I’m just not sure to get the difference between the two experiments. So, in the first one you used the flatten trick to apply softmax on the spatial dimensions, and on the second one you applied the softmax across the channels (dim=1), is that correct? - Yes, indeed
Ok, I think I now why the second one looks better (but it’s not actually).
Could you re-try both experiments but using the following one-hot heatmap:
heatmap = torch.zeros(1,16,1,160,160).to(DEVICE)
heatmap[0,:,0,80,80] = 1.
?
Applying case 1:
def forward(self, image):
"""PUTTING THE MODEL TOGETHER"""
encoder = self.encoder(image)
decoder = self.decoder(encoder)
decoder_shape = decoder.shape
return torch.nn.Softmax(dim=1)(decoder)
Applying case2:
def forward(self, image):
"""PUTTING THE MODEL TOGETHER"""
encoder = self.encoder(image)
decoder = self.decoder(encoder)
decoder_shape = decoder.shape
flatten_decoder = decoder.view(decoder_shape[0], decoder_shape[1], -1)
flatten_heat_map = torch.nn.Softmax(dim=2)(flatten_decoder )
return flatten_heat_map.view(decoder_shape)
Mmmmh, this one-hot heatmap is encoding the key points of every map under the same pixel (the central one). It’s an extreme, but not formally impossible, configuration. In this case, the softmax on dim= 1 should not be able to solve the task at all, it should just learn to output the same probability to each class instead of learning to locate the keypoints. If we look at the magnitude of the losses in the two experiment, the second one do a better job, but the losses does not move, maybe you should try with different learning rate to see the losses moving?
I advice you to plot the results, take one map (the first one for instance), and look at the values. I bet that the first experiment you’ll get values close to 1/16 everywhere, while in the 2nd experiment you will get value close to 0 everywhere except for the pixel of coordinate (80,80) which should be close 1. Could you check that?
I hope we are close to the solution
Hey Thomas, I tried to change the learning rate in case2:
It looks like this
If this is what you meant in the above message:
case 1 output looks like
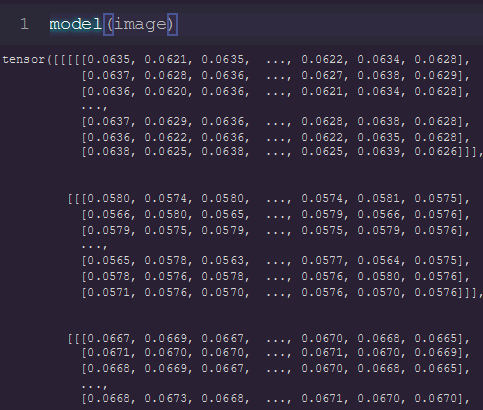
Yes exactly! And could you also print(model(image)[0,:,0,80,80]) ? To see if values are close to 1 in experiement 2, while still being close to 0.0625 (=1/16) in experiment 1?
For,
def forward(self, image):
"""PUTTING THE MODEL TOGETHER"""
encoder = self.encoder(image)
decoder = self.decoder(encoder)
decoder_shape = decoder.shape
return torch.nn.Softmax(dim=1)(decoder)

Using the below code:
def forward(self, image):
"""PUTTING THE MODEL TOGETHER"""
encoder = self.encoder(image)
decoder = self.decoder(encoder)
decoder_shape = decoder.shape
# return torch.nn.Softmax(dim=1)(decoder)
flatten_decoder = decoder.view(decoder_shape[0], decoder_shape[1], -1)
flatten_heat_map = torch.nn.Softmax(dim=2)(flatten_decoder )
return flatten_heat_map.view(decoder_shape)
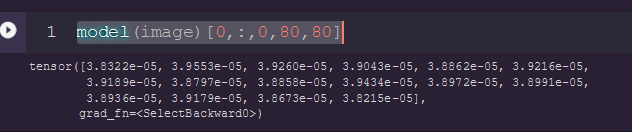
Something is really weird, isn’t there a confusion between case 1 and case 2 compared to your previous message ? Because according to the results you posted, case 1 learnt to do the opposite of task (lower probability under the key points than everywere else).
I have changed the earlier message on what code i used and its respective output produced
Thanks, there is still to dig. I do not have time to continue right now, so I’ll come back to you later.
For me the case torch.nn.Softmax(dim=1)(decoder) should not be consistent with heatmap, while torch.nn.Softmax(dim=2)(flatten_decoder ) should be. In other word, the case torch.nn.Softmax(dim=1)(decoder) output class distributions (so summing along channels should sum to 1), while torch.nn.Softmax(dim=2)(flatten_decoder ) output spatial distributions (so summing along the spatial dimension should sum to 1). Do you agree that in your paper the heatmap are composed of spatial distributions ? If yes, then you can give up the torch.nn.Softmax(dim=1)(decoder) case.
Now there is still to understand why the network does not seems to learn…
See you later 
Thomas
1 Like
Thanks for taking the time to help me out. The heatmaps are just the Gaussian distributions centred around a particular key point in the case of the target. In the paper, it should be the compositions of spatial distributions as you mentioned. What I think is that when I use torch.nn.Softmax(dim=1)(decoder) the model is able to learn some features about the heatmaps but with the loss stuck around the same point
ref:Compute mse_loss() with softmax() - #8 by Mukesh1729
See you later then
Hey Thomas,
Why would you do torch.nn.Softmax(dim=2)(flatten_decoder )? I tried to apply what you said but the training slows down drastically with the softmax. You think i could try something else
Hi,
Well, as you said (and as the paper explain it), the heatmaps are Gaussian distributions centered around a particular key point of coordinates [x,y]. So with image of size X*Y, a batch of size N, and a number of heatmaps K, your target should have the shape (N, K, X, Y). Following the description of the heatmaps, you want your model to output K independent distributions over (X,Y). That’s why you need torch.nn.Softmax(dim=2)(flatten_decoder) (with flatten decoder having for shape (N, K, X*Y) ). If you try to use torch.nn.Softmax(dim=1), then your model will output X*Y independent distributions over K classes, which is not what you want at all.
I think you should try to perform some test with your real data and their gaussian targets heatmaps. Play a bit with the learning rate. If the model still hardly train, you may want to check if replacing the MSE loss by a KL-loss can help (we cannot use Cross-entropy as the targets are Gaussian distributions, CE expects one-hot targets). To do that, you should use the following code for the forward of your model:
def forward(self, image):
"""PUTTING THE MODEL TOGETHER"""
encoder = self.encoder(image)
decoder = self.decoder(encoder)
decoder_shape = decoder.shape
flatten_decoder = decoder.view(decoder_shape[0], decoder_shape[1], -1)
flatten_log_heatmap = torch.nn.functional.log_softmax(flatten_decoder, dim=2)
# return heatmap in log-probabilities for KL-loss
return flatten_log_heatmap.view(decoder_shape)
And use this function as criterion:
def criterion(predictions, target_heatmaps):
"""Compute KL-divergences w.r.t `K` independent heatmaps.
The returned loss is the sum of all the computed KL-divergence, averaged for the batch.
args:
predictions: tensor
Tensor of log-probabilities of shape (`N`,` K`, ...). Where `N` is the batch size, and `K` the number of independent heatmaps.
target_heatmaps: tensor
Tensor of probability distribution, same shape as `predictions` argument.
output:
loss: tensor scalar
Reduced total loss
"""
k_heatmaps = prediction.shape[1]
# Compute KL-divergence for each heatmap independently and sum them
loss = 0
for i in range(k_heatmaps):
loss += torch.nn.functional.kl_div(predictions[:,i,...], target_heatmaps[:,i,...], reduction='batchmean')
return loss
Hope you can make it work !
Thomas
1 Like
Hey Thomas, thanks for getting back.
I got a suggestion from elsewhere in the morning (below) because like you said the softmax may be over the spatial distributions and not over the channels. What do you think?
Also, isn’t the kl divergence for probability distribution functions. In my case only the output is a probability
x = torch.randn(1,16,1,256,256)
s = torch.nn.Softmax(dim=3)
activations = s(x.view(1,16,1,-1))
activations = activations.view(1,16,1,256,256)
this should apply softmax on the spatial dimension,which i assume are last two.
The suggestion you got is equivalent to mine (for a batch of size 1), so I agree. Just have a look to the view and the dimension where the softmax is applied. Do you get it that it is equivalent ? When someone is giving you some advice on ML, that’s really important you try to understand it by yourself too see if it really fit your case. Else you’ll be confused and may take bad advice.
KL divergence is indeed a mathematical tool to compare probability distribution, but in our case we are playing with discrete probability distributions (as the image is not continuous but composed of pixels). Kl divergence is well defined for discrete case see wikipedia.
1 Like
Hey Thomas,
Thanks for sharing your viewpoint, it was good advice.
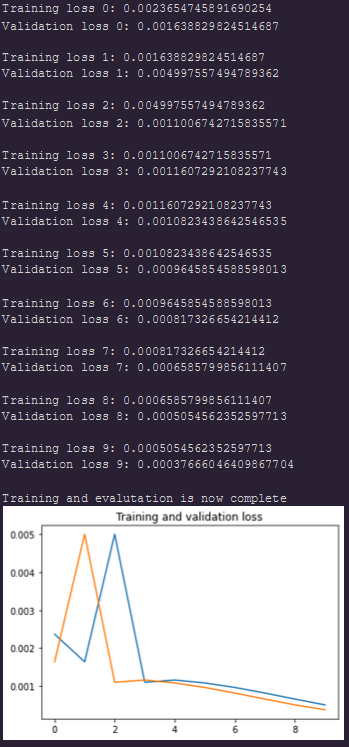
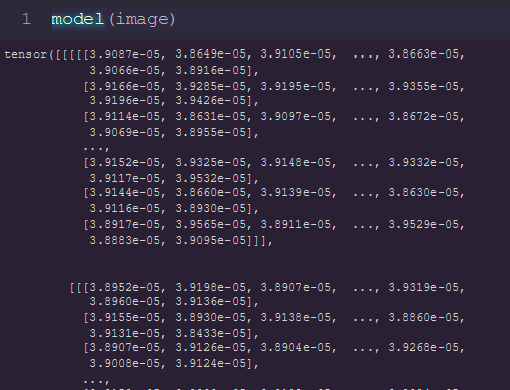
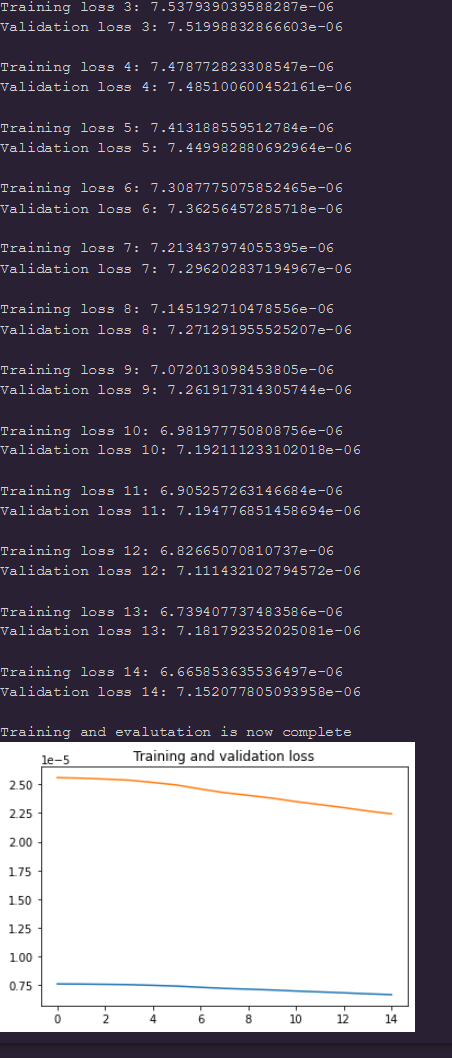
I want to share with you the output from the model and in terms of the prediction it looks like approximately like what it should be but the loss curves look strange (below)
prediction:
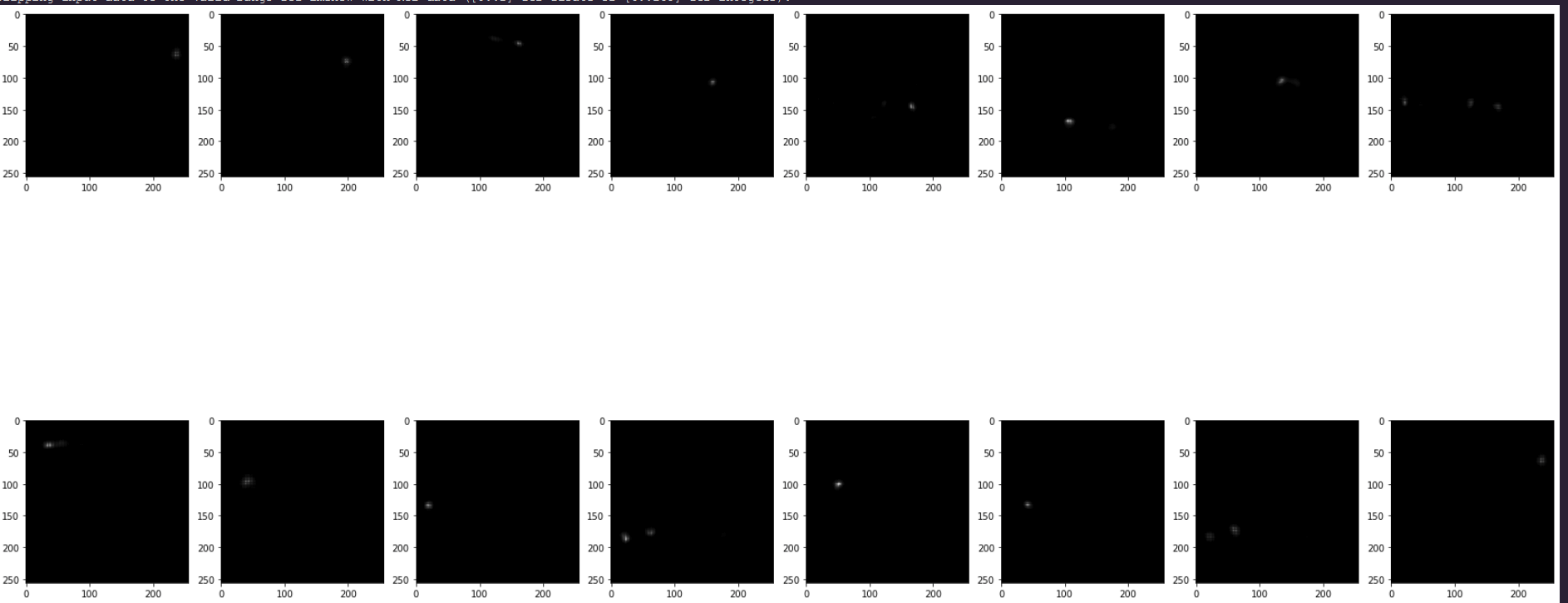
Happy to see it start to works =D
Was it with KL-loss or mse with a different learning rate?
For your training curves, so blue is train and orange is validation (recalling from previous messages). The weird thing is that the values displayed in your terminal does not seems to correspond to the orange curve in the graph you plot, it seems like the plotted curve is up-scaled by some factor. The blue curve seems consistent with the values displayed in the terminal. You should double check how you plot your curve i think.
It was using the mse loss with the same learning rate (1e-3) with Adam(no amsgrad). I will try to apply the KL divergence later today and then get back to you with the outcome. I just realized that validation curves seem a bit weird, It was a mistake i made
Great! That’s good you can reproduce the training from the paper =D
I’m curious to know if the KL-loss works well in your case or not. Just be cautious, you may have to change the learning rate when switching the loss function. By intuition, I would say that you need a lower LR with KL-loss than MSE. Also, you may have some stability issues with the KL loss.
If now your training goes well, do not forget to accept an answer as solution 
Thomas
1 Like
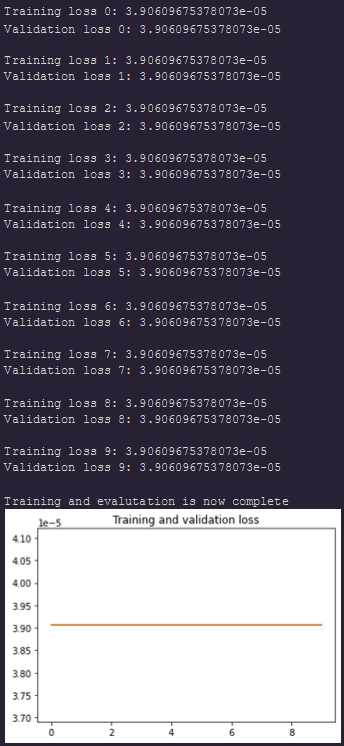
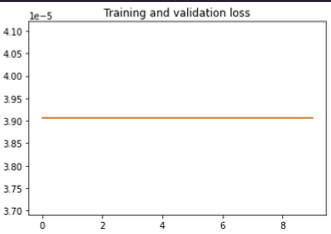
Hey Thomas, I have a general question that I have come across research papers. The training loss is a high value and then starts to decrease slowly over the epochs as the model learns. Over here is small from the start. Does that mean the model is able to learn well from beginning and then stops learning much because the loss doesn’t improve very much over time