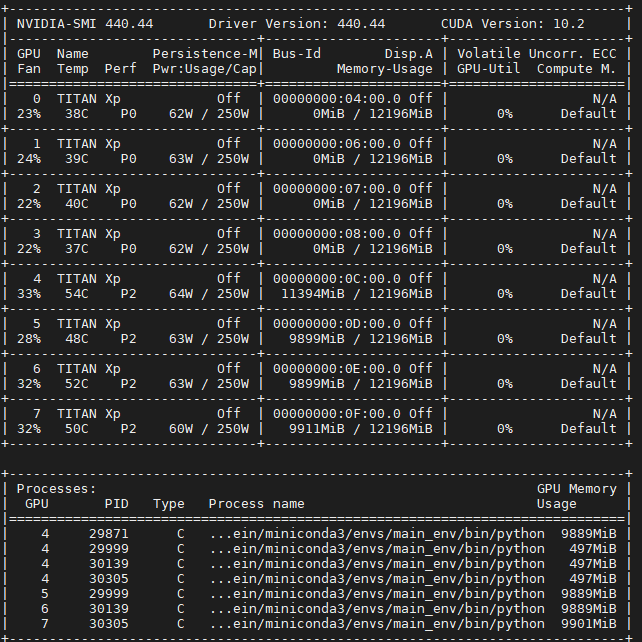
When I run a model with DDP with 4 spawned processes and each process taking a GPU, I notice that there are a lot of spawned processes with nvidia-smi on the main process. Why are there so many additional processes spawned? I am also using torch=1.4.0 and CUDA=10.1.243 which is installed through my conda environment.
See discussion `torch.distributed.barrier` used in multi-node distributed data-parallel training
For more detailed explainations, cc @mrshenli
I took a look at that, but I am a little confused as it still. Is it a back-end issue, or is it normal behaviour?
should be normal,depending on the backend
It seems to happen with both nccl and gloo backends.
Maybe ask @mrshenli, I am not fully clear about their internal implementations.
So I played around a little more by breaking my pipeline to a very simple training loop, just to ensure I wasn’t doing anything wrong. I then cloned my conda environment and updated the torch and cuda to the versions listed on the Getting Started page (the most up-to-date) and it seems to fix the issue. So I’m not sure if it was a cuda, nccl (in the cudatoolkit), or the updated torch, but updating does fix it.
Those (~500MB CUDA memory consumption) look like CUDA context. It seems all processes somehow used CUDA:0 somewhere. It could be caused by 3rd-party libraries or calls like torch.cuda.empty_cache(). If you don’t want to debug the root cause of it, you can avoid it by setting CUDA_VISIBLE_DEVICES env var to make sure that each process only sees one GPU.
I updated both my torch and cudatoolkit (with conda) to the newest versions which seemed to fix the problem. I’m not sure if it was cuda, torch or how torch interacted with cuda, but updating seems to have fixed the bug. I’m not sure if this improves anything though, but the extra processes don’t show up anymore.