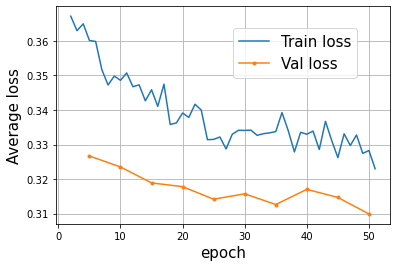
My SSD512 code for object detection works very well when trained on the CPU but does not work well at all when trained on GPU, even if the same PyTorch version and the same initial weights are being used.
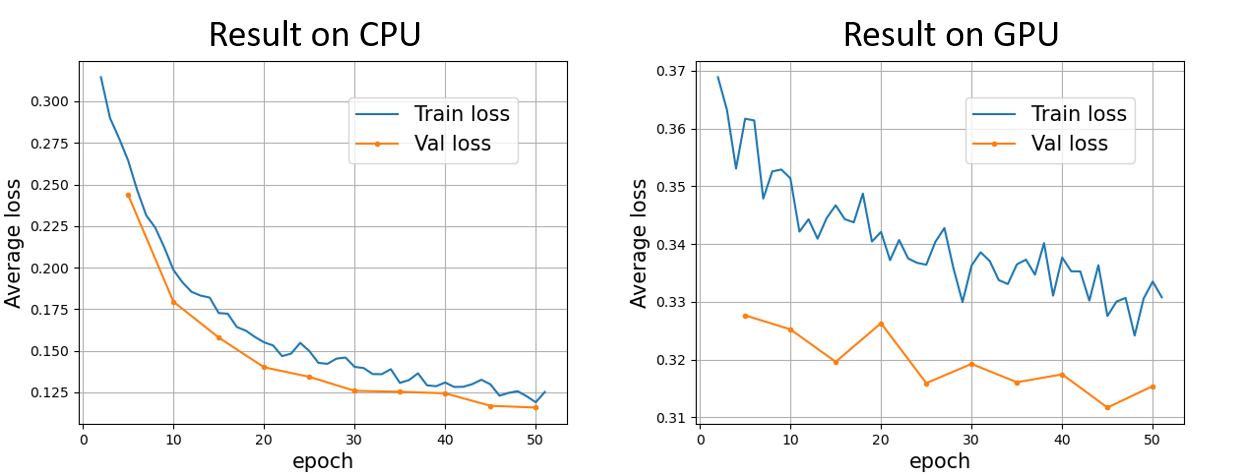
The plot on the left is the convergence of the code on CPU, which is pretty nice but takes a long time for computation. The plot on the right is the convergence on GPU. Although the computation time is 15 times faster than that on CPU, the loss convergence is much slower.
I have been trying to find the cause but cannot figure out the problem.
My main code:
## ------- Import libralies -------------
import os
import time
import pandas as pd
import urllib.request
from glob import glob
import torch
import torch.utils.data as data
import torch.nn as nn
import torch.nn.init as init
import torch.optim as optim
from pandas.core.common import flatten
import csv
import math
# import the necesary code from a directory 'utils'
from utils.dataloader import RareplanesDataset, DataTransform, xml_to_list, od_collate_fn, get_color_mean
from utils.loss import MultiBoxLoss
## ------- Set path to dataset -------------
dir_dataset = './Data_rareplanes/'
# Path to training data
train_image_dir = os.path.join(dir_dataset,'train/images/')
train_img_paths = glob(os.path.join(train_image_dir, '*.*')) # accomodate any extensions
# Path to validation data
val_image_dir = os.path.join(dir_dataset,'val/images/')
val_img_paths = glob(os.path.join(val_image_dir, '*.*'))
# Path to annotation files of training data
train_label_dir = os.path.join(dir_dataset,'train/xmls/')
train_label_paths = glob(os.path.join(train_label_dir, '*.xml'))
# Path to annotation files of validation data
val_label_dir = os.path.join(dir_dataset,'val/xmls/')
val_label_paths = glob(os.path.join(val_label_dir, '*.xml'))
# classlist
my_classes = ["airplane"]
## --------- Average pixel values for each channel ------
color_mean = [143.1487009512939, 136.12215208212658, 134.96655592553213] # RarePlanes
print(color_mean)
## --------- Generate dataset --------
input_size = 512
# Definition of training dataset
train_dataset = RareplanesDataset(train_img_paths, train_label_paths, phase = 'train',
transform = DataTransform(input_size, color_mean),
transform_anno = xml_to_list(my_classes))
# Definition of validation dataset
val_dataset = RareplanesDataset(val_img_paths, val_label_paths, phase = 'val',
transform = DataTransform(input_size, color_mean),
transform_anno = xml_to_list(my_classes))
print('Images in training dataset: ', train_dataset.__len__())
print('Images in validation dataset: ', val_dataset.__len__())
## --------- Generate Data Loader ------
# batch size of dataset
batch_size = 16
print("Batch size: ", batch_size)
train_dataloader = data.DataLoader(
train_dataset, batch_size = batch_size, shuffle = True, collate_fn = od_collate_fn
)
val_dataloader = data.DataLoader(
val_dataset, batch_size = batch_size, shuffle = True, collate_fn = od_collate_fn
)
dataloaders_dict = {"train": train_dataloader, "val": val_dataloader}
