I have checked all the above suggestions, but the grad_fn = None issue still persists.
Why ?
I have checked all the above suggestions, but the grad_fn = None issue still persists.
Why ?
@ptrblck is there some pytorch visualization tool that I could use to debug my current situation with grad_fn = None ?
I don’t know if there are currently supported tools to visualize the backward graph of a model, so using forward hooks and checking the grad_fn of each output might be the way to go.
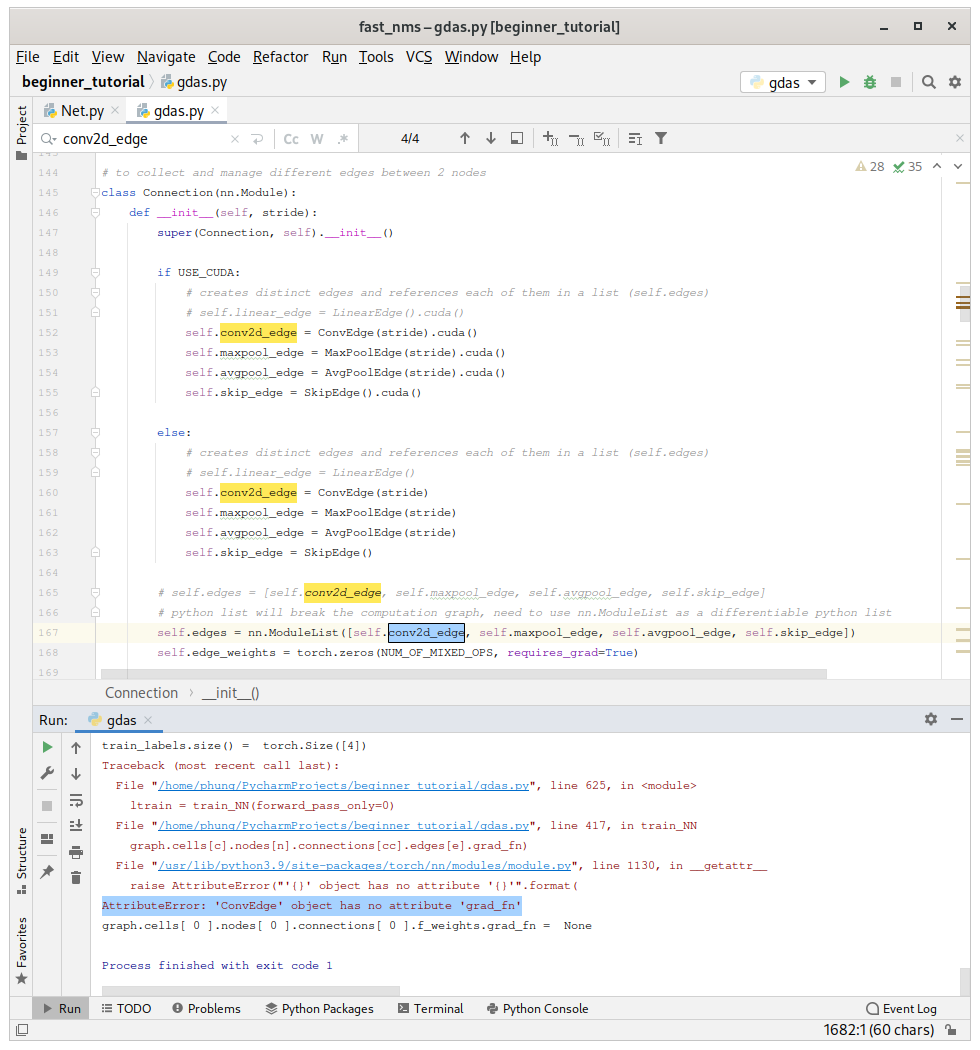
I have already checked graph.cells[c].nodes[n].output.grad_fn as well as graph.cells[c].output.grad_fn, what else am I missing in the computation graph ?
why AttributeError: 'ConvEdge object has no attribute 'grad_fn' ?
self.edges = nn.ModuleList([self.conv2d_edge, self.maxpool_edge, self.avgpool_edge, self.skip_edge])
I don’t know, as I’m not familiar with your use case. I’ve posted debugging steps before, i.e. to check that the needed parameters are used, have a valid .grad_fn, and after the backward() operation also get valid gradients. Based on your updates it still seems that you are either detaching tensors from the computation graph or are not using parameters while assuming they are used.
.grad_fn is an attribute of tensors/parameters, so I guess ConvEdge might be an nn.Module.
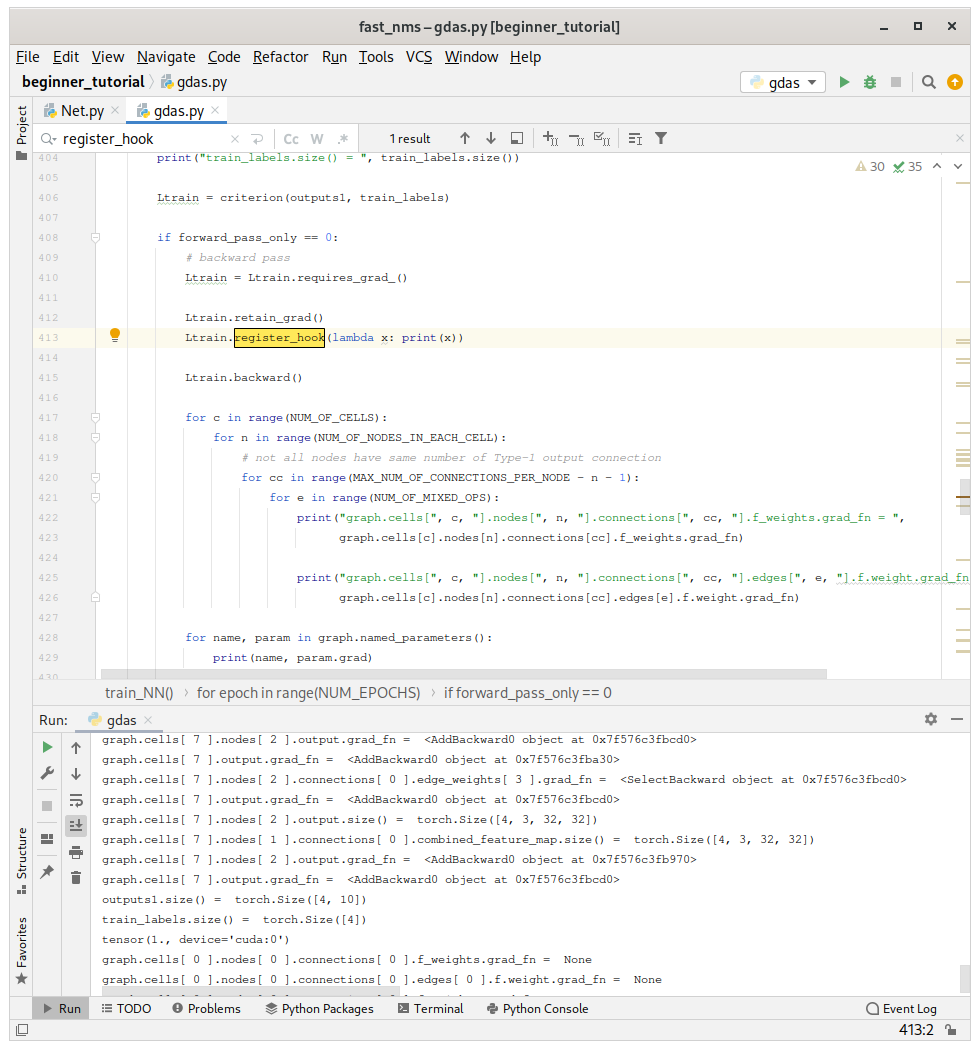
why the hook function on line 413 does not perform its job ?
# https://github.com/D-X-Y/AutoDL-Projects/issues/99
import torch
import torch.utils.data
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
# import numpy as np
torch.autograd.set_detect_anomaly(True)
USE_CUDA = torch.cuda.is_available()
# https://arxiv.org/pdf/1806.09055.pdf#page=12
TEST_DATASET_RATIO = 0.5 # 50 percent of the dataset is dedicated for testing purpose
BATCH_SIZE = 4
NUM_OF_IMAGE_CHANNELS = 3 # RGB
IMAGE_HEIGHT = 32
IMAGE_WIDTH = 32
NUM_OF_IMAGE_CLASSES = 10
SIZE_OF_HIDDEN_LAYERS = 64
NUM_EPOCHS = 1
LEARNING_RATE = 0.025
MOMENTUM = 0.9
NUM_OF_CELLS = 8
NUM_OF_MIXED_OPS = 4
NUM_OF_PREVIOUS_CELLS_OUTPUTS = 2 # last_cell_output , second_last_cell_output
NUM_OF_NODES_IN_EACH_CELL = 4
MAX_NUM_OF_CONNECTIONS_PER_NODE = NUM_OF_NODES_IN_EACH_CELL
NUM_OF_CHANNELS = 16
INTERVAL_BETWEEN_REDUCTION_CELLS = 3
PREVIOUS_PREVIOUS = 2 # (n-2)
REDUCTION_STRIDE = 2
NORMAL_STRIDE = 1
TAU_GUMBEL = 0.5
EDGE_WEIGHTS_NETWORK_IN_SIZE = 5
EDGE_WEIGHTS_NETWORK_OUT_SIZE = 2
# https://pytorch.org/tutorials/beginner/blitz/cifar10_tutorial.html
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=BATCH_SIZE,
shuffle=True, num_workers=2)
valset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform)
valloader = torch.utils.data.DataLoader(valset, batch_size=BATCH_SIZE,
shuffle=False, num_workers=2)
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
TRAIN_BATCH_SIZE = int(len(trainset) * (1 - TEST_DATASET_RATIO))
# https://discordapp.com/channels/687504710118146232/703298739732873296/853270183649083433
# for training for edge weights as well as internal NN function weights
class Edge(nn.Module):
def __init__(self):
super(Edge, self).__init__()
# https://stackoverflow.com/a/51027227/8776167
# self.linear = nn.Linear(EDGE_WEIGHTS_NETWORK_IN_SIZE, EDGE_WEIGHTS_NETWORK_OUT_SIZE)
# https://pytorch.org/docs/stable/generated/torch.nn.parameter.Parameter.html
self.weights = nn.Parameter(torch.zeros(1),
requires_grad=True) # for edge weights, not for internal NN function weights
def __freeze_w(self):
self.weights.requires_grad = False
def __unfreeze_w(self):
self.weights.requires_grad = True
def __freeze_f(self):
for param in self.f.parameters():
param.requires_grad = False
def __unfreeze_f(self):
for param in self.f.parameters():
param.requires_grad = True
# for NN functions internal weights training
def forward_f(self, x):
self.__unfreeze_f()
self.__freeze_w()
# inheritance in python classes and SOLID principles
# https://en.wikipedia.org/wiki/SOLID
# https://blog.cleancoder.com/uncle-bob/2020/10/18/Solid-Relevance.html
return self.f(x)
# self-defined initial NAS architecture, for supernet architecture edge weight training
def forward_edge(self, x):
self.__freeze_f()
self.__unfreeze_w()
return x * self.weights
class ConvEdge(Edge):
def __init__(self, stride):
super().__init__()
self.f = nn.Conv2d(in_channels=3, out_channels=3, kernel_size=(3, 3), stride=(stride, stride), padding=1)
class LinearEdge(Edge):
def __init__(self):
super().__init__()
self.f = nn.Linear(84, 10)
class MaxPoolEdge(Edge):
def __init__(self, stride):
super().__init__()
self.f = nn.MaxPool2d(kernel_size=3, stride=stride, padding=1, ceil_mode=True)
class AvgPoolEdge(Edge):
def __init__(self, stride):
super().__init__()
self.f = nn.AvgPool2d(kernel_size=3, stride=stride, padding=1, ceil_mode=True)
class Skip(nn.Module):
def forward(self, x):
return x
class SkipEdge(Edge):
def __init__(self):
super().__init__()
self.f = Skip()
# to collect and manage different edges between 2 nodes
class Connection(nn.Module):
def __init__(self, stride):
super(Connection, self).__init__()
if USE_CUDA:
# creates distinct edges and references each of them in a list (self.edges)
# self.linear_edge = LinearEdge().cuda()
self.conv2d_edge = ConvEdge(stride).cuda()
self.maxpool_edge = MaxPoolEdge(stride).cuda()
self.avgpool_edge = AvgPoolEdge(stride).cuda()
self.skip_edge = SkipEdge().cuda()
else:
# creates distinct edges and references each of them in a list (self.edges)
# self.linear_edge = LinearEdge()
self.conv2d_edge = ConvEdge(stride)
self.maxpool_edge = MaxPoolEdge(stride)
self.avgpool_edge = AvgPoolEdge(stride)
self.skip_edge = SkipEdge()
# self.edges = [self.conv2d_edge, self.maxpool_edge, self.avgpool_edge, self.skip_edge]
# python list will break the computation graph, need to use nn.ModuleList as a differentiable python list
self.edges = nn.ModuleList([self.conv2d_edge, self.maxpool_edge, self.avgpool_edge, self.skip_edge])
self.edge_weights = torch.zeros(NUM_OF_MIXED_OPS, requires_grad=True)
# for approximate architecture gradient
self.f_weights = torch.zeros(NUM_OF_MIXED_OPS, requires_grad=True)
self.f_weights_backup = torch.zeros(NUM_OF_MIXED_OPS, requires_grad=True)
self.weight_plus = torch.zeros(NUM_OF_MIXED_OPS, requires_grad=True)
self.weight_minus = torch.zeros(NUM_OF_MIXED_OPS, requires_grad=True)
# use linear transformation (weighted summation) to combine results from different edges
self.combined_feature_map = torch.zeros([BATCH_SIZE, NUM_OF_IMAGE_CHANNELS, IMAGE_HEIGHT, IMAGE_WIDTH],
requires_grad=True)
if USE_CUDA:
self.combined_feature_map = self.combined_feature_map.cuda()
for e in range(NUM_OF_MIXED_OPS):
with torch.no_grad():
