I tried to use a suggested modification inspired by this Medium article due to lost gradient as a result of data copying operation to other device.
However, the output for the for loop below is still the same:
for name, param in graph.named_parameters():
print(name, param.grad)
# https://github.com/D-X-Y/AutoDL-Projects/issues/99
import torch
import torch.utils.data
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
# import numpy as np
torch.autograd.set_detect_anomaly(True)
USE_CUDA = torch.cuda.is_available()
# https://arxiv.org/pdf/1806.09055.pdf#page=12
TEST_DATASET_RATIO = 0.5 # 50 percent of the dataset is dedicated for testing purpose
BATCH_SIZE = 4
NUM_OF_IMAGE_CHANNELS = 3 # RGB
IMAGE_HEIGHT = 32
IMAGE_WIDTH = 32
NUM_OF_IMAGE_CLASSES = 10
SIZE_OF_HIDDEN_LAYERS = 64
NUM_EPOCHS = 1
LEARNING_RATE = 0.025
MOMENTUM = 0.9
NUM_OF_CELLS = 8
NUM_OF_MIXED_OPS = 4
NUM_OF_PREVIOUS_CELLS_OUTPUTS = 2 # last_cell_output , second_last_cell_output
NUM_OF_NODES_IN_EACH_CELL = 4
MAX_NUM_OF_CONNECTIONS_PER_NODE = NUM_OF_NODES_IN_EACH_CELL
NUM_OF_CHANNELS = 16
INTERVAL_BETWEEN_REDUCTION_CELLS = 3
PREVIOUS_PREVIOUS = 2 # (n-2)
REDUCTION_STRIDE = 2
NORMAL_STRIDE = 1
TAU_GUMBEL = 0.5
EDGE_WEIGHTS_NETWORK_IN_SIZE = 5
EDGE_WEIGHTS_NETWORK_OUT_SIZE = 2
# https://pytorch.org/tutorials/beginner/blitz/cifar10_tutorial.html
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=BATCH_SIZE,
shuffle=True, num_workers=2)
valset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform)
valloader = torch.utils.data.DataLoader(valset, batch_size=BATCH_SIZE,
shuffle=False, num_workers=2)
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
TRAIN_BATCH_SIZE = int(len(trainset) * (1 - TEST_DATASET_RATIO))
# https://discordapp.com/channels/687504710118146232/703298739732873296/853270183649083433
# for training for edge weights as well as internal NN function weights
class Edge(nn.Module):
def __init__(self):
super(Edge, self).__init__()
# https://stackoverflow.com/a/51027227/8776167
# self.linear = nn.Linear(EDGE_WEIGHTS_NETWORK_IN_SIZE, EDGE_WEIGHTS_NETWORK_OUT_SIZE)
# https://pytorch.org/docs/stable/generated/torch.nn.parameter.Parameter.html
# for edge weights, not for internal NN function weights
if USE_CUDA:
self.weights = nn.Parameter(torch.zeros(1, device="cuda"))
else:
self.weights = nn.Parameter(torch.zeros(1))
def __freeze_w(self):
self.weights.requires_grad = False
def __unfreeze_w(self):
self.weights.requires_grad = True
def __freeze_f(self):
for param in self.f.parameters():
param.requires_grad = False
def __unfreeze_f(self):
for param in self.f.parameters():
param.requires_grad = True
# for NN functions internal weights training
def forward_f(self, x):
self.__unfreeze_f()
self.__freeze_w()
# inheritance in python classes and SOLID principles
# https://en.wikipedia.org/wiki/SOLID
# https://blog.cleancoder.com/uncle-bob/2020/10/18/Solid-Relevance.html
return self.f(x)
# self-defined initial NAS architecture, for supernet architecture edge weight training
def forward_edge(self, x):
self.__freeze_f()
self.__unfreeze_w()
return x * self.weights
class ConvEdge(Edge):
def __init__(self, stride):
super().__init__()
self.f = nn.Conv2d(in_channels=3, out_channels=3, kernel_size=(3, 3), stride=(stride, stride), padding=1)
class LinearEdge(Edge):
def __init__(self):
super().__init__()
self.f = nn.Linear(84, 10)
class MaxPoolEdge(Edge):
def __init__(self, stride):
super().__init__()
self.f = nn.MaxPool2d(kernel_size=3, stride=stride, padding=1, ceil_mode=True)
class AvgPoolEdge(Edge):
def __init__(self, stride):
super().__init__()
self.f = nn.AvgPool2d(kernel_size=3, stride=stride, padding=1, ceil_mode=True)
class Skip(nn.Module):
def forward(self, x):
return x
class SkipEdge(Edge):
def __init__(self):
super().__init__()
self.f = Skip()
# to collect and manage different edges between 2 nodes
class Connection(nn.Module):
def __init__(self, stride):
super(Connection, self).__init__()
if USE_CUDA:
# creates distinct edges and references each of them in a list (self.edges)
# self.linear_edge = LinearEdge().cuda()
self.conv2d_edge = ConvEdge(stride).cuda()
self.maxpool_edge = MaxPoolEdge(stride).cuda()
self.avgpool_edge = AvgPoolEdge(stride).cuda()
self.skip_edge = SkipEdge().cuda()
else:
# creates distinct edges and references each of them in a list (self.edges)
# self.linear_edge = LinearEdge()
self.conv2d_edge = ConvEdge(stride)
self.maxpool_edge = MaxPoolEdge(stride)
self.avgpool_edge = AvgPoolEdge(stride)
self.skip_edge = SkipEdge()
self.conv2d_edge = ConvEdge(stride).requires_grad_()
self.maxpool_edge = MaxPoolEdge(stride).requires_grad_()
self.avgpool_edge = AvgPoolEdge(stride).requires_grad_()
self.skip_edge = SkipEdge().requires_grad_()
# self.edges = [self.conv2d_edge, self.maxpool_edge, self.avgpool_edge, self.skip_edge]
# python list will break the computation graph, need to use nn.ModuleList as a differentiable python list
self.edges = nn.ModuleList([self.conv2d_edge, self.maxpool_edge, self.avgpool_edge, self.skip_edge])
self.edge_weights = torch.zeros(NUM_OF_MIXED_OPS, requires_grad=True)
# for approximate architecture gradient
self.f_weights = torch.zeros(NUM_OF_MIXED_OPS, requires_grad=True)
self.f_weights_backup = torch.zeros(NUM_OF_MIXED_OPS, requires_grad=True)
self.weight_plus = torch.zeros(NUM_OF_MIXED_OPS, requires_grad=True)
self.weight_minus = torch.zeros(NUM_OF_MIXED_OPS, requires_grad=True)
# use linear transformation (weighted summation) to combine results from different edges
self.combined_feature_map = torch.zeros([BATCH_SIZE, NUM_OF_IMAGE_CHANNELS, IMAGE_HEIGHT, IMAGE_WIDTH])
if USE_CUDA:
self.combined_feature_map = self.combined_feature_map.cuda()
self.combined_feature_map.requires_grad_()
for e in range(NUM_OF_MIXED_OPS):
with torch.no_grad():
