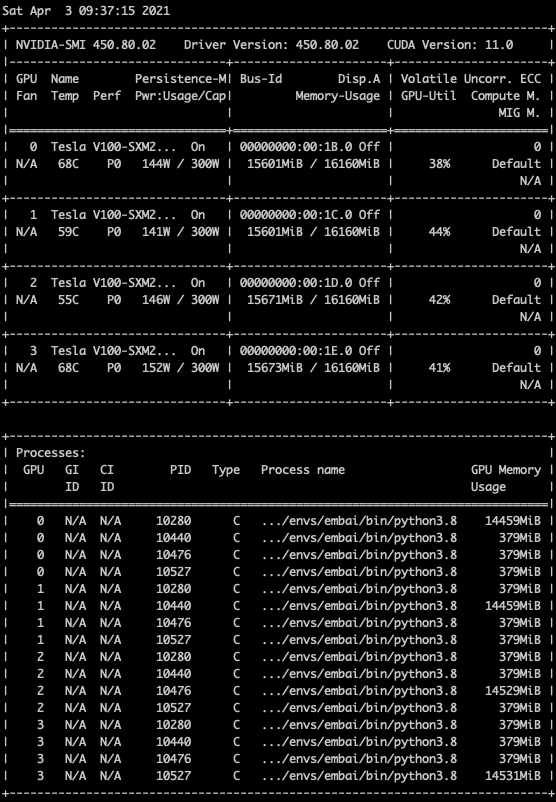
I guess that you are using a distributed training setup (via DDP).
If that’s the case, it seems that the setup is incorrect, as apparently each process creates a new CUDA context on each device. I’m not familiar with Lightning, but you could check, if your script only uses the specified GPU and doesn’t allocate tensors on all visible devices.
You could check, if all devices are visible in each process and check then for to('cuda') or cuda() calls.
If these operations are used, the tensor or module would be moved to the default device (GPU:0) in each process and could thus create multiple CUDA contexts.
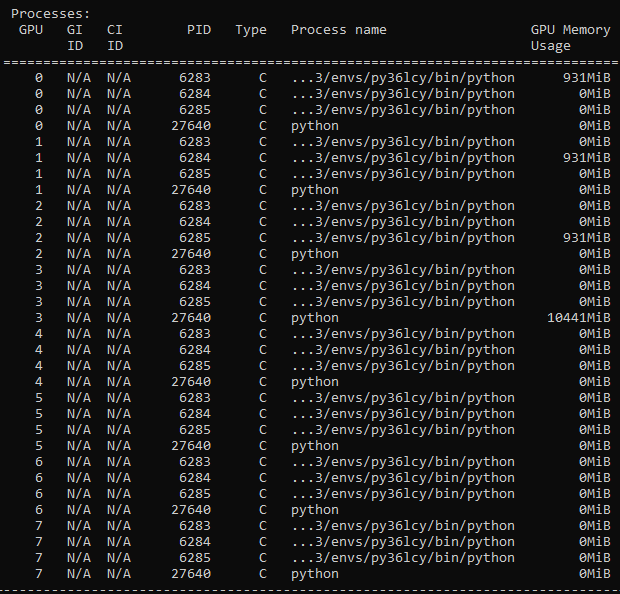
I have met a similar problem.And I am learning how to use ‘DistributedDataParallel’.And it’s really strange that why there are extre processes per GPU that are consuming 0 GPU ram.
And my Command line argument was ‘python mnist.py -n 1 -g 3 -nr 0’
PID 6283 6284 6285 are my processes.And GPU 3 is being used by others
my dependencies: pytorch == 1.6.0 torchvision == 0.7.0 CUDA 10.2 3 x RTX 2080Ti