self.edge_weights[e] = self.edges[e].weights
# https://stackoverflow.com/a/45024500/8776167 extracts the weights learned through NN functions
# self.f_weights[e] = list(self.edges[e].parameters())
# Refer to GDAS equations (5) and (6)
# if one_hot is already there, would summation be required given that all other entries are forced to 0 ?
# It's not required, but you don't know, which index is one hot encoded 1.
# https://pytorch.org/docs/stable/nn.functional.html#gumbel-softmax
gumbel = F.gumbel_softmax(self.edge_weights, tau=TAU_GUMBEL, hard=True)
self.chosen_edge = torch.argmax(gumbel, dim=0) # converts one-hot encoding into integer
# to collect and manage multiple different connections between a particular node and its neighbouring nodes
class Node(nn.Module):
def __init__(self, stride):
super(Node, self).__init__()
# two types of output connections
# Type 1: (multiple edges) output connects to the input of the other intermediate nodes
# Type 2: (single edge) output connects directly to the final output node
# Type 1
self.connections = nn.ModuleList([Connection(stride) for i in range(MAX_NUM_OF_CONNECTIONS_PER_NODE)])
# Type 2
# depends on PREVIOUS node's Type 1 output
self.output = torch.zeros([BATCH_SIZE, NUM_OF_IMAGE_CHANNELS, IMAGE_HEIGHT, IMAGE_WIDTH],
requires_grad=True) # for initialization
if USE_CUDA:
self.output = self.output.cuda()
# to manage all nodes within a cell
class Cell(nn.Module):
def __init__(self, stride):
super(Cell, self).__init__()
# all the coloured edges inside
# https://user-images.githubusercontent.com/3324659/117573177-20ea9a80-b109-11eb-9418-16e22e684164.png
# A single cell contains 'NUM_OF_NODES_IN_EACH_CELL' distinct nodes
# for the k-th node, we have (k+1) preceding nodes.
# Each intermediate state, 0->3 ('NUM_OF_NODES_IN_EACH_CELL-1'),
# is connected to each previous intermediate state
# as well as the output of the previous two cells, c_{k-2} and c_{k-1} (after a preprocessing layer).
# previous_previous_cell_output = c_{k-2}
# previous_cell_output = c{k-1}
self.nodes = nn.ModuleList([Node(stride) for i in range(NUM_OF_NODES_IN_EACH_CELL)])
# just for variables initialization
self.previous_cell = 0
self.previous_previous_cell = 0
self.output = torch.zeros([BATCH_SIZE, NUM_OF_IMAGE_CHANNELS, IMAGE_HEIGHT, IMAGE_WIDTH],
requires_grad=True)
if USE_CUDA:
self.output = self.output.cuda()
for n in range(NUM_OF_NODES_IN_EACH_CELL):
# 'add' then 'concat' feature maps from different nodes
# needs to take care of tensor dimension mismatch
# See https://github.com/D-X-Y/AutoDL-Projects/issues/99#issuecomment-869100416
self.output = self.output + self.nodes[n].output
# to manage all nodes
class Graph(nn.Module):
def __init__(self):
super(Graph, self).__init__()
stride = 0 # just to initialize a variable
for i in range(NUM_OF_CELLS):
if i % INTERVAL_BETWEEN_REDUCTION_CELLS == 0:
stride = REDUCTION_STRIDE # to emulate reduction cell by using normal cell with stride=2
else:
stride = NORMAL_STRIDE # normal cell
self.cells = nn.ModuleList([Cell(stride) for i in range(NUM_OF_CELLS)])
# https://translate.google.com/translate?sl=auto&tl=en&u=http://khanrc.github.io/nas-4-darts-tutorial.html
def train_NN(forward_pass_only):
print("Entering train_NN(), forward_pass_only = ", forward_pass_only)
graph = Graph()
if USE_CUDA:
graph = graph.cuda()
criterion = nn.CrossEntropyLoss()
# criterion = nn.BCELoss()
optimizer1 = optim.SGD(graph.parameters(), lr=LEARNING_RATE, momentum=MOMENTUM)
# just for initialization, no special meaning
Ltrain = 0
train_inputs = 0
train_labels = 0
if forward_pass_only == 0:
# do train thing for architecture edge weights
graph.train()
# zero the parameter gradients
optimizer1.zero_grad()
print("before multiple for-loops")
for train_data, val_data in (zip(trainloader, valloader)):
train_inputs, train_labels = train_data
# val_inputs, val_labels = val_data
if USE_CUDA:
train_inputs = train_inputs.cuda()
train_labels = train_labels.cuda()
for epoch in range(NUM_EPOCHS):
# forward pass
for c in range(NUM_OF_CELLS):
for n in range(NUM_OF_NODES_IN_EACH_CELL):
# not all nodes have same number of Type-1 output connection
for cc in range(MAX_NUM_OF_CONNECTIONS_PER_NODE - n - 1):
for e in range(NUM_OF_MIXED_OPS):
if c == 0:
x = train_inputs
else:
if n == 0:
# Uses feature map output from previous neighbour cell for further processing
x = graph.cells[c-1].nodes[NUM_OF_NODES_IN_EACH_CELL-1].connections[cc].combined_feature_map
else:
# Uses feature map output from previous neighbour node for further processing
x = graph.cells[c].nodes[n-1].connections[cc].combined_feature_map
if USE_CUDA:
x = x.cuda()
# combines all the feature maps from different mixed ops edges
graph.cells[c].nodes[n].connections[cc].combined_feature_map = \
graph.cells[c].nodes[n].connections[cc].combined_feature_map + \
graph.cells[c].nodes[n].connections[cc].edges[e].forward_f(x) # Ltrain(w±, alpha)
print("graph.cells[", c, "].nodes[", n, "].connections[", cc, "].edge_weights[", e, "].grad_fn = ",
graph.cells[c].nodes[n].connections[cc].edge_weights[e].grad_fn)
print("graph.cells[", c, "].output.grad_fn = ",
graph.cells[c].output.grad_fn)
# https://www.reddit.com/r/learnpython/comments/no7btk/how_to_carry_extra_information_across_dag/
# https://docs.python.org/3/tutorial/datastructures.html
# generates a supernet consisting of 'NUM_OF_CELLS' cells
# each cell contains of 'NUM_OF_NODES_IN_EACH_CELL' nodes
# refer to PNASNet https://arxiv.org/pdf/1712.00559.pdf#page=5 for the cell arrangement
# https://pytorch.org/tutorials/beginner/examples_autograd/two_layer_net_custom_function.html
# encodes the cells and nodes arrangement in the multigraph
if c > 1: # for previous_previous_cell, (c-2)
graph.cells[c].previous_cell = graph.cells[c - 1].output
graph.cells[c].previous_previous_cell = graph.cells[c - PREVIOUS_PREVIOUS].output
if n == 0:
if c <= 1:
graph.cells[c].nodes[n].output = graph.cells[c].nodes[n].connections[cc].combined_feature_map
else: # there is no input from previous cells for the first two cells
# needs to take care tensor dimension mismatch from multiple edges connections
graph.cells[c].nodes[n].output += \
graph.cells[c-1].nodes[NUM_OF_NODES_IN_EACH_CELL-1].connections[cc].combined_feature_map + \
graph.cells[c-PREVIOUS_PREVIOUS].nodes[NUM_OF_NODES_IN_EACH_CELL-1].connections[cc].combined_feature_map
else: # n > 0
# depends on PREVIOUS node's Type 1 connection
# needs to take care tensor dimension mismatch from multiple edges connections
print("graph.cells[", c ,"].nodes[" ,n, "].output.size() = ",
graph.cells[c].nodes[n].output.size())
print("graph.cells[", c, "].nodes[", n-1, "].connections[", cc, "].combined_feature_map.size() = ",
graph.cells[c].nodes[n-1].connections[cc].combined_feature_map.size())
graph.cells[c].nodes[n].output += \
graph.cells[c].nodes[n-1].connections[cc].combined_feature_map + \
graph.cells[c - 1].nodes[NUM_OF_NODES_IN_EACH_CELL - 1].connections[cc].combined_feature_map + \
graph.cells[c - PREVIOUS_PREVIOUS].nodes[NUM_OF_NODES_IN_EACH_CELL - 1].connections[cc].combined_feature_map
print("graph.cells[", c, "].nodes[", n, "].output.grad_fn = ",
graph.cells[c].nodes[n].output.grad_fn)
# 'add' then 'concat' feature maps from different nodes
# needs to take care of tensor dimension mismatch
# See https://github.com/D-X-Y/AutoDL-Projects/issues/99#issuecomment-869100416
graph.cells[c].output += graph.cells[c].nodes[n].output
print("graph.cells[", c, "].output.grad_fn = ",
graph.cells[c].output.grad_fn)
output_tensor = graph.cells[NUM_OF_CELLS-1].output
output_tensor = output_tensor.view(output_tensor.shape[0], -1)
if USE_CUDA:
output_tensor = output_tensor.cuda()
if USE_CUDA:
m_linear = nn.Linear(NUM_OF_IMAGE_CHANNELS * IMAGE_HEIGHT * IMAGE_WIDTH, NUM_OF_IMAGE_CLASSES).cuda()
else:
m_linear = nn.Linear(NUM_OF_IMAGE_CHANNELS * IMAGE_HEIGHT * IMAGE_WIDTH, NUM_OF_IMAGE_CLASSES)
outputs1 = m_linear(output_tensor)
if USE_CUDA:
outputs1 = outputs1.cuda()
print("outputs1.size() = ", outputs1.size())
print("train_labels.size() = ", train_labels.size())
Ltrain = criterion(outputs1, train_labels)
if forward_pass_only == 0:
# backward pass
Ltrain = Ltrain.requires_grad_()
Ltrain.retain_grad()
Ltrain.register_hook(lambda x: print(x))
Ltrain.backward()
for c in range(NUM_OF_CELLS):
for n in range(NUM_OF_NODES_IN_EACH_CELL):
# not all nodes have same number of Type-1 output connection
for cc in range(MAX_NUM_OF_CONNECTIONS_PER_NODE - n - 1):
for e in range(NUM_OF_MIXED_OPS):
print("graph.cells[", c, "].nodes[", n, "].connections[", cc, "].f_weights.grad_fn = ",
graph.cells[c].nodes[n].connections[cc].f_weights.grad_fn)
print("graph.cells[", c, "].nodes[", n, "].connections[", cc, "].edges[", e, "].f.weight.grad_fn = ",
graph.cells[c].nodes[n].connections[cc].edges[e].f.weight.grad_fn)
for name, param in graph.named_parameters():
print(name, param.grad)
optimizer1.step()
else:
# no need to save model parameters for next epoch
return Ltrain
# DARTS's approximate architecture gradient. Refer to equation (8)
# needs to save intermediate trained model for Ltrain
path = './model.pth'
torch.save(graph, path)
print("after multiple for-loops")
return Ltrain
def train_architecture(forward_pass_only, train_or_val='val'):
