No, not really. I think the loss is pretty low from the start because of the size of the images. As you have a big image, most of the pixel will be given a low probability from the start (as all the probability for a given map should sum to 1). The ground truth heatmap also have most of the pixel with a low probability, only around the keypoint you’ll get a significant value in the expected probabilities. When you compute the MSE, most of your points will be viewed as ‘close to target’, only (mostly) the points close to the keypoints will be viewed as ‘far from the target’ from MSE point of view. As you average by the size of the image, the overall MSE loss will be quite low right from the start.
In the other hand, you may have a really different order of loss magnitude if try using KL divergence.
It’s not easy to interpret the loss, that’s why you generally wants to plot some other metric more easier to interpret while the network is trained. For your case, you could compute the euclidean distance between the ground truth keypoints from the pixel that was given the highest probability by your model for instance. If you really want to interpret your loss, you have to keep in mind both the properties of the loss you use AND the properties of the data you train with, sometimes the loss is just not a good performance indicator at all.
Oh just a last thing by the way, I saw you used torch.nn.Softmax(dim)(input). torch.nn.Softmax is a pytorch module, but as you do not keep the module in memory you can use directly the softmax function torch.nn.functional.softmax, with torch.nn.functional.softmax(input, dim). It would slightly clearer to read and maybe a bit faster than redefining a module each time
Hey Thomas,
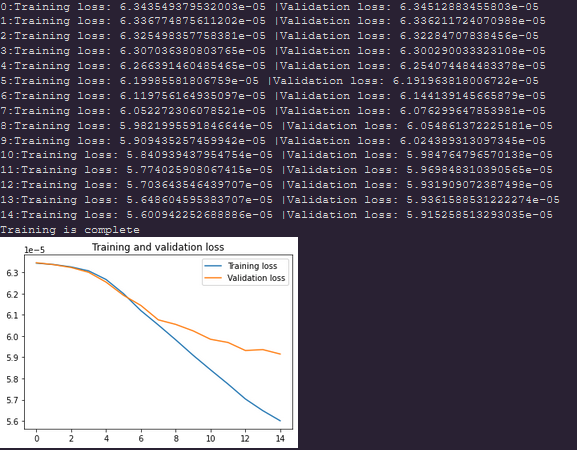
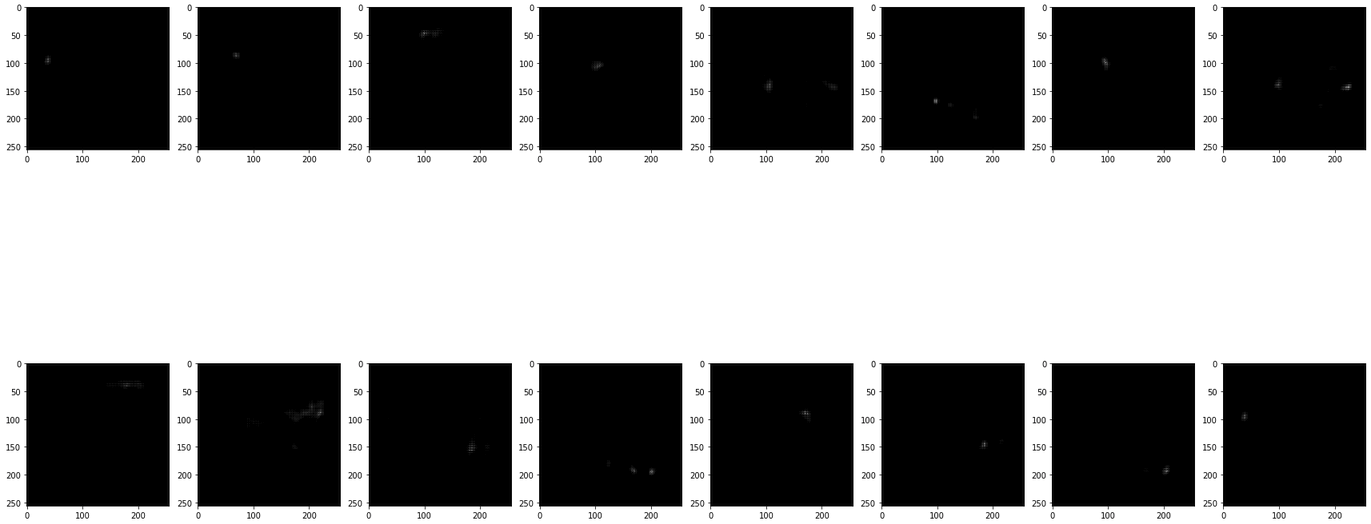
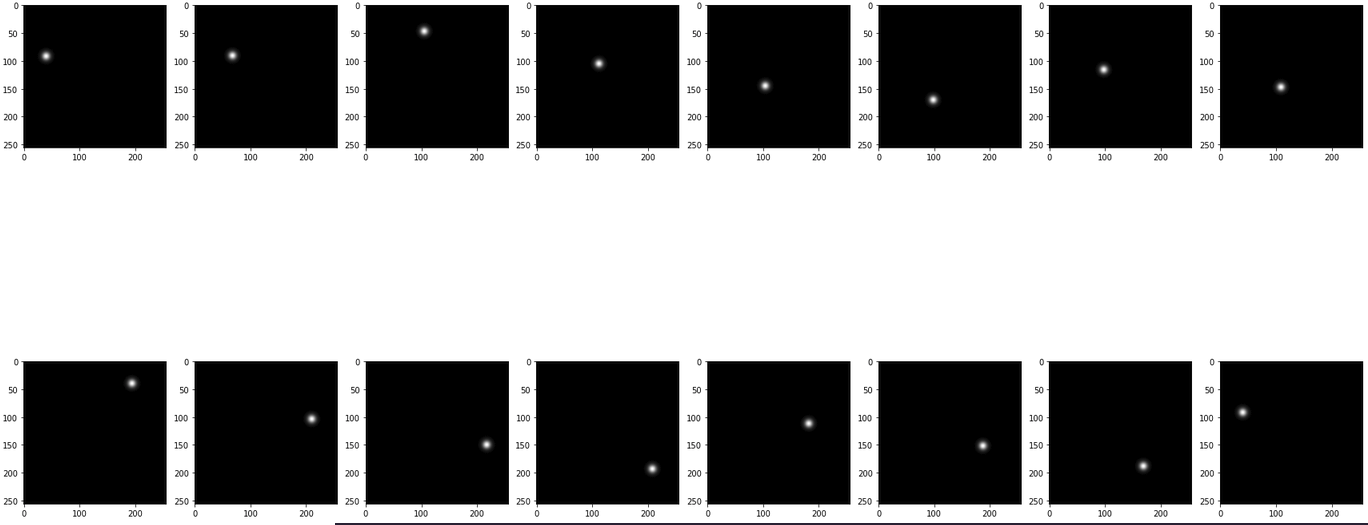
I want to share with you the outcome of using KL-divergence as the loss. The predictions look noisier in comparison with using softmax+mse. Also, the loss is a bit large in number(can’t say the model doesn’t learn something).
train/val loss from using KL-divergence:Adam(lr =1e-4, ams_grad)
train/val loss from using MSE:Adam(lr =1e-3, ams_grad)
Thanks for the feedback ! I’m not surprise the KL loss values are higher than mse ones, I used a few times KL-loss and got values of roughly the same order of magnitude as your numbers (especially during the firsts training iterations). Yeah the configuration with KL seems to produce more noisy predictions here, not sure why. Maybe I’m over-interpreting, but it seems we can almost guess some of the cows outlines when looking the predictions using KLdivergence, that’s fun.
I hope you’ll be successful in your project! Have a nice day,
Thomas