self.edge_weights[e] = self.edges[e].weights
# https://stackoverflow.com/a/45024500/8776167 extracts the weights learned through NN functions
# self.f_weights[e] = list(self.edges[e].parameters())
# Refer to GDAS equations (5) and (6)
# if one_hot is already there, would summation be required given that all other entries are forced to 0 ?
# It's not required, but you don't know, which index is one hot encoded 1.
# https://pytorch.org/docs/stable/nn.functional.html#gumbel-softmax
# See also https://github.com/D-X-Y/AutoDL-Projects/issues/10#issuecomment-916619163
gumbel = F.gumbel_softmax(self.edge_weights, tau=TAU_GUMBEL, hard=True)
self.chosen_edge = torch.argmax(gumbel, dim=0) # converts one-hot encoding into integer
# to collect and manage multiple different connections between a particular node and its neighbouring nodes
class Node(nn.Module):
def __init__(self, stride):
super(Node, self).__init__()
# two types of output connections
# Type 1: (multiple edges) output connects to the input of the other intermediate nodes
# Type 2: (single edge) output connects directly to the final output node
# Type 1
self.connections = nn.ModuleList([Connection(stride) for i in range(MAX_NUM_OF_CONNECTIONS_PER_NODE)])
# Type 2
# depends on PREVIOUS node's Type 1 output
self.output = torch.zeros([BATCH_SIZE, NUM_OF_IMAGE_CHANNELS, IMAGE_HEIGHT, IMAGE_WIDTH]) # for initialization
if USE_CUDA:
self.output = self.output.cuda()
self.output = self.output.requires_grad_()
# to manage all nodes within a cell
class Cell(nn.Module):
def __init__(self, stride):
super(Cell, self).__init__()