print("Entering train_architecture(), forward_pass_only = ", forward_pass_only, " , train_or_val = ", train_or_val)
graph = Graph()
if USE_CUDA:
graph = graph.cuda()
criterion = nn.CrossEntropyLoss()
optimizer2 = optim.SGD(graph.parameters(), lr=LEARNING_RATE, momentum=MOMENTUM)
# just for initialization, no special meaning
Lval = 0
train_inputs = 0
train_labels = 0
val_inputs = 0
val_labels = 0
if forward_pass_only == 0:
# do train thing for internal NN function weights
graph.train()
# zero the parameter gradients
optimizer2.zero_grad()
print("before multiple for-loops")
for train_data, val_data in (zip(trainloader, valloader)):
train_inputs, train_labels = train_data
val_inputs, val_labels = val_data
if USE_CUDA:
train_inputs = train_inputs.cuda()
train_labels = train_labels.cuda()
val_inputs = val_inputs.cuda()
val_labels = val_labels.cuda()
for epoch in range(NUM_EPOCHS):
# forward pass
# use linear transformation ('weighted sum then concat') to combine results from different nodes
# into an output feature map to be fed into the next neighbour node for further processing
for c in range(NUM_OF_CELLS):
for n in range(NUM_OF_NODES_IN_EACH_CELL):
# not all nodes have same number of Type-1 output connection
for cc in range(MAX_NUM_OF_CONNECTIONS_PER_NODE - n - 1):
for e in range(NUM_OF_MIXED_OPS):
x = 0 # depends on the input tensor dimension requirement
if c == 0:
if train_or_val == 'val':
x = val_inputs
else:
x = train_inputs
else:
# Uses feature map output from previous neighbour node for further processing
x = graph.cells[c].nodes[n-1].connections[cc].combined_feature_map
# need to take care of tensors dimension mismatch
graph.cells[c].nodes[n].connections[cc].combined_feature_map += \
graph.cells[c].nodes[n].connections[cc].edges[e].forward_edge(x) # Lval(w*, alpha)
output2_tensor = graph.cells[NUM_OF_CELLS-1].output
output2_tensor = output2_tensor.view(output2_tensor.shape[0], -1)
if USE_CUDA:
output2_tensor = output2_tensor.cuda()
if USE_CUDA:
m_linear = nn.Linear(NUM_OF_IMAGE_CHANNELS * IMAGE_HEIGHT * IMAGE_WIDTH, NUM_OF_IMAGE_CLASSES).cuda()
else:
m_linear = nn.Linear(NUM_OF_IMAGE_CHANNELS * IMAGE_HEIGHT * IMAGE_WIDTH, NUM_OF_IMAGE_CLASSES)
outputs2 = m_linear(output2_tensor)
if USE_CUDA:
outputs2 = outputs2.cuda()
print("outputs2.size() = ", outputs2.size())
print("val_labels.size() = ", val_labels.size())
print("train_labels.size() = ", train_labels.size())
if train_or_val == 'val':
loss = criterion(outputs2, val_labels)
else:
loss = criterion(outputs2, train_labels)
if forward_pass_only == 0:
# backward pass
Lval = loss
Lval = Lval.requires_grad_()
Lval.backward()
for name, param in graph.named_parameters():
print(name, param.grad)
optimizer2.step()
else:
# no need to save model parameters for next epoch
return loss
# needs to save intermediate trained model for Lval
path = './model.pth'
torch.save(graph, path)
# DARTS's approximate architecture gradient. Refer to equation (8) and https://i.imgur.com/81JFaWc.png
sigma = LEARNING_RATE
epsilon = 0.01 / torch.norm(Lval)
for c in range(NUM_OF_CELLS):
for n in range(NUM_OF_NODES_IN_EACH_CELL):
# not all nodes have same number of Type-1 output connection
for cc in range(MAX_NUM_OF_CONNECTIONS_PER_NODE - n - 1):
CC = graph.cells[c].nodes[n].connections[cc]
for e in range(NUM_OF_MIXED_OPS):
for w in graph.cells[c].nodes[n].connections[cc].edges[e].f.parameters():
# https://mythrex.github.io/math_behind_darts/
# Finite Difference Method
CC.weight_plus = w + epsilon * Lval
CC.weight_minus = w - epsilon * Lval
# Backups original f_weights
CC.f_weights_backup = w
# replaces f_weights with weight_plus before NN training
for c in range(NUM_OF_CELLS):
for n in range(NUM_OF_NODES_IN_EACH_CELL):
# not all nodes have same number of Type-1 output connection
for cc in range(MAX_NUM_OF_CONNECTIONS_PER_NODE - n - 1):
CC = graph.cells[c].nodes[n].connections[cc]
for e in range(NUM_OF_MIXED_OPS):
for w in graph.cells[c].nodes[n].connections[cc].edges[e].f.parameters():
w = CC.weight_plus
# test NN to obtain loss
Ltrain_plus = train_architecture(forward_pass_only=1, train_or_val='train')
# replaces f_weights with weight_minus before NN training
for c in range(NUM_OF_CELLS):
for n in range(NUM_OF_NODES_IN_EACH_CELL):
# not all nodes have same number of Type-1 output connection
for cc in range(MAX_NUM_OF_CONNECTIONS_PER_NODE - n - 1):
CC = graph.cells[c].nodes[n].connections[cc]
for e in range(NUM_OF_MIXED_OPS):
for w in graph.cells[c].nodes[n].connections[cc].edges[e].f.parameters():
w = CC.weight_minus
# test NN to obtain loss
Ltrain_minus = train_architecture(forward_pass_only=1, train_or_val='train')
# Restores original f_weights
for c in range(NUM_OF_CELLS):
for n in range(NUM_OF_NODES_IN_EACH_CELL):
# not all nodes have same number of Type-1 output connection
for cc in range(MAX_NUM_OF_CONNECTIONS_PER_NODE - n - 1):
CC = graph.cells[c].nodes[n].connections[cc]
for e in range(NUM_OF_MIXED_OPS):
for w in graph.cells[c].nodes[n].connections[cc].edges[e].f.parameters():
w = CC.f_weights_backup
print("after multiple for-loops")
L2train_Lval = (Ltrain_plus - Ltrain_minus) / (2 * epsilon)
return Lval - L2train_Lval
if __name__ == "__main__":
run_num = 0
not_converged = 1
while not_converged:
print("run_num = ", run_num)
ltrain = train_NN(forward_pass_only=0)
print("Finished train_NN()")
# 'train_or_val' to differentiate between using training dataset and validation dataset
lval = train_architecture(forward_pass_only=0, train_or_val='val')
print("Finished train_architecture()")
print("lval = ", lval, " , ltrain = ", ltrain)
not_converged = (lval > 0.01) or (ltrain > 0.01)
run_num = run_num + 1
# do test thing
I don’t know, as this simple example works for me:
Ltrain = torch.randn(1, 1, requires_grad=True)
Ltrain.retain_grad()
Ltrain.register_hook(lambda x: print(x))
Ltrain.backward()
> tensor([[1.]])
Also,
Ltrain = criterion(outputs1, train_labels)
if forward_pass_only == 0:
# backward pass
Ltrain = Ltrain.requires_grad_()
calling .requires_grad_() on the loss tensor should not be necessary since it should be attached to the computation graph.
If you are using it as a workaround for another error, note that this does not fix the issue, since still no gradients would be computed and you should check why the tensor is detached instead.
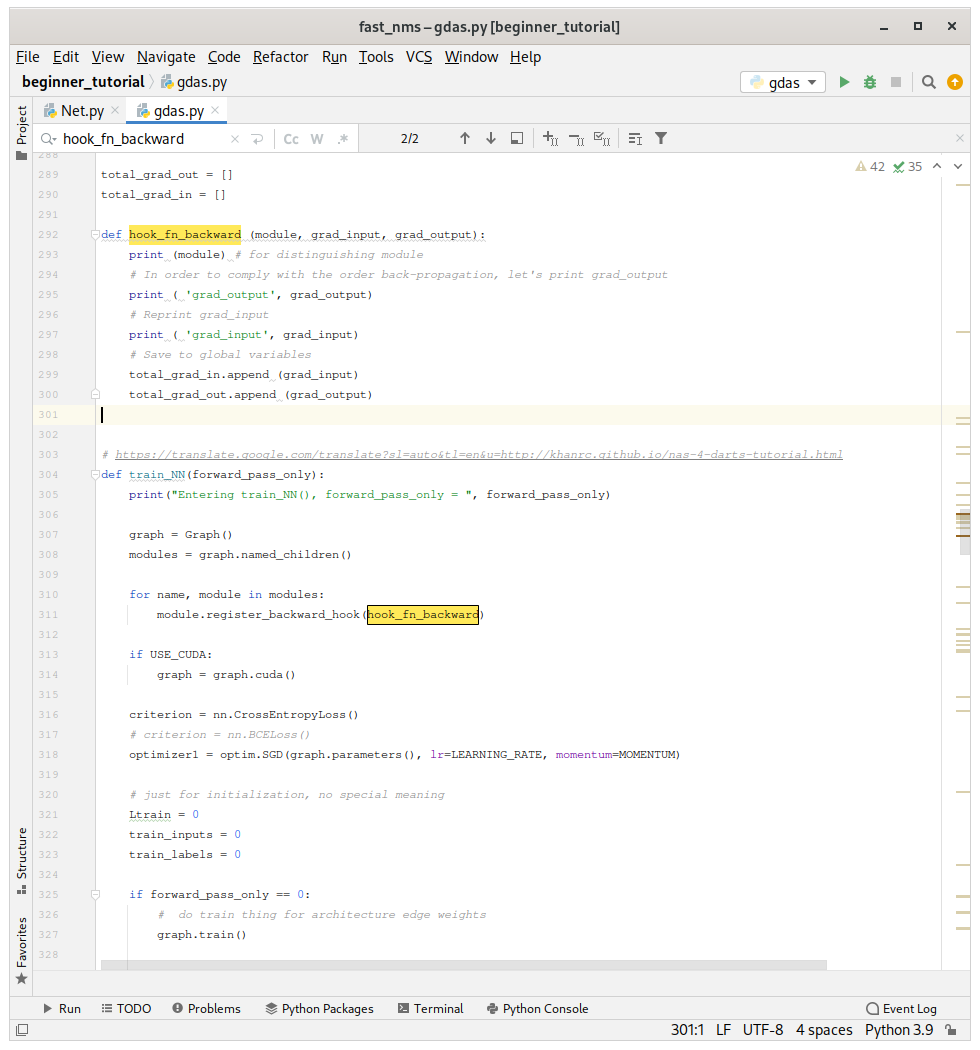
I also tried register_backward_hook , but again the hook function also does not work
# https://github.com/D-X-Y/AutoDL-Projects/issues/99
import torch
import torch.utils.data
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
# import numpy as np
torch.autograd.set_detect_anomaly(True)
USE_CUDA = torch.cuda.is_available()
# https://arxiv.org/pdf/1806.09055.pdf#page=12
TEST_DATASET_RATIO = 0.5 # 50 percent of the dataset is dedicated for testing purpose
BATCH_SIZE = 4
NUM_OF_IMAGE_CHANNELS = 3 # RGB
IMAGE_HEIGHT = 32
IMAGE_WIDTH = 32
NUM_OF_IMAGE_CLASSES = 10
SIZE_OF_HIDDEN_LAYERS = 64
NUM_EPOCHS = 1
LEARNING_RATE = 0.025
MOMENTUM = 0.9
NUM_OF_CELLS = 8
NUM_OF_MIXED_OPS = 4
NUM_OF_PREVIOUS_CELLS_OUTPUTS = 2 # last_cell_output , second_last_cell_output
NUM_OF_NODES_IN_EACH_CELL = 4
MAX_NUM_OF_CONNECTIONS_PER_NODE = NUM_OF_NODES_IN_EACH_CELL
NUM_OF_CHANNELS = 16
INTERVAL_BETWEEN_REDUCTION_CELLS = 3
PREVIOUS_PREVIOUS = 2 # (n-2)
REDUCTION_STRIDE = 2
NORMAL_STRIDE = 1
TAU_GUMBEL = 0.5
EDGE_WEIGHTS_NETWORK_IN_SIZE = 5
EDGE_WEIGHTS_NETWORK_OUT_SIZE = 2
# https://pytorch.org/tutorials/beginner/blitz/cifar10_tutorial.html
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=BATCH_SIZE,
shuffle=True, num_workers=2)
valset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform)
valloader = torch.utils.data.DataLoader(valset, batch_size=BATCH_SIZE,
shuffle=False, num_workers=2)
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
TRAIN_BATCH_SIZE = int(len(trainset) * (1 - TEST_DATASET_RATIO))
# https://discordapp.com/channels/687504710118146232/703298739732873296/853270183649083433
# for training for edge weights as well as internal NN function weights
class Edge(nn.Module):
def __init__(self):
super(Edge, self).__init__()
# https://stackoverflow.com/a/51027227/8776167
# self.linear = nn.Linear(EDGE_WEIGHTS_NETWORK_IN_SIZE, EDGE_WEIGHTS_NETWORK_OUT_SIZE)
# https://pytorch.org/docs/stable/generated/torch.nn.parameter.Parameter.html
self.weights = nn.Parameter(torch.zeros(1),
requires_grad=True) # for edge weights, not for internal NN function weights
def __freeze_w(self):
self.weights.requires_grad = False
def __unfreeze_w(self):
self.weights.requires_grad = True
def __freeze_f(self):
for param in self.f.parameters():
param.requires_grad = False
def __unfreeze_f(self):
for param in self.f.parameters():
param.requires_grad = True
# for NN functions internal weights training
def forward_f(self, x):
self.__unfreeze_f()
self.__freeze_w()
# inheritance in python classes and SOLID principles
# https://en.wikipedia.org/wiki/SOLID
# https://blog.cleancoder.com/uncle-bob/2020/10/18/Solid-Relevance.html
return self.f(x)
# self-defined initial NAS architecture, for supernet architecture edge weight training
def forward_edge(self, x):
self.__freeze_f()
self.__unfreeze_w()
return x * self.weights
class ConvEdge(Edge):
def __init__(self, stride):
