):
model.train()
for batch, (images, labels) in dataIterTrain:
optimizer.zero_grad()
do your stuff
model.eval()
with torch.no_grad():
for batch, (images, labels) in dataIterVal:
validate your model
And don’t forget that some modules have different behavior dependently of the mode of the model. So even at the end of the training loop, if you do something like:
Thanks,I actually do training and evaluation in different loop,and got train accuracy raising from 0.5 to 0.995 after several epochs,but evaluation accuracy stays at 0.5(a little bit higher or lower),due to this weird,I put some evaluation data in same loop to check the output in different mode,and found this,so I want to know why?
Let you try to move the import to outside of the loop.
Your program does import every time in every iteration.
And tell me reason why use with torch.no_grad():.
When removing the “import” and the “with” statement, what happen?
So you are using InceptionResNetV2(module) which uses a F.dropout( 0.8 ) module by default. This module will change the behavior of your module in training or eval mode. In training mode, the dropout will supress some connections between the layers to overcome overfiting but in eval mode it will remain all the connection. So the output will change.
Thanks,after moving import torch
outside of the loop,these two outputs are still totally different.
For why using “with torch.no_grad()”:
After commenting out the backward,the computation graph won’t be deleted,and I got a CUDA out of memory exception,so I use torch.no_grad():
to tell pytorch don’t hold computation graph
Let you do the dropout rate = 0.0 as suggestion of @SoucheChapich -san. If result is same then reason is the dropout. If it still shows different number then the train and eval in same loop makes the difference.
Thank,I actually knew this,the problem is that the model already gives me 99.5% training accuracy,but evaluation accuracy remains at 50%,even using training data to do evaluation,the accuracy is still 0.5.and both train and eval accuracy computation used the same code.
That is strange because if you use exactly the same data and that you take care of the dropout, the results should be the same. Can you show us the entire model ? Not just the backbone