## --------- Set parameter values for SSD model ---------
from utils.ssd512_model import SSD
ssd_cfg = {
'num_classes': 2, # airplane + background
'input_size': 512, # resize the input images to 512 x 512
'bbox_aspect_num': [4,6,6,6,6,4,4],
'feature_maps': [64,32,16,8,4,2,1], # [64,32] from VGG, [16,8,4,2,1] from extras
'steps': [8,16,32,64,128,256,512],
'min_sizes': [20,51,133,215,297,379,461], # = [0.04, 0.1, 0.26, 0.42, 0.58, 0.74, 0.90]
'max_sizes': [51,133,215,297,379,461,538], # = [0.1, 0.26, 0.42, 0.58, 0.74, 0.90, 1.05]
'aspect_ratios': [[2],[2,3],[2,3],[2,3],[2,3],[2],[2]]
}
net = SSD(phase='train', cfg = ssd_cfg)
## -------- Initialize the weights -----------------------
# Create a directory for weights
weights_dir = "./weights_xml_CPU/"
if not os.path.exists(weights_dir):
os.mkdir(weights_dir)
url = "https://s3.amazonaws.com/amdegroot-models/vgg16_reducedfc.pth"
target_path = os.path.join(weights_dir, "vgg16_reducedfc.pth")
if not os.path.exists(target_path):
urllib.request.urlretrieve(url, target_path)
vgg_weights = torch.load(os.path.join(weights_dir, 'vgg16_reducedfc.pth'))
net.vgg.load_state_dict(vgg_weights)
def weights_init(m):
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight.data)
if m.bias is not None:
nn.init.constant_(m.bias,0.0)
# Initialize the other weights by the value of He
net.extras.apply(weights_init)
net.loc.apply(weights_init)
net.conf.apply(weights_init)
## ------- Criterion -----------------------------
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
criterion = MultiBoxLoss(jaccard_thresh=0.5, neg_pos = 3, device=device)
## ------- Optimizer -----------------------------
optimizer = optim.Adam(net.parameters(), lr=1e-04, betas=(0.9, 0.999), eps=1e-08,
weight_decay=0, amsgrad=False)
#
## ------- Training & Validation ---------------------------
#
## ------- Training & Validation ---------------------------
def train_model(net, dataloaders_dict, criterion, optimizer, num_epochs, epoch_origin, name_save):
# Definition of used device
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("Used Device:", device)
# If a GPU is used, pass the network to GPU
net.to(device)
# If the network is somewhat fixed, accerelate the training
torch.backends.cudnn.benchmark = True
# Number of images
num_train_imgs = len(dataloaders_dict["train"].dataset)
num_val_imgs = len(dataloaders_dict["val"].dataset)
batch_size = dataloaders_dict["train"].batch_size
iteration = 1
epoch_train_loss = 0.0
epoch_val_loss = 0.0
logs = []
# Start training
for epoch in range(num_epochs+1):
epoch_st = epoch + epoch_origin
t_epoch_start = time.time()
t_iter_start = time.time()
print('------------')
print('Epoch {}/{}'.format(epoch_st+1, num_epochs+epoch_origin))
print('------------')
for phase in ['train', 'val']:
if phase == 'train':
net.train()
print(' (train) ')
else:
# Display the loss for validation image every 10 epoch
if ((epoch+1) % 5 == 0):
net.eval()
print('----------')
print(' (val) ')
else:
continue
for images, targets in dataloaders_dict[phase]:
images = images.to(device)
targets = [ann.to(device) for ann in targets]