super().__init__()
self.f = nn.Conv2d(in_channels=3, out_channels=3, kernel_size=(3, 3), stride=(stride, stride), padding=1)
class LinearEdge(Edge):
def __init__(self):
super().__init__()
self.f = nn.Linear(84, 10)
class MaxPoolEdge(Edge):
def __init__(self, stride):
super().__init__()
self.f = nn.MaxPool2d(kernel_size=3, stride=stride, padding=1, ceil_mode=True)
class AvgPoolEdge(Edge):
def __init__(self, stride):
super().__init__()
self.f = nn.AvgPool2d(kernel_size=3, stride=stride, padding=1, ceil_mode=True)
class Skip(nn.Module):
def forward(self, x):
return x
class SkipEdge(Edge):
def __init__(self):
super().__init__()
self.f = Skip()
# to collect and manage different edges between 2 nodes
class Connection(nn.Module):
def __init__(self, stride):
super(Connection, self).__init__()
if USE_CUDA:
# creates distinct edges and references each of them in a list (self.edges)
# self.linear_edge = LinearEdge().cuda()
self.conv2d_edge = ConvEdge(stride).cuda()
self.maxpool_edge = MaxPoolEdge(stride).cuda()
self.avgpool_edge = AvgPoolEdge(stride).cuda()
self.skip_edge = SkipEdge().cuda()
else:
# creates distinct edges and references each of them in a list (self.edges)
# self.linear_edge = LinearEdge()
self.conv2d_edge = ConvEdge(stride)
self.maxpool_edge = MaxPoolEdge(stride)
self.avgpool_edge = AvgPoolEdge(stride)
self.skip_edge = SkipEdge()
# self.edges = [self.conv2d_edge, self.maxpool_edge, self.avgpool_edge, self.skip_edge]
# python list will break the computation graph, need to use nn.ModuleList as a differentiable python list
self.edges = nn.ModuleList([self.conv2d_edge, self.maxpool_edge, self.avgpool_edge, self.skip_edge])
self.edge_weights = torch.zeros(NUM_OF_MIXED_OPS, requires_grad=True)
# for approximate architecture gradient
self.f_weights = torch.zeros(NUM_OF_MIXED_OPS, requires_grad=True)
self.f_weights_backup = torch.zeros(NUM_OF_MIXED_OPS, requires_grad=True)
self.weight_plus = torch.zeros(NUM_OF_MIXED_OPS, requires_grad=True)
self.weight_minus = torch.zeros(NUM_OF_MIXED_OPS, requires_grad=True)
# use linear transformation (weighted summation) to combine results from different edges
self.combined_feature_map = torch.zeros([BATCH_SIZE, NUM_OF_IMAGE_CHANNELS, IMAGE_HEIGHT, IMAGE_WIDTH],
requires_grad=True)
if USE_CUDA:
self.combined_feature_map = self.combined_feature_map.cuda()
for e in range(NUM_OF_MIXED_OPS):
with torch.no_grad():
self.edge_weights[e] = self.edges[e].weights
# https://stackoverflow.com/a/45024500/8776167 extracts the weights learned through NN functions
# self.f_weights[e] = list(self.edges[e].parameters())
# Refer to GDAS equations (5) and (6)
# if one_hot is already there, would summation be required given that all other entries are forced to 0 ?
# It's not required, but you don't know, which index is one hot encoded 1.
# https://pytorch.org/docs/stable/nn.functional.html#gumbel-softmax
gumbel = F.gumbel_softmax(self.edge_weights, tau=TAU_GUMBEL, hard=True)
self.chosen_edge = torch.argmax(gumbel, dim=0) # converts one-hot encoding into integer
# to collect and manage multiple different connections between a particular node and its neighbouring nodes
class Node(nn.Module):
def __init__(self, stride):
super(Node, self).__init__()
# two types of output connections
# Type 1: (multiple edges) output connects to the input of the other intermediate nodes
# Type 2: (single edge) output connects directly to the final output node
# Type 1
self.connections = nn.ModuleList([Connection(stride) for i in range(MAX_NUM_OF_CONNECTIONS_PER_NODE)])
# Type 2
# depends on PREVIOUS node's Type 1 output
self.output = torch.zeros([BATCH_SIZE, NUM_OF_IMAGE_CHANNELS, IMAGE_HEIGHT, IMAGE_WIDTH],
requires_grad=True) # for initialization
if USE_CUDA:
self.output = self.output.cuda()
# to manage all nodes within a cell
class Cell(nn.Module):
def __init__(self, stride):
super(Cell, self).__init__()
# all the coloured edges inside
# https://user-images.githubusercontent.com/3324659/117573177-20ea9a80-b109-11eb-9418-16e22e684164.png
# A single cell contains 'NUM_OF_NODES_IN_EACH_CELL' distinct nodes
# for the k-th node, we have (k+1) preceding nodes.
# Each intermediate state, 0->3 ('NUM_OF_NODES_IN_EACH_CELL-1'),
# is connected to each previous intermediate state
# as well as the output of the previous two cells, c_{k-2} and c_{k-1} (after a preprocessing layer).
# previous_previous_cell_output = c_{k-2}
# previous_cell_output = c{k-1}
self.nodes = nn.ModuleList([Node(stride) for i in range(NUM_OF_NODES_IN_EACH_CELL)])
# just for variables initialization
self.previous_cell = 0
self.previous_previous_cell = 0
self.output = torch.zeros([BATCH_SIZE, NUM_OF_IMAGE_CHANNELS, IMAGE_HEIGHT, IMAGE_WIDTH],
requires_grad=True)
if USE_CUDA:
self.output = self.output.cuda()
for n in range(NUM_OF_NODES_IN_EACH_CELL):
# 'add' then 'concat' feature maps from different nodes
# needs to take care of tensor dimension mismatch
# See https://github.com/D-X-Y/AutoDL-Projects/issues/99#issuecomment-869100416
self.output = self.output + self.nodes[n].output
# to manage all nodes
class Graph(nn.Module):
def __init__(self):
super(Graph, self).__init__()
stride = 0 # just to initialize a variable
for i in range(NUM_OF_CELLS):
if i % INTERVAL_BETWEEN_REDUCTION_CELLS == 0:
stride = REDUCTION_STRIDE # to emulate reduction cell by using normal cell with stride=2
else:
stride = NORMAL_STRIDE # normal cell
self.cells = nn.ModuleList([Cell(stride) for i in range(NUM_OF_CELLS)])
def hook_fn(m, i, o):
print(m)
print("------------Input Grad------------")
for grad in i:
try:
print(grad.shape)
except AttributeError:
print ("None found for Gradient")
print("------------Output Grad------------")
for grad in o:
try:
print(grad.shape)
except AttributeError:
print ("None found for Gradient")
print("\n")
total_grad_out = []
total_grad_in = []
def hook_fn_backward (module, grad_input, grad_output):
print (module) # for distinguishing module
# In order to comply with the order back-propagation, let's print grad_output
print ( 'grad_output', grad_output)
# Reprint grad_input
print ( 'grad_input', grad_input)
# Save to global variables
total_grad_in.append (grad_input)
total_grad_out.append (grad_output)
# https://translate.google.com/translate?sl=auto&tl=en&u=http://khanrc.github.io/nas-4-darts-tutorial.html
def train_NN(forward_pass_only):
print("Entering train_NN(), forward_pass_only = ", forward_pass_only)
graph = Graph()
modules = graph.named_children()
for name, module in modules:
module.register_backward_hook(hook_fn_backward)
if USE_CUDA:
graph = graph.cuda()
criterion = nn.CrossEntropyLoss()
# criterion = nn.BCELoss()
optimizer1 = optim.SGD(graph.parameters(), lr=LEARNING_RATE, momentum=MOMENTUM)
# just for initialization, no special meaning
Ltrain = 0
train_inputs = 0
train_labels = 0
if forward_pass_only == 0:
# do train thing for architecture edge weights
graph.train()
# zero the parameter gradients
optimizer1.zero_grad()
print("before multiple for-loops")
for train_data, val_data in (zip(trainloader, valloader)):
train_inputs, train_labels = train_data
# val_inputs, val_labels = val_data
if USE_CUDA:
train_inputs = train_inputs.cuda()
train_labels = train_labels.cuda()
for epoch in range(NUM_EPOCHS):
# forward pass
for c in range(NUM_OF_CELLS):
for n in range(NUM_OF_NODES_IN_EACH_CELL):
# not all nodes have same number of Type-1 output connection
for cc in range(MAX_NUM_OF_CONNECTIONS_PER_NODE - n - 1):
for e in range(NUM_OF_MIXED_OPS):
if c == 0:
x = train_inputs
else:
if n == 0:
# Uses feature map output from previous neighbour cell for further processing
x = graph.cells[c-1].nodes[NUM_OF_NODES_IN_EACH_CELL-1].connections[cc].combined_feature_map
else:
# Uses feature map output from previous neighbour node for further processing
x = graph.cells[c].nodes[n-1].connections[cc].combined_feature_map
if USE_CUDA:
x = x.cuda()
# combines all the feature maps from different mixed ops edges
graph.cells[c].nodes[n].connections[cc].combined_feature_map = \
graph.cells[c].nodes[n].connections[cc].combined_feature_map + \
graph.cells[c].nodes[n].connections[cc].edges[e].forward_f(x) # Ltrain(w±, alpha)
print("graph.cells[", c, "].nodes[", n, "].connections[", cc, "].edge_weights[", e, "].grad_fn = ",
graph.cells[c].nodes[n].connections[cc].edge_weights[e].grad_fn)
print("graph.cells[", c, "].output.grad_fn = ",
graph.cells[c].output.grad_fn)
# https://www.reddit.com/r/learnpython/comments/no7btk/how_to_carry_extra_information_across_dag/
# https://docs.python.org/3/tutorial/datastructures.html
# generates a supernet consisting of 'NUM_OF_CELLS' cells
# each cell contains of 'NUM_OF_NODES_IN_EACH_CELL' nodes
# refer to PNASNet https://arxiv.org/pdf/1712.00559.pdf#page=5 for the cell arrangement
# https://pytorch.org/tutorials/beginner/examples_autograd/two_layer_net_custom_function.html
# encodes the cells and nodes arrangement in the multigraph
if c > 1: # for previous_previous_cell, (c-2)
graph.cells[c].previous_cell = graph.cells[c - 1].output
graph.cells[c].previous_previous_cell = graph.cells[c - PREVIOUS_PREVIOUS].output
if n == 0:
if c <= 1:
graph.cells[c].nodes[n].output = graph.cells[c].nodes[n].connections[cc].combined_feature_map
else: # there is no input from previous cells for the first two cells
# needs to take care tensor dimension mismatch from multiple edges connections
graph.cells[c].nodes[n].output += \
graph.cells[c-1].nodes[NUM_OF_NODES_IN_EACH_CELL-1].connections[cc].combined_feature_map + \
graph.cells[c-PREVIOUS_PREVIOUS].nodes[NUM_OF_NODES_IN_EACH_CELL-1].connections[cc].combined_feature_map
else: # n > 0
# depends on PREVIOUS node's Type 1 connection
# needs to take care tensor dimension mismatch from multiple edges connections
print("graph.cells[", c ,"].nodes[" ,n, "].output.size() = ",
graph.cells[c].nodes[n].output.size())
print("graph.cells[", c, "].nodes[", n-1, "].connections[", cc, "].combined_feature_map.size() = ",
graph.cells[c].nodes[n-1].connections[cc].combined_feature_map.size())
graph.cells[c].nodes[n].output += \
graph.cells[c].nodes[n-1].connections[cc].combined_feature_map + \
graph.cells[c - 1].nodes[NUM_OF_NODES_IN_EACH_CELL - 1].connections[cc].combined_feature_map + \
graph.cells[c - PREVIOUS_PREVIOUS].nodes[NUM_OF_NODES_IN_EACH_CELL - 1].connections[cc].combined_feature_map
print("graph.cells[", c, "].nodes[", n, "].output.grad_fn = ",
graph.cells[c].nodes[n].output.grad_fn)
# 'add' then 'concat' feature maps from different nodes
# needs to take care of tensor dimension mismatch
# See https://github.com/D-X-Y/AutoDL-Projects/issues/99#issuecomment-869100416
graph.cells[c].output += graph.cells[c].nodes[n].output
print("graph.cells[", c, "].output.grad_fn = ",
graph.cells[c].output.grad_fn)
output_tensor = graph.cells[NUM_OF_CELLS-1].output
output_tensor = output_tensor.view(output_tensor.shape[0], -1)
if USE_CUDA:
output_tensor = output_tensor.cuda()
if USE_CUDA:
m_linear = nn.Linear(NUM_OF_IMAGE_CHANNELS * IMAGE_HEIGHT * IMAGE_WIDTH, NUM_OF_IMAGE_CLASSES).cuda()
else:
m_linear = nn.Linear(NUM_OF_IMAGE_CHANNELS * IMAGE_HEIGHT * IMAGE_WIDTH, NUM_OF_IMAGE_CLASSES)
outputs1 = m_linear(output_tensor)
if USE_CUDA:
outputs1 = outputs1.cuda()
print("outputs1.size() = ", outputs1.size())
print("train_labels.size() = ", train_labels.size())
Ltrain = criterion(outputs1, train_labels)
if forward_pass_only == 0:
# backward pass
Ltrain = Ltrain.requires_grad_()
Ltrain.retain_grad()
Ltrain.register_hook(lambda x: print(x))
Ltrain.backward()
for c in range(NUM_OF_CELLS):
for n in range(NUM_OF_NODES_IN_EACH_CELL):
# not all nodes have same number of Type-1 output connection
for cc in range(MAX_NUM_OF_CONNECTIONS_PER_NODE - n - 1):
for e in range(NUM_OF_MIXED_OPS):
print("graph.cells[", c, "].nodes[", n, "].connections[", cc, "].f_weights.grad_fn = ",
graph.cells[c].nodes[n].connections[cc].f_weights.grad_fn)
print("graph.cells[", c, "].nodes[", n, "].connections[", cc, "].edges[", e, "].f.weight.grad_fn = ",
graph.cells[c].nodes[n].connections[cc].edges[e].f.weight.grad_fn)
for name, param in graph.named_parameters():
print(name, param.grad)
optimizer1.step()
else:
# no need to save model parameters for next epoch
return Ltrain
# DARTS's approximate architecture gradient. Refer to equation (8)
# needs to save intermediate trained model for Ltrain
path = './model.pth'
torch.save(graph, path)
print("after multiple for-loops")
return Ltrain
def train_architecture(forward_pass_only, train_or_val='val'):
print("Entering train_architecture(), forward_pass_only = ", forward_pass_only, " , train_or_val = ", train_or_val)
graph = Graph()
if USE_CUDA:
graph = graph.cuda()
criterion = nn.CrossEntropyLoss()
optimizer2 = optim.SGD(graph.parameters(), lr=LEARNING_RATE, momentum=MOMENTUM)
# just for initialization, no special meaning
Lval = 0
train_inputs = 0
train_labels = 0
val_inputs = 0
val_labels = 0
if forward_pass_only == 0:
# do train thing for internal NN function weights
graph.train()
# zero the parameter gradients
optimizer2.zero_grad()
print("before multiple for-loops")
for train_data, val_data in (zip(trainloader, valloader)):
train_inputs, train_labels = train_data
val_inputs, val_labels = val_data
if USE_CUDA:
train_inputs = train_inputs.cuda()
train_labels = train_labels.cuda()
val_inputs = val_inputs.cuda()
val_labels = val_labels.cuda()
for epoch in range(NUM_EPOCHS):
# forward pass
# use linear transformation ('weighted sum then concat') to combine results from different nodes
# into an output feature map to be fed into the next neighbour node for further processing
for c in range(NUM_OF_CELLS):
for n in range(NUM_OF_NODES_IN_EACH_CELL):
# not all nodes have same number of Type-1 output connection
for cc in range(MAX_NUM_OF_CONNECTIONS_PER_NODE - n - 1):
for e in range(NUM_OF_MIXED_OPS):
x = 0 # depends on the input tensor dimension requirement
if c == 0:
if train_or_val == 'val':
x = val_inputs
else:
x = train_inputs
else:
# Uses feature map output from previous neighbour node for further processing
x = graph.cells[c].nodes[n-1].connections[cc].combined_feature_map
# need to take care of tensors dimension mismatch
graph.cells[c].nodes[n].connections[cc].combined_feature_map += \
graph.cells[c].nodes[n].connections[cc].edges[e].forward_edge(x) # Lval(w*, alpha)
output2_tensor = graph.cells[NUM_OF_CELLS-1].output
output2_tensor = output2_tensor.view(output2_tensor.shape[0], -1)
if USE_CUDA:
output2_tensor = output2_tensor.cuda()
if USE_CUDA:
m_linear = nn.Linear(NUM_OF_IMAGE_CHANNELS * IMAGE_HEIGHT * IMAGE_WIDTH, NUM_OF_IMAGE_CLASSES).cuda()
else:
m_linear = nn.Linear(NUM_OF_IMAGE_CHANNELS * IMAGE_HEIGHT * IMAGE_WIDTH, NUM_OF_IMAGE_CLASSES)
outputs2 = m_linear(output2_tensor)
if USE_CUDA:
outputs2 = outputs2.cuda()
print("outputs2.size() = ", outputs2.size())
print("val_labels.size() = ", val_labels.size())
print("train_labels.size() = ", train_labels.size())
if train_or_val == 'val':
loss = criterion(outputs2, val_labels)
else:
loss = criterion(outputs2, train_labels)
if forward_pass_only == 0:
# backward pass
Lval = loss
Lval = Lval.requires_grad_()
Lval.backward()
for name, param in graph.named_parameters():
print(name, param.grad)
optimizer2.step()
else:
# no need to save model parameters for next epoch
return loss
# needs to save intermediate trained model for Lval
path = './model.pth'
torch.save(graph, path)
# DARTS's approximate architecture gradient. Refer to equation (8) and https://i.imgur.com/81JFaWc.png
sigma = LEARNING_RATE
epsilon = 0.01 / torch.norm(Lval)
for c in range(NUM_OF_CELLS):
for n in range(NUM_OF_NODES_IN_EACH_CELL):
# not all nodes have same number of Type-1 output connection
for cc in range(MAX_NUM_OF_CONNECTIONS_PER_NODE - n - 1):
CC = graph.cells[c].nodes[n].connections[cc]
for e in range(NUM_OF_MIXED_OPS):
for w in graph.cells[c].nodes[n].connections[cc].edges[e].f.parameters():
# https://mythrex.github.io/math_behind_darts/
# Finite Difference Method
CC.weight_plus = w + epsilon * Lval
CC.weight_minus = w - epsilon * Lval
# Backups original f_weights
CC.f_weights_backup = w
# replaces f_weights with weight_plus before NN training
for c in range(NUM_OF_CELLS):
for n in range(NUM_OF_NODES_IN_EACH_CELL):
# not all nodes have same number of Type-1 output connection
for cc in range(MAX_NUM_OF_CONNECTIONS_PER_NODE - n - 1):
CC = graph.cells[c].nodes[n].connections[cc]
for e in range(NUM_OF_MIXED_OPS):
for w in graph.cells[c].nodes[n].connections[cc].edges[e].f.parameters():
w = CC.weight_plus
# test NN to obtain loss
Ltrain_plus = train_architecture(forward_pass_only=1, train_or_val='train')
# replaces f_weights with weight_minus before NN training
for c in range(NUM_OF_CELLS):
for n in range(NUM_OF_NODES_IN_EACH_CELL):
# not all nodes have same number of Type-1 output connection
for cc in range(MAX_NUM_OF_CONNECTIONS_PER_NODE - n - 1):
CC = graph.cells[c].nodes[n].connections[cc]
for e in range(NUM_OF_MIXED_OPS):
for w in graph.cells[c].nodes[n].connections[cc].edges[e].f.parameters():
w = CC.weight_minus
# test NN to obtain loss
Ltrain_minus = train_architecture(forward_pass_only=1, train_or_val='train')
# Restores original f_weights
for c in range(NUM_OF_CELLS):
for n in range(NUM_OF_NODES_IN_EACH_CELL):
# not all nodes have same number of Type-1 output connection
for cc in range(MAX_NUM_OF_CONNECTIONS_PER_NODE - n - 1):
CC = graph.cells[c].nodes[n].connections[cc]
for e in range(NUM_OF_MIXED_OPS):
for w in graph.cells[c].nodes[n].connections[cc].edges[e].f.parameters():
w = CC.f_weights_backup
print("after multiple for-loops")
L2train_Lval = (Ltrain_plus - Ltrain_minus) / (2 * epsilon)
return Lval - L2train_Lval
if __name__ == "__main__":
run_num = 0
not_converged = 1
while not_converged:
print("run_num = ", run_num)
ltrain = train_NN(forward_pass_only=0)
print("Finished train_NN()")
# 'train_or_val' to differentiate between using training dataset and validation dataset
lval = train_architecture(forward_pass_only=0, train_or_val='val')
print("Finished train_architecture()")
print("lval = ", lval, " , ltrain = ", ltrain)
not_converged = (lval > 0.01) or (ltrain > 0.01)
run_num = run_num + 1
# do test thing
Have a look at the console output of next(modules) during breakpoint debugging.
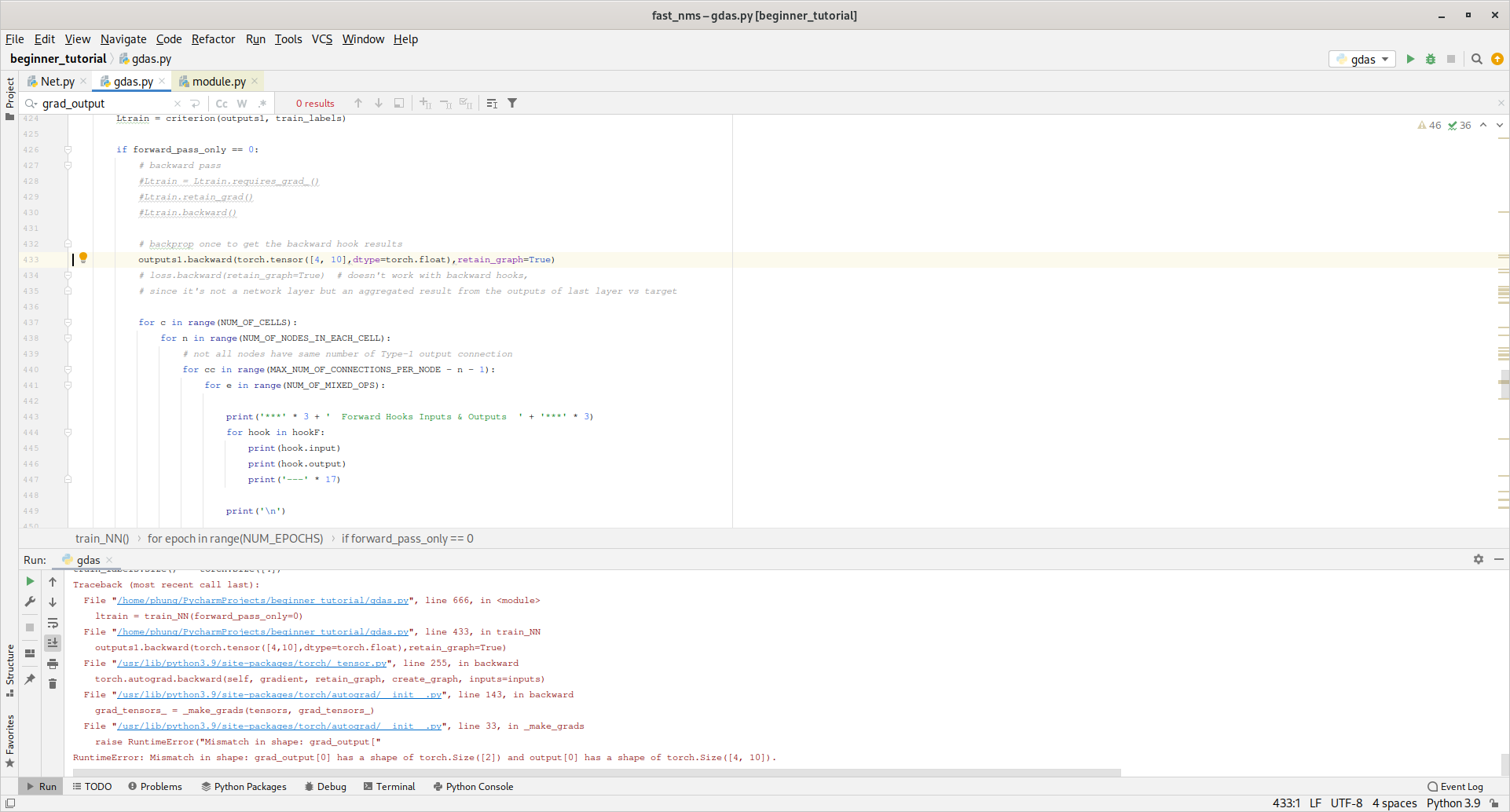
I tried using this kaggle guide for hook function, but I have the RuntimeError: Mismatch in shape: grad_output[0] has a shape of torch.Size([2]) and output[0] has a shape of torch.Size([4, 10]).