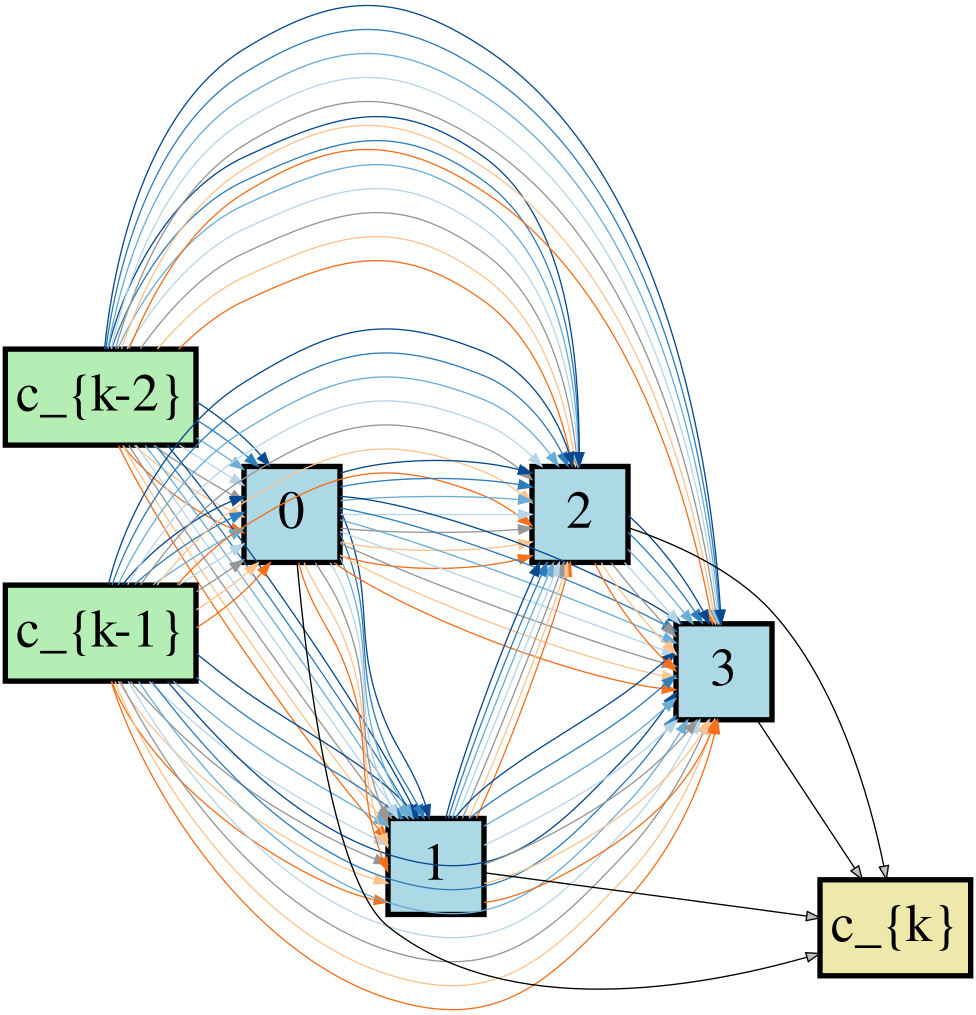
# all the coloured edges inside
# https://user-images.githubusercontent.com/3324659/117573177-20ea9a80-b109-11eb-9418-16e22e684164.png
# A single cell contains 'NUM_OF_NODES_IN_EACH_CELL' distinct nodes
# for the k-th node, we have (k+1) preceding nodes.
# Each intermediate state, 0->3 ('NUM_OF_NODES_IN_EACH_CELL-1'),
# is connected to each previous intermediate state
# as well as the output of the previous two cells, c_{k-2} and c_{k-1} (after a preprocessing layer).
# previous_previous_cell_output = c_{k-2}
# previous_cell_output = c{k-1}
self.nodes = nn.ModuleList([Node(stride) for i in range(NUM_OF_NODES_IN_EACH_CELL)])
# just for variables initialization
self.previous_cell = 0
self.previous_previous_cell = 0
self.output = torch.zeros([BATCH_SIZE, NUM_OF_IMAGE_CHANNELS, IMAGE_HEIGHT, IMAGE_WIDTH])
if USE_CUDA:
self.output = self.output.cuda()
self.output = self.output.requires_grad_()
for n in range(NUM_OF_NODES_IN_EACH_CELL):
# 'add' then 'concat' feature maps from different nodes
# needs to take care of tensor dimension mismatch
# See https://github.com/D-X-Y/AutoDL-Projects/issues/99#issuecomment-869100416
self.output = self.output + self.nodes[n].output
# to manage all nodes
class Graph(nn.Module):
def __init__(self):
super(Graph, self).__init__()
stride = 0 # just to initialize a variable
for i in range(NUM_OF_CELLS):
if i % INTERVAL_BETWEEN_REDUCTION_CELLS == 0:
stride = REDUCTION_STRIDE # to emulate reduction cell by using normal cell with stride=2
else:
stride = NORMAL_STRIDE # normal cell
self.cells = nn.ModuleList([Cell(stride) for i in range(NUM_OF_CELLS)])
total_grad_out = []
total_grad_in = []
def hook_fn_backward (module, grad_input, grad_output):
print (module) # for distinguishing module
# In order to comply with the order back-propagation, let's print grad_output
print ( 'grad_output', grad_output)
# Reprint grad_input
print ( 'grad_input', grad_input)
# Save to global variables
total_grad_in.append (grad_input)
total_grad_out.append (grad_output)
# https://translate.google.com/translate?sl=auto&tl=en&u=http://khanrc.github.io/nas-4-darts-tutorial.html
def train_NN(forward_pass_only):
print("Entering train_NN(), forward_pass_only = ", forward_pass_only)
graph = Graph()
if USE_CUDA:
graph = graph.cuda()
modules = graph.named_children()
print("modules = " , modules)
for name, module in graph.named_modules():
module.register_full_backward_hook(hook_fn_backward)
criterion = nn.CrossEntropyLoss()
# criterion = nn.BCELoss()
optimizer1 = optim.SGD(graph.parameters(), lr=LEARNING_RATE, momentum=MOMENTUM)
# just for initialization, no special meaning
Ltrain = 0
train_inputs = 0
train_labels = 0
if forward_pass_only == 0:
# do train thing for architecture edge weights
graph.train()
# zero the parameter gradients
optimizer1.zero_grad()
print("before multiple for-loops")
