Hello,
I have seen some questions related to using tensorboard with DistributedDataParallel(DDP) on the forum but I haven’t found a definitive answer to my question.
For instance, I wish to log loss values to tensorboard. When not considering DDP my code looks like the following for a loss item
loss_writer.add_scalar('Overall_loss', overall_loss.item(), total_iter)
where loss_writer = torch.utils.tensorboard.SummaryWriter(loss_dir).
Now, when considering DDP I included as recommended here to include
if args.rank == 0 :
loss_writer.add_scalar('Overall_loss', overall_loss.item(), total_iter)
However, when doing so, I obtain something that looks like this
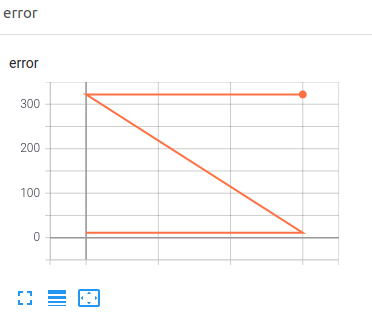
which has been evoked in here.
Any idea on how to obtain a smooth loss graph as on single-GPU training ?
Thanks !