# https://github.com/D-X-Y/AutoDL-Projects/issues/99
import torch
import torch.utils.data
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
# import numpy as np
torch.autograd.set_detect_anomaly(True)
USE_CUDA = torch.cuda.is_available()
# https://arxiv.org/pdf/1806.09055.pdf#page=12
TEST_DATASET_RATIO = 0.5 # 50 percent of the dataset is dedicated for testing purpose
BATCH_SIZE = 4
NUM_OF_IMAGE_CHANNELS = 3 # RGB
IMAGE_HEIGHT = 32
IMAGE_WIDTH = 32
NUM_OF_IMAGE_CLASSES = 10
SIZE_OF_HIDDEN_LAYERS = 64
NUM_EPOCHS = 1
LEARNING_RATE = 0.025
MOMENTUM = 0.9
NUM_OF_CELLS = 8
NUM_OF_MIXED_OPS = 4
NUM_OF_PREVIOUS_CELLS_OUTPUTS = 2 # last_cell_output , second_last_cell_output
NUM_OF_NODES_IN_EACH_CELL = 4
MAX_NUM_OF_CONNECTIONS_PER_NODE = NUM_OF_NODES_IN_EACH_CELL
NUM_OF_CHANNELS = 16
INTERVAL_BETWEEN_REDUCTION_CELLS = 3
PREVIOUS_PREVIOUS = 2 # (n-2)
REDUCTION_STRIDE = 2
NORMAL_STRIDE = 1
TAU_GUMBEL = 0.5
EDGE_WEIGHTS_NETWORK_IN_SIZE = 5
EDGE_WEIGHTS_NETWORK_OUT_SIZE = 2
# https://pytorch.org/tutorials/beginner/blitz/cifar10_tutorial.html
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=BATCH_SIZE,
shuffle=True, num_workers=2)
valset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform)
valloader = torch.utils.data.DataLoader(valset, batch_size=BATCH_SIZE,
shuffle=False, num_workers=2)
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
TRAIN_BATCH_SIZE = int(len(trainset) * (1 - TEST_DATASET_RATIO))
# https://discordapp.com/channels/687504710118146232/703298739732873296/853270183649083433
# for training for edge weights as well as internal NN function weights
class Edge(nn.Module):
def __init__(self):
super(Edge, self).__init__()
# https://stackoverflow.com/a/51027227/8776167
# self.linear = nn.Linear(EDGE_WEIGHTS_NETWORK_IN_SIZE, EDGE_WEIGHTS_NETWORK_OUT_SIZE)
# https://pytorch.org/docs/stable/generated/torch.nn.parameter.Parameter.html
self.weights = nn.Parameter(torch.zeros(1),
requires_grad=True) # for edge weights, not for internal NN function weights
def __freeze_w(self):
self.weights.requires_grad = False
def __unfreeze_w(self):
self.weights.requires_grad = True
def __freeze_f(self):
for param in self.f.parameters():
param.requires_grad = False
def __unfreeze_f(self):
for param in self.f.parameters():
param.requires_grad = True
# for NN functions internal weights training
def forward_f(self, x):
self.__unfreeze_f()
self.__freeze_w()
# inheritance in python classes and SOLID principles
# https://en.wikipedia.org/wiki/SOLID
# https://blog.cleancoder.com/uncle-bob/2020/10/18/Solid-Relevance.html
return self.f(x)
# self-defined initial NAS architecture, for supernet architecture edge weight training
def forward_edge(self, x):
self.__freeze_f()
self.__unfreeze_w()
return x * self.weights
class ConvEdge(Edge):
def __init__(self, stride):
super().__init__()
self.f = nn.Conv2d(in_channels=3, out_channels=3, kernel_size=(3, 3), stride=(stride, stride), padding=1)
class LinearEdge(Edge):
def __init__(self):
super().__init__()
self.f = nn.Linear(84, 10)
class MaxPoolEdge(Edge):
def __init__(self, stride):
super().__init__()
self.f = nn.MaxPool2d(kernel_size=3, stride=stride, padding=1, ceil_mode=True)
class AvgPoolEdge(Edge):
def __init__(self, stride):
super().__init__()
self.f = nn.AvgPool2d(kernel_size=3, stride=stride, padding=1, ceil_mode=True)
class Skip(nn.Module):
def forward(self, x):
return x
class SkipEdge(Edge):
def __init__(self):
super().__init__()
self.f = Skip()
# to collect and manage different edges between 2 nodes
class Connection(nn.Module):
def __init__(self, stride):
super(Connection, self).__init__()
if USE_CUDA:
# creates distinct edges and references each of them in a list (self.edges)
# self.linear_edge = LinearEdge().cuda()
self.conv2d_edge = ConvEdge(stride).cuda()
self.maxpool_edge = MaxPoolEdge(stride).cuda()
self.avgpool_edge = AvgPoolEdge(stride).cuda()
self.skip_edge = SkipEdge().cuda()
else:
# creates distinct edges and references each of them in a list (self.edges)
# self.linear_edge = LinearEdge()
self.conv2d_edge = ConvEdge(stride)
self.maxpool_edge = MaxPoolEdge(stride)
self.avgpool_edge = AvgPoolEdge(stride)
self.skip_edge = SkipEdge()
# self.edges = [self.conv2d_edge, self.maxpool_edge, self.avgpool_edge, self.skip_edge]
# python list will break the computation graph, need to use nn.ModuleList as a differentiable python list
self.edges = nn.ModuleList([self.conv2d_edge, self.maxpool_edge, self.avgpool_edge, self.skip_edge])
self.edge_weights = torch.zeros(NUM_OF_MIXED_OPS, requires_grad=True)
# for approximate architecture gradient
self.f_weights = torch.zeros(NUM_OF_MIXED_OPS, requires_grad=True)
self.f_weights_backup = torch.zeros(NUM_OF_MIXED_OPS, requires_grad=True)
self.weight_plus = torch.zeros(NUM_OF_MIXED_OPS, requires_grad=True)
self.weight_minus = torch.zeros(NUM_OF_MIXED_OPS, requires_grad=True)
# use linear transformation (weighted summation) to combine results from different edges
self.combined_feature_map = torch.zeros([BATCH_SIZE, NUM_OF_IMAGE_CHANNELS, IMAGE_HEIGHT, IMAGE_WIDTH],
requires_grad=True)
if USE_CUDA:
self.combined_feature_map = self.combined_feature_map.cuda()
for e in range(NUM_OF_MIXED_OPS):
with torch.no_grad():
self.edge_weights[e] = self.edges[e].weights
# https://stackoverflow.com/a/45024500/8776167 extracts the weights learned through NN functions
# self.f_weights[e] = list(self.edges[e].parameters())
# Refer to GDAS equations (5) and (6)
# if one_hot is already there, would summation be required given that all other entries are forced to 0 ?
# It's not required, but you don't know, which index is one hot encoded 1.
# https://pytorch.org/docs/stable/nn.functional.html#gumbel-softmax
gumbel = F.gumbel_softmax(self.edge_weights, tau=TAU_GUMBEL, hard=True)
self.chosen_edge = torch.argmax(gumbel, dim=0) # converts one-hot encoding into integer
# to collect and manage multiple different connections between a particular node and its neighbouring nodes
class Node(nn.Module):
def __init__(self, stride):
super(Node, self).__init__()
# two types of output connections
# Type 1: (multiple edges) output connects to the input of the other intermediate nodes
# Type 2: (single edge) output connects directly to the final output node
# Type 1
self.connections = nn.ModuleList([Connection(stride) for i in range(MAX_NUM_OF_CONNECTIONS_PER_NODE)])
# Type 2
# depends on PREVIOUS node's Type 1 output
self.output = torch.zeros([BATCH_SIZE, NUM_OF_IMAGE_CHANNELS, IMAGE_HEIGHT, IMAGE_WIDTH],
requires_grad=True) # for initialization
if USE_CUDA:
self.output = self.output.cuda()
# to manage all nodes within a cell
class Cell(nn.Module):
def __init__(self, stride):
super(Cell, self).__init__()
# all the coloured edges inside
# https://user-images.githubusercontent.com/3324659/117573177-20ea9a80-b109-11eb-9418-16e22e684164.png
# A single cell contains 'NUM_OF_NODES_IN_EACH_CELL' distinct nodes
# for the k-th node, we have (k+1) preceding nodes.
# Each intermediate state, 0->3 ('NUM_OF_NODES_IN_EACH_CELL-1'),
# is connected to each previous intermediate state
# as well as the output of the previous two cells, c_{k-2} and c_{k-1} (after a preprocessing layer).
# previous_previous_cell_output = c_{k-2}
# previous_cell_output = c{k-1}
self.nodes = nn.ModuleList([Node(stride) for i in range(NUM_OF_NODES_IN_EACH_CELL)])
# just for variables initialization
self.previous_cell = 0
self.previous_previous_cell = 0
self.output = torch.zeros([BATCH_SIZE, NUM_OF_IMAGE_CHANNELS, IMAGE_HEIGHT, IMAGE_WIDTH],
requires_grad=True)
if USE_CUDA:
self.output = self.output.cuda()
for n in range(NUM_OF_NODES_IN_EACH_CELL):
# 'add' then 'concat' feature maps from different nodes
# needs to take care of tensor dimension mismatch
# See https://github.com/D-X-Y/AutoDL-Projects/issues/99#issuecomment-869100416
self.output = self.output + self.nodes[n].output
# to manage all nodes
class Graph(nn.Module):
def __init__(self):
super(Graph, self).__init__()
stride = 0 # just to initialize a variable
for i in range(NUM_OF_CELLS):
if i % INTERVAL_BETWEEN_REDUCTION_CELLS == 0:
stride = REDUCTION_STRIDE # to emulate reduction cell by using normal cell with stride=2
else:
stride = NORMAL_STRIDE # normal cell
self.cells = nn.ModuleList([Cell(stride) for i in range(NUM_OF_CELLS)])
# A simple hook class that returns the input and output of a layer during forward/backward pass
class Hook():
def __init__(self, module, backward=False):
if backward==False:
self.hook = module.register_forward_hook(self.hook_fn)
else:
self.hook = module.register_backward_hook(self.hook_fn)
def hook_fn(self, module, input, output):
self.input = input
self.output = output
def close(self):
self.hook.remove()
# https://translate.google.com/translate?sl=auto&tl=en&u=http://khanrc.github.io/nas-4-darts-tutorial.html
def train_NN(forward_pass_only):
print("Entering train_NN(), forward_pass_only = ", forward_pass_only)
graph = Graph()
if USE_CUDA:
graph = graph.cuda()
# register hooks on each layer
hookF = [Hook(layer[1]) for layer in list(graph._modules.items())]
hookB = [Hook(layer[1], backward=True) for layer in list(graph._modules.items())]
criterion = nn.CrossEntropyLoss()
# criterion = nn.BCELoss()
optimizer1 = optim.SGD(graph.parameters(), lr=LEARNING_RATE, momentum=MOMENTUM)
# just for initialization, no special meaning
Ltrain = 0
train_inputs = 0
train_labels = 0
if forward_pass_only == 0:
# do train thing for architecture edge weights
graph.train()
# zero the parameter gradients
optimizer1.zero_grad()
print("before multiple for-loops")
for train_data, val_data in (zip(trainloader, valloader)):
train_inputs, train_labels = train_data
# val_inputs, val_labels = val_data
if USE_CUDA:
train_inputs = train_inputs.cuda()
train_labels = train_labels.cuda()
for epoch in range(NUM_EPOCHS):
# forward pass
for c in range(NUM_OF_CELLS):
for n in range(NUM_OF_NODES_IN_EACH_CELL):
# not all nodes have same number of Type-1 output connection
for cc in range(MAX_NUM_OF_CONNECTIONS_PER_NODE - n - 1):
for e in range(NUM_OF_MIXED_OPS):
if c == 0:
x = train_inputs
else:
if n == 0:
# Uses feature map output from previous neighbour cell for further processing
x = graph.cells[c-1].nodes[NUM_OF_NODES_IN_EACH_CELL-1].connections[cc].combined_feature_map
else:
# Uses feature map output from previous neighbour node for further processing
x = graph.cells[c].nodes[n-1].connections[cc].combined_feature_map
if USE_CUDA:
x = x.cuda()
# combines all the feature maps from different mixed ops edges
graph.cells[c].nodes[n].connections[cc].combined_feature_map = \
graph.cells[c].nodes[n].connections[cc].combined_feature_map + \
graph.cells[c].nodes[n].connections[cc].edges[e].forward_f(x) # Ltrain(w±, alpha)
print("graph.cells[", c, "].nodes[", n, "].connections[", cc, "].edge_weights[", e, "].grad_fn = ",
graph.cells[c].nodes[n].connections[cc].edge_weights[e].grad_fn)
print("graph.cells[", c, "].output.grad_fn = ",
graph.cells[c].output.grad_fn)
# https://www.reddit.com/r/learnpython/comments/no7btk/how_to_carry_extra_information_across_dag/
# https://docs.python.org/3/tutorial/datastructures.html
# generates a supernet consisting of 'NUM_OF_CELLS' cells
# each cell contains of 'NUM_OF_NODES_IN_EACH_CELL' nodes
# refer to PNASNet https://arxiv.org/pdf/1712.00559.pdf#page=5 for the cell arrangement
# https://pytorch.org/tutorials/beginner/examples_autograd/two_layer_net_custom_function.html
# encodes the cells and nodes arrangement in the multigraph
if c > 1: # for previous_previous_cell, (c-2)
graph.cells[c].previous_cell = graph.cells[c - 1].output
graph.cells[c].previous_previous_cell = graph.cells[c - PREVIOUS_PREVIOUS].output
if n == 0:
if c <= 1:
graph.cells[c].nodes[n].output = graph.cells[c].nodes[n].connections[cc].combined_feature_map
else: # there is no input from previous cells for the first two cells
# needs to take care tensor dimension mismatch from multiple edges connections
graph.cells[c].nodes[n].output += \
graph.cells[c-1].nodes[NUM_OF_NODES_IN_EACH_CELL-1].connections[cc].combined_feature_map + \
graph.cells[c-PREVIOUS_PREVIOUS].nodes[NUM_OF_NODES_IN_EACH_CELL-1].connections[cc].combined_feature_map
else: # n > 0
# depends on PREVIOUS node's Type 1 connection
# needs to take care tensor dimension mismatch from multiple edges connections
print("graph.cells[", c ,"].nodes[" ,n, "].output.size() = ",
graph.cells[c].nodes[n].output.size())
print("graph.cells[", c, "].nodes[", n-1, "].connections[", cc, "].combined_feature_map.size() = ",
graph.cells[c].nodes[n-1].connections[cc].combined_feature_map.size())
graph.cells[c].nodes[n].output += \
graph.cells[c].nodes[n-1].connections[cc].combined_feature_map + \
graph.cells[c - 1].nodes[NUM_OF_NODES_IN_EACH_CELL - 1].connections[cc].combined_feature_map + \
graph.cells[c - PREVIOUS_PREVIOUS].nodes[NUM_OF_NODES_IN_EACH_CELL - 1].connections[cc].combined_feature_map
print("graph.cells[", c, "].nodes[", n, "].output.grad_fn = ",
graph.cells[c].nodes[n].output.grad_fn)
# 'add' then 'concat' feature maps from different nodes
# needs to take care of tensor dimension mismatch
# See https://github.com/D-X-Y/AutoDL-Projects/issues/99#issuecomment-869100416
graph.cells[c].output += graph.cells[c].nodes[n].output
print("graph.cells[", c, "].output.grad_fn = ",
graph.cells[c].output.grad_fn)
output_tensor = graph.cells[NUM_OF_CELLS-1].output
output_tensor = output_tensor.view(output_tensor.shape[0], -1)
if USE_CUDA:
output_tensor = output_tensor.cuda()
if USE_CUDA:
m_linear = nn.Linear(NUM_OF_IMAGE_CHANNELS * IMAGE_HEIGHT * IMAGE_WIDTH, NUM_OF_IMAGE_CLASSES).cuda()
else:
m_linear = nn.Linear(NUM_OF_IMAGE_CHANNELS * IMAGE_HEIGHT * IMAGE_WIDTH, NUM_OF_IMAGE_CLASSES)
outputs1 = m_linear(output_tensor)
if USE_CUDA:
outputs1 = outputs1.cuda()
print("outputs1.size() = ", outputs1.size())
print("train_labels.size() = ", train_labels.size())
Ltrain = criterion(outputs1, train_labels)
if forward_pass_only == 0:
# backward pass
#Ltrain = Ltrain.requires_grad_()
#Ltrain.retain_grad()
#Ltrain.backward()
# backprop once to get the backward hook results
outputs1.backward(torch.tensor([4, 10],dtype=torch.float),retain_graph=True)
# loss.backward(retain_graph=True) # doesn't work with backward hooks,
# since it's not a network layer but an aggregated result from the outputs of last layer vs target
for c in range(NUM_OF_CELLS):
for n in range(NUM_OF_NODES_IN_EACH_CELL):
# not all nodes have same number of Type-1 output connection
for cc in range(MAX_NUM_OF_CONNECTIONS_PER_NODE - n - 1):
for e in range(NUM_OF_MIXED_OPS):
print('***' * 3 + ' Forward Hooks Inputs & Outputs ' + '***' * 3)
for hook in hookF:
print(hook.input)
print(hook.output)
print('---' * 17)
print('\n')
print('***' * 3 + ' Backward Hooks Inputs & Outputs ' + '***' * 3)
for hook in hookB:
print(hook.input)
print(hook.output)
print('---' * 17)
print("graph.cells[", c, "].nodes[", n, "].connections[", cc, "].f_weights.grad_fn = ",
graph.cells[c].nodes[n].connections[cc].f_weights.grad_fn)
print("graph.cells[", c, "].nodes[", n, "].connections[", cc, "].edges[", e, "].f.weight.grad_fn = ",
graph.cells[c].nodes[n].connections[cc].edges[e].f.weight.grad_fn)
for name, param in graph.named_parameters():
print(name, param.grad)
optimizer1.step()
else:
# no need to save model parameters for next epoch
return Ltrain
# DARTS's approximate architecture gradient. Refer to equation (8)
# needs to save intermediate trained model for Ltrain
path = './model.pth'
torch.save(graph, path)
print("after multiple for-loops")
return Ltrain
def train_architecture(forward_pass_only, train_or_val='val'):
print("Entering train_architecture(), forward_pass_only = ", forward_pass_only, " , train_or_val = ", train_or_val)
graph = Graph()
if USE_CUDA:
graph = graph.cuda()
criterion = nn.CrossEntropyLoss()
optimizer2 = optim.SGD(graph.parameters(), lr=LEARNING_RATE, momentum=MOMENTUM)
# just for initialization, no special meaning
Lval = 0
train_inputs = 0
train_labels = 0
val_inputs = 0
val_labels = 0
if forward_pass_only == 0:
# do train thing for internal NN function weights
graph.train()
# zero the parameter gradients
optimizer2.zero_grad()
print("before multiple for-loops")
for train_data, val_data in (zip(trainloader, valloader)):
train_inputs, train_labels = train_data
val_inputs, val_labels = val_data
if USE_CUDA:
train_inputs = train_inputs.cuda()
train_labels = train_labels.cuda()
val_inputs = val_inputs.cuda()
val_labels = val_labels.cuda()
for epoch in range(NUM_EPOCHS):
# forward pass
# use linear transformation ('weighted sum then concat') to combine results from different nodes
# into an output feature map to be fed into the next neighbour node for further processing
for c in range(NUM_OF_CELLS):
for n in range(NUM_OF_NODES_IN_EACH_CELL):
# not all nodes have same number of Type-1 output connection
for cc in range(MAX_NUM_OF_CONNECTIONS_PER_NODE - n - 1):
for e in range(NUM_OF_MIXED_OPS):
x = 0 # depends on the input tensor dimension requirement
if c == 0:
if train_or_val == 'val':
x = val_inputs
else:
x = train_inputs
else:
# Uses feature map output from previous neighbour node for further processing
x = graph.cells[c].nodes[n-1].connections[cc].combined_feature_map
# need to take care of tensors dimension mismatch
graph.cells[c].nodes[n].connections[cc].combined_feature_map += \
graph.cells[c].nodes[n].connections[cc].edges[e].forward_edge(x) # Lval(w*, alpha)
output2_tensor = graph.cells[NUM_OF_CELLS-1].output
output2_tensor = output2_tensor.view(output2_tensor.shape[0], -1)
if USE_CUDA:
output2_tensor = output2_tensor.cuda()
if USE_CUDA:
m_linear = nn.Linear(NUM_OF_IMAGE_CHANNELS * IMAGE_HEIGHT * IMAGE_WIDTH, NUM_OF_IMAGE_CLASSES).cuda()
else:
m_linear = nn.Linear(NUM_OF_IMAGE_CHANNELS * IMAGE_HEIGHT * IMAGE_WIDTH, NUM_OF_IMAGE_CLASSES)
outputs2 = m_linear(output2_tensor)
if USE_CUDA:
outputs2 = outputs2.cuda()
print("outputs2.size() = ", outputs2.size())
print("val_labels.size() = ", val_labels.size())
print("train_labels.size() = ", train_labels.size())
if train_or_val == 'val':
loss = criterion(outputs2, val_labels)
else:
loss = criterion(outputs2, train_labels)
if forward_pass_only == 0:
# backward pass
Lval = loss
Lval = Lval.requires_grad_()
Lval.backward()
for name, param in graph.named_parameters():
print(name, param.grad)
optimizer2.step()
else:
# no need to save model parameters for next epoch
return loss
# needs to save intermediate trained model for Lval
path = './model.pth'
torch.save(graph, path)
# DARTS's approximate architecture gradient. Refer to equation (8) and https://i.imgur.com/81JFaWc.png
sigma = LEARNING_RATE
epsilon = 0.01 / torch.norm(Lval)
for c in range(NUM_OF_CELLS):
for n in range(NUM_OF_NODES_IN_EACH_CELL):
# not all nodes have same number of Type-1 output connection
for cc in range(MAX_NUM_OF_CONNECTIONS_PER_NODE - n - 1):
CC = graph.cells[c].nodes[n].connections[cc]
for e in range(NUM_OF_MIXED_OPS):
for w in graph.cells[c].nodes[n].connections[cc].edges[e].f.parameters():
# https://mythrex.github.io/math_behind_darts/
# Finite Difference Method
CC.weight_plus = w + epsilon * Lval
CC.weight_minus = w - epsilon * Lval
# Backups original f_weights
CC.f_weights_backup = w
# replaces f_weights with weight_plus before NN training
for c in range(NUM_OF_CELLS):
for n in range(NUM_OF_NODES_IN_EACH_CELL):
# not all nodes have same number of Type-1 output connection
for cc in range(MAX_NUM_OF_CONNECTIONS_PER_NODE - n - 1):
CC = graph.cells[c].nodes[n].connections[cc]
for e in range(NUM_OF_MIXED_OPS):
for w in graph.cells[c].nodes[n].connections[cc].edges[e].f.parameters():
w = CC.weight_plus
# test NN to obtain loss
Ltrain_plus = train_architecture(forward_pass_only=1, train_or_val='train')
# replaces f_weights with weight_minus before NN training
for c in range(NUM_OF_CELLS):
for n in range(NUM_OF_NODES_IN_EACH_CELL):
# not all nodes have same number of Type-1 output connection
for cc in range(MAX_NUM_OF_CONNECTIONS_PER_NODE - n - 1):
CC = graph.cells[c].nodes[n].connections[cc]
for e in range(NUM_OF_MIXED_OPS):
for w in graph.cells[c].nodes[n].connections[cc].edges[e].f.parameters():
w = CC.weight_minus
# test NN to obtain loss
Ltrain_minus = train_architecture(forward_pass_only=1, train_or_val='train')
# Restores original f_weights
for c in range(NUM_OF_CELLS):
for n in range(NUM_OF_NODES_IN_EACH_CELL):
# not all nodes have same number of Type-1 output connection
for cc in range(MAX_NUM_OF_CONNECTIONS_PER_NODE - n - 1):
CC = graph.cells[c].nodes[n].connections[cc]
for e in range(NUM_OF_MIXED_OPS):
for w in graph.cells[c].nodes[n].connections[cc].edges[e].f.parameters():
w = CC.f_weights_backup
print("after multiple for-loops")
L2train_Lval = (Ltrain_plus - Ltrain_minus) / (2 * epsilon)
return Lval - L2train_Lval
if __name__ == "__main__":
run_num = 0
not_converged = 1
while not_converged:
print("run_num = ", run_num)
ltrain = train_NN(forward_pass_only=0)
print("Finished train_NN()")
# 'train_or_val' to differentiate between using training dataset and validation dataset
lval = train_architecture(forward_pass_only=0, train_or_val='val')
print("Finished train_architecture()")
print("lval = ", lval, " , ltrain = ", ltrain)
not_converged = (lval > 0.01) or (ltrain > 0.01)
run_num = run_num + 1
# do test thing
Edit: I changed line 433 to outputs1.backward(torch.ones([4,10], dtype=torch.float, device=torch.device('cuda:0')),retain_graph=True) to get around the RuntimeError , but I have AttributeError: 'Hook' object has no attribute 'input' on line 445
The pytorch hook function issue is solved using this github commit
However, how to use the output of the hook function to solve grad_fn = None broken computational graph issue ?