for train_data, val_data in (zip(trainloader, valloader)):
train_inputs, train_labels = train_data
# val_inputs, val_labels = val_data
if USE_CUDA:
train_inputs = train_inputs.cuda()
train_labels = train_labels.cuda()
for epoch in range(NUM_EPOCHS):
# forward pass
for c in range(NUM_OF_CELLS):
for n in range(NUM_OF_NODES_IN_EACH_CELL):
# not all nodes have same number of Type-1 output connection
for cc in range(MAX_NUM_OF_CONNECTIONS_PER_NODE - n - 1):
for e in range(NUM_OF_MIXED_OPS):
if c == 0:
x = train_inputs
if USE_CUDA:
x = x.cuda()
else:
if n == 0:
# Uses feature map output from previous neighbour cell for further processing
x = graph.cells[c-1].nodes[NUM_OF_NODES_IN_EACH_CELL-1].connections[cc].combined_feature_map
else:
# Uses feature map output from previous neighbour node for further processing
x = graph.cells[c].nodes[n-1].connections[cc].combined_feature_map
# combines all the feature maps from different mixed ops edges
graph.cells[c].nodes[n].connections[cc].combined_feature_map = \
graph.cells[c].nodes[n].connections[cc].combined_feature_map + \
graph.cells[c].nodes[n].connections[cc].edges[e].forward_f(x) # Ltrain(w±, alpha)
print("graph.cells[", c, "].nodes[", n, "].connections[", cc, "].combined_feature_map.grad_fn = ",
graph.cells[c].nodes[n].connections[cc].combined_feature_map.grad_fn)
print("graph.cells[", c, "].nodes[", n, "].connections[", cc, "].edge_weights[", e, "].grad_fn = ",
graph.cells[c].nodes[n].connections[cc].edge_weights[e].grad_fn)
print("graph.cells[", c, "].output.grad_fn = ",
graph.cells[c].output.grad_fn)
# https://www.reddit.com/r/learnpython/comments/no7btk/how_to_carry_extra_information_across_dag/
# https://docs.python.org/3/tutorial/datastructures.html
# generates a supernet consisting of 'NUM_OF_CELLS' cells
# each cell contains of 'NUM_OF_NODES_IN_EACH_CELL' nodes
# refer to PNASNet https://arxiv.org/pdf/1712.00559.pdf#page=5 for the cell arrangement
# https://pytorch.org/tutorials/beginner/examples_autograd/two_layer_net_custom_function.html
# encodes the cells and nodes arrangement in the multigraph
if c > 1: # for previous_previous_cell, (c-2)
graph.cells[c].previous_cell = graph.cells[c - 1].output
graph.cells[c].previous_previous_cell = graph.cells[c - PREVIOUS_PREVIOUS].output
if n == 0:
if c <= 1:
graph.cells[c].nodes[n].output = graph.cells[c].nodes[n].connections[cc].combined_feature_map
else: # there is no input from previous cells for the first two cells
# needs to take care tensor dimension mismatch from multiple edges connections
graph.cells[c].nodes[n].output = \
graph.cells[c].nodes[n].output + \
graph.cells[c-1].nodes[NUM_OF_NODES_IN_EACH_CELL-1].connections[cc].combined_feature_map + \
graph.cells[c-PREVIOUS_PREVIOUS].nodes[NUM_OF_NODES_IN_EACH_CELL-1].connections[cc].combined_feature_map
else: # n > 0
# depends on PREVIOUS node's Type 1 connection
# needs to take care tensor dimension mismatch from multiple edges connections
print("graph.cells[", c ,"].nodes[" ,n, "].output.size() = ",
graph.cells[c].nodes[n].output.size())
print("graph.cells[", c, "].nodes[", n-1, "].connections[", cc, "].combined_feature_map.size() = ",
graph.cells[c].nodes[n-1].connections[cc].combined_feature_map.size())
graph.cells[c].nodes[n].output = \
graph.cells[c].nodes[n].output + \
graph.cells[c].nodes[n-1].connections[cc].combined_feature_map + \
graph.cells[c - 1].nodes[NUM_OF_NODES_IN_EACH_CELL - 1].connections[cc].combined_feature_map + \
graph.cells[c - PREVIOUS_PREVIOUS].nodes[NUM_OF_NODES_IN_EACH_CELL - 1].connections[cc].combined_feature_map
print("graph.cells[", c, "].nodes[", n, "].output.grad_fn = ",
graph.cells[c].nodes[n].output.grad_fn)
# 'add' then 'concat' feature maps from different nodes
# needs to take care of tensor dimension mismatch
# See https://github.com/D-X-Y/AutoDL-Projects/issues/99#issuecomment-869100416
graph.cells[c].output += graph.cells[c].nodes[n].output
print("graph.cells[", c, "].output.grad_fn = ",
graph.cells[c].output.grad_fn)
output_tensor = graph.cells[NUM_OF_CELLS-1].output
output_tensor = output_tensor.view(output_tensor.shape[0], -1)
if USE_CUDA:
output_tensor = output_tensor.cuda()
if USE_CUDA:
m_linear = nn.Linear(NUM_OF_IMAGE_CHANNELS * IMAGE_HEIGHT * IMAGE_WIDTH, NUM_OF_IMAGE_CLASSES).cuda()
else:
m_linear = nn.Linear(NUM_OF_IMAGE_CHANNELS * IMAGE_HEIGHT * IMAGE_WIDTH, NUM_OF_IMAGE_CLASSES)
outputs1 = m_linear(output_tensor)
if USE_CUDA:
outputs1 = outputs1.cuda()
print("outputs1.size() = ", outputs1.size())
print("train_labels.size() = ", train_labels.size())
Ltrain = criterion(outputs1, train_labels)
if forward_pass_only == 0:
# backward pass
Ltrain = Ltrain.requires_grad_()
Ltrain.retain_grad()
Ltrain.register_hook(lambda x: print(x))
Ltrain.backward()
# for c in range(NUM_OF_CELLS):
# for n in range(NUM_OF_NODES_IN_EACH_CELL):
# # not all nodes have same number of Type-1 output connection
# for cc in range(MAX_NUM_OF_CONNECTIONS_PER_NODE - n - 1):
# for e in range(NUM_OF_MIXED_OPS):
# if e == 0: # graph.cells[c].nodes[n].connections[cc].edges[e] == conv2d_edge:
# print("graph.cells[", c, "].nodes[", n, "].connections[", cc, "].edges[", e, "].f.weight.grad_fn = ",
# graph.cells[c].nodes[n].connections[cc].edges[e].f.weight.grad_fn)
print("starts to print graph.named_parameters()")
for name, param in graph.named_parameters():
print(name, param.grad)
print("finished printing graph.named_parameters()")
optimizer1.step()
else:
# no need to save model parameters for next epoch
return Ltrain
# DARTS's approximate architecture gradient. Refer to equation (8)
# needs to save intermediate trained model for Ltrain
path = './model.pth'
torch.save(graph, path)
print("after multiple for-loops")
return Ltrain
def train_architecture(forward_pass_only, train_or_val='val'):
print("Entering train_architecture(), forward_pass_only = ", forward_pass_only, " , train_or_val = ", train_or_val)
graph = Graph()
if USE_CUDA:
graph = graph.cuda()
criterion = nn.CrossEntropyLoss()
optimizer2 = optim.SGD(graph.parameters(), lr=LEARNING_RATE, momentum=MOMENTUM)
# just for initialization, no special meaning
Lval = 0
train_inputs = 0
train_labels = 0
val_inputs = 0
val_labels = 0
if forward_pass_only == 0:
# do train thing for internal NN function weights
graph.train()
# zero the parameter gradients
optimizer2.zero_grad()
print("before multiple for-loops")
for train_data, val_data in (zip(trainloader, valloader)):
train_inputs, train_labels = train_data
val_inputs, val_labels = val_data
if USE_CUDA:
train_inputs = train_inputs.cuda()
train_labels = train_labels.cuda()
val_inputs = val_inputs.cuda()
val_labels = val_labels.cuda()
for epoch in range(NUM_EPOCHS):
# forward pass
# use linear transformation ('weighted sum then concat') to combine results from different nodes
# into an output feature map to be fed into the next neighbour node for further processing
for c in range(NUM_OF_CELLS):
for n in range(NUM_OF_NODES_IN_EACH_CELL):
# not all nodes have same number of Type-1 output connection
for cc in range(MAX_NUM_OF_CONNECTIONS_PER_NODE - n - 1):
for e in range(NUM_OF_MIXED_OPS):
x = 0 # depends on the input tensor dimension requirement
if c == 0:
if train_or_val == 'val':
x = val_inputs
else:
x = train_inputs
else:
# Uses feature map output from previous neighbour node for further processing
x = graph.cells[c].nodes[n-1].connections[cc].combined_feature_map
# need to take care of tensors dimension mismatch
graph.cells[c].nodes[n].connections[cc].combined_feature_map = \
graph.cells[c].nodes[n].connections[cc].combined_feature_map + \
graph.cells[c].nodes[n].connections[cc].edges[e].forward_edge(x) # Lval(w*, alpha)
output2_tensor = graph.cells[NUM_OF_CELLS-1].output
output2_tensor = output2_tensor.view(output2_tensor.shape[0], -1)
if USE_CUDA:
output2_tensor = output2_tensor.cuda()
if USE_CUDA:
m_linear = nn.Linear(NUM_OF_IMAGE_CHANNELS * IMAGE_HEIGHT * IMAGE_WIDTH, NUM_OF_IMAGE_CLASSES).cuda()
else:
m_linear = nn.Linear(NUM_OF_IMAGE_CHANNELS * IMAGE_HEIGHT * IMAGE_WIDTH, NUM_OF_IMAGE_CLASSES)
outputs2 = m_linear(output2_tensor)
if USE_CUDA:
outputs2 = outputs2.cuda()
print("outputs2.size() = ", outputs2.size())
print("val_labels.size() = ", val_labels.size())
print("train_labels.size() = ", train_labels.size())
if train_or_val == 'val':
loss = criterion(outputs2, val_labels)
else:
loss = criterion(outputs2, train_labels)
if forward_pass_only == 0:
# backward pass
Lval = loss
Lval = Lval.requires_grad_()
Lval.backward()
for name, param in graph.named_parameters():
print(name, param.grad)
optimizer2.step()
else:
# no need to save model parameters for next epoch
return loss