optimizer.zero_grad()
with torch.set_grad_enabled(phase=='train'):
outputs = net(images)
# Loss function = loss_l(position of bbox) + loss_c(classification)
loss_l, loss_c = criterion(outputs, targets)
loss = loss_l + loss_c
if phase == 'train':
loss.backward()
nn.utils.clip_grad_value_(
net.parameters(), clip_value = 2.0
)
optimizer.step()
# Display elasped time and loss every 10 itereation
if (iteration % 10 ==0):
t_iter_finish = time.time()
duration = t_iter_finish - t_iter_start
print('Iteration {} || Loss: {:.4f} || 10iter:{:.4f} sec.'.format(
iteration, loss.item()/batch_size, duration))
t_iter_start = time.time()
epoch_train_loss += loss.item()
iteration += 1
else:
epoch_val_loss += loss.item()
t_epoch_finish = time.time()
print('------------')
print('epoch {} || Epoch_TRAIN_Loss:{:.4f} || Epoch_VAL_Loss:{:.4f}'.format(
epoch_st+1, epoch_train_loss/num_train_imgs, epoch_val_loss/num_val_imgs))
print('timer: {:.4f} sec.'.format(t_epoch_finish - t_epoch_start))
t_epoch_start = time.time()
log_epoch = {'epoch': epoch_st+1,
'train_loss': epoch_train_loss/num_train_imgs,
'val_loss': epoch_val_loss/num_val_imgs}
logs.append(log_epoch)
df = pd.DataFrame(logs)
df.to_csv(os.path.join(weights_dir, "log_output_epoch"+str(num_epochs)+".csv"))
epoch_train_loss = 0.0
epoch_val_loss = 0.0
# Save weights every 10 epochs
if ((epoch+1)%10 ==0):
torch.save({
'epoch': epoch+1,
'model_state_dict': net.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'loss': criterion,
}, name_save+str(epoch_st+1)+'.pth')
# ---- Input
epoch_origin = 0
num_epochs = 50
# Name the file to save
name_save = weights_dir + 'SSD' + str(ssd_cfg['input_size']) + '_'
# -----
# TRAIN
train_model(net, dataloaders_dict, criterion, optimizer,
num_epochs = num_epochs,
epoch_origin = epoch_origin,
name_save = name_save)
My environment on GPU:
dependencies:
- _libgcc_mutex=0.1
- _openmp_mutex=4.5
- ca-certificates=2021.7.5
- certifi=2021.5.30
- ld_impl_linux-64=2.35.1
- libffi=3.3
- libgcc-ng=9.3.0
- libgomp=9.3.0
- libstdcxx-ng=9.3.0
- ncurses=6.2
- openssl=1.1.1k
- pip=21.2.2
- python=3.8.5
- readline=8.1
- setuptools=52.0.0
- sqlite=3.36.0
- tk=8.6.10
- wheel=0.36.2
- xz=5.2.5
- zlib=1.2.11
- pip:
- numpy==1.21.1
- opencv-python==4.5.2.52
- pillow==8.3.1
- torch==1.9.0+cu111
- torchcontrib==0.0.2
- torchvision==0.10.0+cu111
- typing-extensions==3.10.0.0
Here is the list of posts I found on the PyTorch forum and other sources but none of them solved my problem.
- [Same model running on GPU and CPU produce different results]
Based on this, I created the optimizer after the model is moved to GPU but it did not solve my problem. - [Different loss for cpu and gpu]
Based on this, I disabledTensorFloat-32(TF32)option but it did not solve my problem.
torch.backends.cuda.matmul.allow_tf32 = False
torch.backends.cudnn.allow_tf32 = False
- PyTorch: training with GPU gives worse error than training the same thing with CPU Based on this, I disabled CUDNN but it did not solve my problem.
torch.backends.cudnn.enabled = False
I appreciate any help. Here is the link to the rest of my code used in the main code: