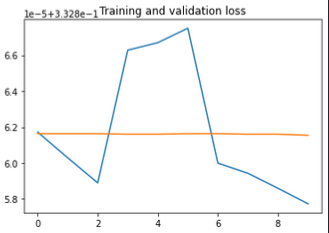
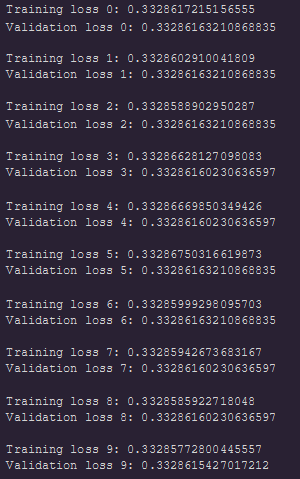
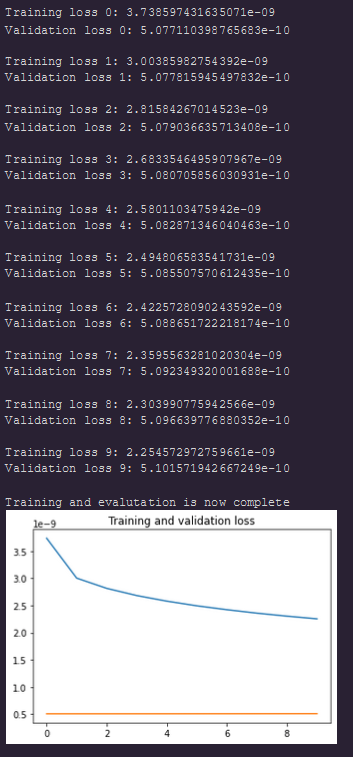
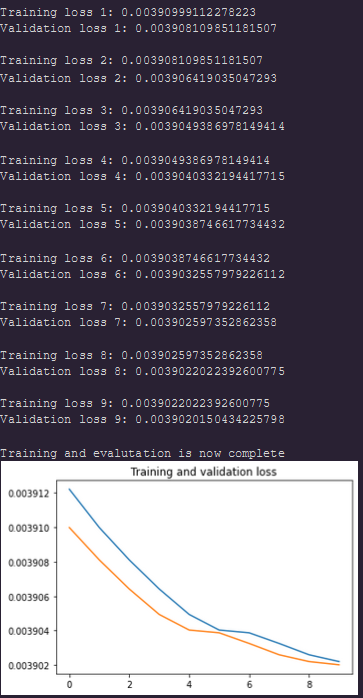
Hey Thomas, I tried what you suggested and the outcome looks like the given plot
class T_LEAP(nn.Module):
"""T_LEAP ARCHITECTURE"""
def __init__(self):
super(T_LEAP, self).__init__()
self.encoder = torch.nn.Sequential(
torch.nn.Conv3d(3, 64, kernel_size=(3,3,3), stride=(1,1,1), padding=(1,1,1)),
torch.nn.BatchNorm3d(num_features=64),
torch.nn.ReLU(inplace=True),
torch.nn.MaxPool3d(kernel_size=(1,2,2),stride=(1,2,2)),
torch.nn.Conv3d(64, 128, kernel_size=(3,3,3), stride=(1,1,1), padding=(1,1,1)),
torch.nn.BatchNorm3d(num_features=128),
torch.nn.ReLU(inplace=True),
torch.nn.MaxPool3d(kernel_size=(2,2,2),stride=(2,2,2)),
torch.nn.Conv3d(128, 256, kernel_size=(3,3,3), stride=(1,1,1), padding=(1,1,1)),
torch.nn.BatchNorm3d(num_features=256),
torch.nn.ReLU(inplace=True),
torch.nn.MaxPool3d(kernel_size=(1,2,2),stride=(1,2,2)),
torch.nn.Conv3d(256, 512, kernel_size=(1,3,3), stride=(1,1,1), padding=(1,1,1)),
torch.nn.BatchNorm3d(num_features=512),
torch.nn.ReLU(inplace=True),
)
self.decoder = torch.nn.Sequential(
torch.nn.ConvTranspose3d(512, 256, kernel_size=(1,3,3), stride = (1,2,2), padding=(1,1,1), output_padding=(0,1,1)),
torch.nn.BatchNorm3d(num_features=256),
torch.nn.ReLU(inplace=True),
torch.nn.Conv3d(256, 256, kernel_size=(1,3,3), stride=(1,1,1), padding=(1,1,1)),
torch.nn.BatchNorm3d(num_features=256),
torch.nn.ReLU(inplace=True),
torch.nn.ConvTranspose3d(256,128, kernel_size=(1,3,3), stride = (1,2,2), padding=(1,1,1),output_padding=(0,1,1)),
torch.nn.BatchNorm3d(num_features=128),
torch.nn.ReLU(inplace=True),
torch.nn.Conv3d(128, 128, kernel_size=(1,3,3), stride=(1,1,1), padding=(1,1,1)),
torch.nn.BatchNorm3d(num_features=128),
torch.nn.ReLU(inplace=True),
torch.nn.ConvTranspose3d(128,16, kernel_size=(1,3,3), stride = (1,2,2), padding=(1,1,1),output_padding=(0,1,1))
)
def forward(self, image):
"""PUTTING THE MODEL TOGETHER"""
encoder = self.encoder(image)
decoder = self.decoder(encoder)
decoder_shape = decoder.shape
flatten_decoder = decoder.view(decoder_shape[0], decoder_shape[1], -1)
flatten_heat_map = torch.nn.Softmax(dim=2)(flatten_decoder )
return flatten_heat_map.view(decoder_shape)
model = T_LEAP()
if torch.cuda.is_available():
input = torch.rand(1,3, 2, 256, 256).cuda()
model = model.cuda()
print("Output image shape:",model(input).shape)
else:
summary(model,
input_size=(3, 2, 200, 200),
batch_size=1
)
print("************************************************")
# torch.cuda.memory_summary(device=None, abbreviated=False)
Sample training loop:
#Get parameters, start training model
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
EPOCHS = 10
lr = 1e-3
model = T_LEAP()
criterion = torch.nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(),lr=lr, amsgrad=True)
model = model.to(DEVICE)
# def softXEnt(input, target):
# logprobs = torch.nn.functional.log_softmax (input, dim = 1)
# return -(target * logprobs).mean()
tr_losses =[]
val_losses=[]
def loss_plot(epochs, train, val):
ep = [i for i in range(epochs)]
plt.plot(ep,train,label="Training loss")
plt.plot(ep,val,label="Validation loss")
plt.title("Training and validation loss")
plt.show()
image = torch.rand(1,3,2,160, 160).to(DEVICE)
heatmap = torch.rand(1,16,1,160,160).to(DEVICE)
for idx in range(EPOCHS):
model.train()
# Get images and transfer to GPU
image = image
heatmap = heatmap
optimizer.zero_grad()
output = model(image)
loss = criterion(output,heatmap)
loss.backward()
optimizer.step()
curr_trloss = loss.item()
# Print losses
print(f"Training loss {idx}:",curr_trloss/1)
# Evaluation loop
model.eval()
with torch.no_grad():
# Get images and transfer to GPU
image = image
heatmap = heatmap
output = model(image)
loss = criterion(output,heatmap)
curr_valoss = loss.item()
print(f"Validation loss {idx}:",curr_valoss/1)
print(" ")
tr_losses.append(curr_trloss/1)
val_losses.append(curr_valoss/1)
print("Training and evalutation is now complete")
loss_plot(EPOCHS,tr_losses, val_losses)
Output
yellow - validation curve (sorry about the legends)