# needs to save intermediate trained model for Lval
path = './model.pth'
torch.save(graph, path)
# DARTS's approximate architecture gradient. Refer to equation (8) and https://i.imgur.com/81JFaWc.png
sigma = LEARNING_RATE
epsilon = 0.01 / torch.norm(Lval)
for c in range(NUM_OF_CELLS):
for n in range(NUM_OF_NODES_IN_EACH_CELL):
# not all nodes have same number of Type-1 output connection
for cc in range(MAX_NUM_OF_CONNECTIONS_PER_NODE - n - 1):
CC = graph.cells[c].nodes[n].connections[cc]
for e in range(NUM_OF_MIXED_OPS):
for w in graph.cells[c].nodes[n].connections[cc].edges[e].f.parameters():
# https://mythrex.github.io/math_behind_darts/
# Finite Difference Method
CC.weight_plus = w + epsilon * Lval
CC.weight_minus = w - epsilon * Lval
# Backups original f_weights
CC.f_weights_backup = w
# replaces f_weights with weight_plus before NN training
for c in range(NUM_OF_CELLS):
for n in range(NUM_OF_NODES_IN_EACH_CELL):
# not all nodes have same number of Type-1 output connection
for cc in range(MAX_NUM_OF_CONNECTIONS_PER_NODE - n - 1):
CC = graph.cells[c].nodes[n].connections[cc]
for e in range(NUM_OF_MIXED_OPS):
for w in graph.cells[c].nodes[n].connections[cc].edges[e].f.parameters():
w = CC.weight_plus
# test NN to obtain loss
Ltrain_plus = train_architecture(forward_pass_only=1, train_or_val='train')
# replaces f_weights with weight_minus before NN training
for c in range(NUM_OF_CELLS):
for n in range(NUM_OF_NODES_IN_EACH_CELL):
# not all nodes have same number of Type-1 output connection
for cc in range(MAX_NUM_OF_CONNECTIONS_PER_NODE - n - 1):
CC = graph.cells[c].nodes[n].connections[cc]
for e in range(NUM_OF_MIXED_OPS):
for w in graph.cells[c].nodes[n].connections[cc].edges[e].f.parameters():
w = CC.weight_minus
# test NN to obtain loss
Ltrain_minus = train_architecture(forward_pass_only=1, train_or_val='train')
# Restores original f_weights
for c in range(NUM_OF_CELLS):
for n in range(NUM_OF_NODES_IN_EACH_CELL):
# not all nodes have same number of Type-1 output connection
for cc in range(MAX_NUM_OF_CONNECTIONS_PER_NODE - n - 1):
CC = graph.cells[c].nodes[n].connections[cc]
for e in range(NUM_OF_MIXED_OPS):
for w in graph.cells[c].nodes[n].connections[cc].edges[e].f.parameters():
w = CC.f_weights_backup
print("after multiple for-loops")
L2train_Lval = (Ltrain_plus - Ltrain_minus) / (2 * epsilon)
return Lval - L2train_Lval
if __name__ == "__main__":
run_num = 0
not_converged = 1
while not_converged:
print("run_num = ", run_num)
ltrain = train_NN(forward_pass_only=0)
print("Finished train_NN()")
# 'train_or_val' to differentiate between using training dataset and validation dataset
lval = train_architecture(forward_pass_only=0, train_or_val='val')
print("Finished train_architecture()")
print("lval = ", lval, " , ltrain = ", ltrain)
not_converged = (lval > 0.01) or (ltrain > 0.01)
run_num = run_num + 1
# do test thing
 ,
,