Hi, I am dealing with a spintronic problem where the loss is a Hamiltonian of the type:
energy = 0
for i in range(self.Npbits):
tmp = 0.5 * torch.dot(self.J[i], pbits) + self.h[i]
energy -= tmp * pbits[i]
return energy
J is a square matrix, and J[i] one of its lines. pbits is a vector of the same length.
I doubt this solution will not allow the gradient to be automatically computed because of the “for” loop and because I’m taking the rows of J by indexing. Am I wrong? Is there a definitive guide to writing custom code that can be autograd-able?
Thank you! Indeed I was approaching that kind of solution with matmul e dot, I didn’t know einsum, very useful…
The solution works and the network backpropagates effectively.
Since you’ve been so kind, I’m going to bother you with another similar problem
This time the gradient is harder to compute, since it uses a sign function (which I replaced with a tanh and a strong multiplying factor) and conditionals inside a for loop.
The original code is the following:
loss = 0
pbits_variables = self.pbits[self.index_variables]
for i, clause in enumerate(self.clauses):
truth_value = 0
for variable in clause:
if pbits_variables[np.abs(variable) - 1] * np.sign(variable) > 0:
truth_value = 1
break
self.loss += (1 - truth_value)
clauses are a list of rows of numbers (inside a list), therefore for each number in a clause the if checks whether the > 0 condition is verified, and in that case, it breaks and says that truth_value = 1. I can do the same checking the condition on the array and using clamp, so that the truth_value is 1 if at least one element in the array is > 0.
I have devised this code:
pbits_variables = pbits[:,self.index_variables]
cost = torch.zeros(1, requires_grad=True)
for i, c in enumerate(self.clauses):
truth_value = torch.zeros(1, requires_grad=True)
clause = torch.from_numpy(np.array(c))
v = pbits_variables[:,torch.abs(clause) - 1] * nn.functional.tanh(DENORM_BETA*clause)
truth_value = torch.clamp(torch.sum(v > 0), max=1)
cost += (1 - truth_value)
I’ve probably missed something since the last line bumps this error message.
RuntimeError: a leaf Variable that requires grad is being used in an in-place operation.
You are right, just using cost = cost + … instead of += is the way to go.
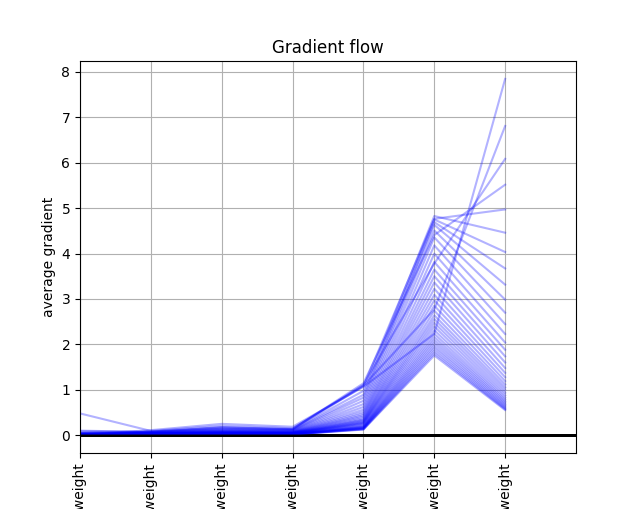
I am facing convergence issues but that is probably related to the nature of the problem. I can see a nonzero gradient flow through the network, therefore the loss as I coded it should be able to compute the gradient automatically. This seems to me quite sound… (PS: the plot is done according to this old discussion Check gradient flow in network - #7 by RoshanRane)