@ptrblck Someone told me that the grad_fn attribute essentially holds the callback function to backpropagate from a given tensor node. By definition, leaf tensors do not have such function because there is nothing to backpropagate on.
Note: Parameter weights are leaf nodes, i.e. those tensor are not the result of an operation, in other words, there is no other tensor node preceding them.
>>> nn.Linear(1,1).weight.is_leaf
True
What do you think in this case ?
Yes, this is correct and leaf tensors do not have a .grad_fn, as they are manually created.
You should thus check the .grad_fn of the forward activations (i.e. layer outputs) and see if some are detached as described before.
for name, param in graph.named_parameters():
print(name, param.grad)
The above for loop (which is similar to grad_fn in some sense) gave this text output where some of the param.grad are None.
Please correct me if this debugging method is wrong.
@ptrblck Actually I had already used your .grad_fn suggestion previously, but still could not locate the detached layer so far, that is no instance of grad_fn = None in the run console output.
[phung@archlinux gdas]$ git grep -n2 '.grad_fn'
gdas.py-352- graph.cells[c].nodes[n].connections[cc].edges[e].forward_f(x) # Ltrain(w±, alpha)
gdas.py-353-
gdas.py:354: print("graph.cells[", c, "].nodes[", n, "].connections[", cc, "].edge_weights[", e, "].grad_fn = ",
gdas.py:355: graph.cells[c].nodes[n].connections[cc].edge_weights[e].grad_fn)
gdas.py-356-
gdas.py:357: print("graph.cells[", c, "].output.grad_fn = ",
gdas.py:358: graph.cells[c].output.grad_fn)
gdas.py-359-
gdas.py-360- # https://www.reddit.com/r/learnpython/comments/no7btk/how_to_carry_extra_information_across_dag/
--
gdas.py-396- graph.cells[c - PREVIOUS_PREVIOUS].nodes[NUM_OF_NODES_IN_EACH_CELL - 1].connections[cc].combined_feature_map
gdas.py-397-
gdas.py:398: print("graph.cells[", c, "].nodes[", n, "].output.grad_fn = ",
gdas.py:399: graph.cells[c].nodes[n].output.grad_fn)
gdas.py-400-
gdas.py-401- # 'add' then 'concat' feature maps from different nodes
--
gdas.py-404- graph.cells[c].output += graph.cells[c].nodes[n].output
gdas.py-405-
gdas.py:406: print("graph.cells[", c, "].output.grad_fn = ",
gdas.py:407: graph.cells[c].output.grad_fn)
gdas.py-408-
gdas.py-409- output_tensor = graph.cells[NUM_OF_CELLS-1].output
--
gdas.py-444- # for e in range(NUM_OF_MIXED_OPS):
gdas.py-445- # if e == 0: # graph.cells[c].nodes[n].connections[cc].edges[e] == conv2d_edge:
gdas.py:446: # print("graph.cells[", c, "].nodes[", n, "].connections[", cc, "].edges[", e, "].f.weight.grad_fn = ",
gdas.py:447: # graph.cells[c].nodes[n].connections[cc].edges[e].f.weight.grad_fn)
gdas.py-448-
gdas.py-449- for name, param in graph.named_parameters():
[phung@archlinux gdas]$
@ptrblck Since there is no grad_fn = None anymore as well as the values of ltrain and lval are now no longer staying constant, could I assume that the computational graph is no longer broken ?
Note: ltrain and lval still could not converge, fluctuating around values above 1.0
If all activations show a valid .grad_fn and all (expected) parameters show a valid .grad after the backward pass, they you are right and the computation graph is not detached anymore.
for name, param in graph.named_parameters():
print(name, param.grad)
the issue is that my current coding still have None for most of the param.grad in the above for loop.
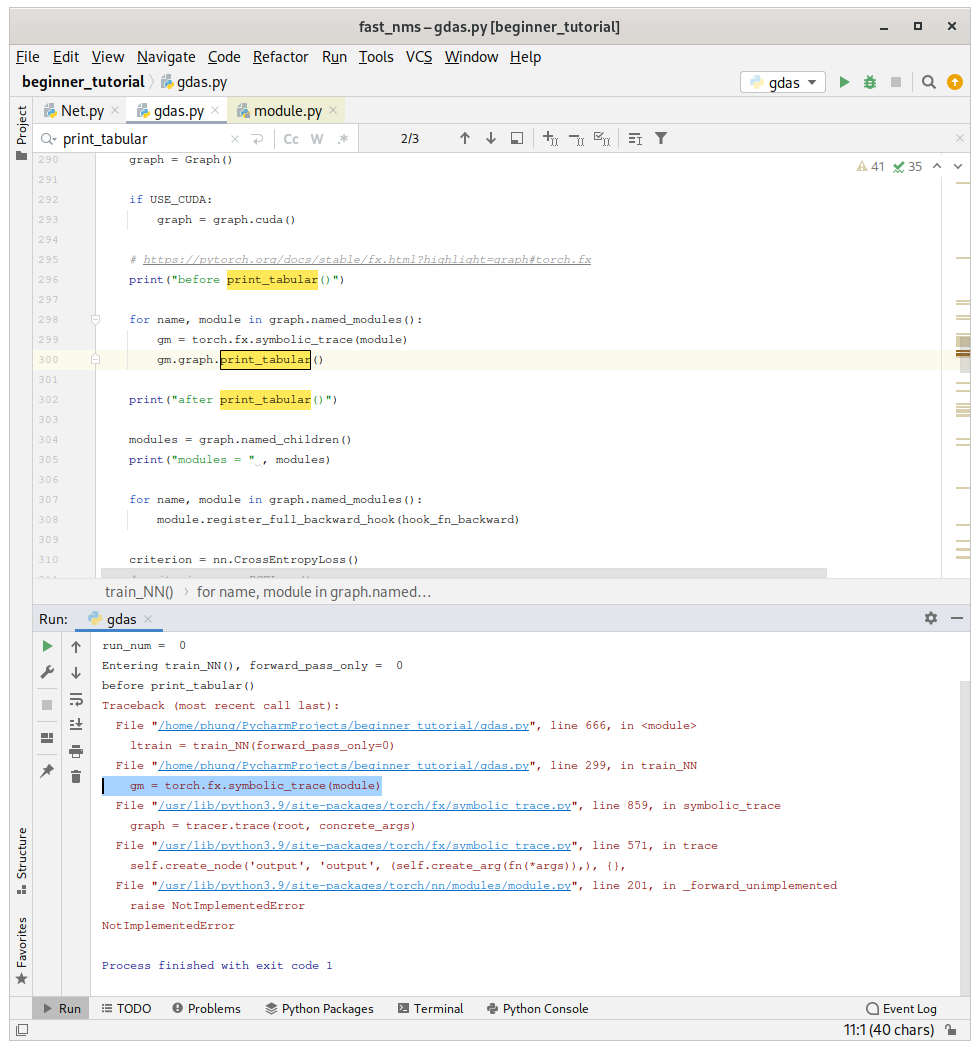
So, I tried to use print_tabular() to help with the debugging.
However, I have the following NotImplementedError
# https://github.com/D-X-Y/AutoDL-Projects/issues/99
import torch
import torch.fx
import torch.utils.data
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
# import numpy as np
torch.autograd.set_detect_anomaly(True)
USE_CUDA = torch.cuda.is_available()
# https://arxiv.org/pdf/1806.09055.pdf#page=12
TEST_DATASET_RATIO = 0.5 # 50 percent of the dataset is dedicated for testing purpose
BATCH_SIZE = 4
NUM_OF_IMAGE_CHANNELS = 3 # RGB
IMAGE_HEIGHT = 32
IMAGE_WIDTH = 32
NUM_OF_IMAGE_CLASSES = 10
SIZE_OF_HIDDEN_LAYERS = 64
NUM_EPOCHS = 1
LEARNING_RATE = 0.025
MOMENTUM = 0.9
NUM_OF_CELLS = 8
NUM_OF_MIXED_OPS = 4
NUM_OF_PREVIOUS_CELLS_OUTPUTS = 2 # last_cell_output , second_last_cell_output
NUM_OF_NODES_IN_EACH_CELL = 4
MAX_NUM_OF_CONNECTIONS_PER_NODE = NUM_OF_NODES_IN_EACH_CELL
NUM_OF_CHANNELS = 16
INTERVAL_BETWEEN_REDUCTION_CELLS = 3
PREVIOUS_PREVIOUS = 2 # (n-2)
REDUCTION_STRIDE = 2
NORMAL_STRIDE = 1
TAU_GUMBEL = 0.5
EDGE_WEIGHTS_NETWORK_IN_SIZE = 5
EDGE_WEIGHTS_NETWORK_OUT_SIZE = 2
# https://pytorch.org/tutorials/beginner/blitz/cifar10_tutorial.html
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=BATCH_SIZE,
shuffle=True, num_workers=2)
valset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform)
valloader = torch.utils.data.DataLoader(valset, batch_size=BATCH_SIZE,
shuffle=False, num_workers=2)
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
TRAIN_BATCH_SIZE = int(len(trainset) * (1 - TEST_DATASET_RATIO))
# https://discordapp.com/channels/687504710118146232/703298739732873296/853270183649083433
# for training for edge weights as well as internal NN function weights
class Edge(nn.Module):
def __init__(self):
super(Edge, self).__init__()
# https://stackoverflow.com/a/51027227/8776167
# self.linear = nn.Linear(EDGE_WEIGHTS_NETWORK_IN_SIZE, EDGE_WEIGHTS_NETWORK_OUT_SIZE)
# https://pytorch.org/docs/stable/generated/torch.nn.parameter.Parameter.html
self.weights = nn.Parameter(torch.zeros(1),
requires_grad=True) # for edge weights, not for internal NN function weights
def __freeze_w(self):
self.weights.requires_grad = False
def __unfreeze_w(self):
self.weights.requires_grad = True
def __freeze_f(self):
for param in self.f.parameters():
param.requires_grad = False
def __unfreeze_f(self):
for param in self.f.parameters():
param.requires_grad = True
# for NN functions internal weights training
def forward_f(self, x):
self.__unfreeze_f()
self.__freeze_w()
# inheritance in python classes and SOLID principles
# https://en.wikipedia.org/wiki/SOLID
# https://blog.cleancoder.com/uncle-bob/2020/10/18/Solid-Relevance.html
return self.f(x)
# self-defined initial NAS architecture, for supernet architecture edge weight training
def forward_edge(self, x):
self.__freeze_f()
self.__unfreeze_w()
return x * self.weights
class ConvEdge(Edge):
def __init__(self, stride):
super().__init__()
self.f = nn.Conv2d(in_channels=3, out_channels=3, kernel_size=(3, 3), stride=(stride, stride), padding=1)
class LinearEdge(Edge):
def __init__(self):
super().__init__()
self.f = nn.Linear(84, 10)
class MaxPoolEdge(Edge):
def __init__(self, stride):
super().__init__()
self.f = nn.MaxPool2d(kernel_size=3, stride=stride, padding=1, ceil_mode=True)
class AvgPoolEdge(Edge):
def __init__(self, stride):
super().__init__()
self.f = nn.AvgPool2d(kernel_size=3, stride=stride, padding=1, ceil_mode=True)
class Skip(nn.Module):
def forward(self, x):
return x
class SkipEdge(Edge):
def __init__(self):
super().__init__()
self.f = Skip()
# to collect and manage different edges between 2 nodes
class Connection(nn.Module):
def __init__(self, stride):
super(Connection, self).__init__()
if USE_CUDA:
# creates distinct edges and references each of them in a list (self.edges)
# self.linear_edge = LinearEdge().cuda()
self.conv2d_edge = ConvEdge(stride).cuda()
self.maxpool_edge = MaxPoolEdge(stride).cuda()
self.avgpool_edge = AvgPoolEdge(stride).cuda()
self.skip_edge = SkipEdge().cuda()
else:
# creates distinct edges and references each of them in a list (self.edges)
# self.linear_edge = LinearEdge()
self.conv2d_edge = ConvEdge(stride)
self.maxpool_edge = MaxPoolEdge(stride)
self.avgpool_edge = AvgPoolEdge(stride)
self.skip_edge = SkipEdge()
# self.edges = [self.conv2d_edge, self.maxpool_edge, self.avgpool_edge, self.skip_edge]
# python list will break the computation graph, need to use nn.ModuleList as a differentiable python list
self.edges = nn.ModuleList([self.conv2d_edge, self.maxpool_edge, self.avgpool_edge, self.skip_edge])
self.edge_weights = torch.zeros(NUM_OF_MIXED_OPS, requires_grad=True)
# for approximate architecture gradient
self.f_weights = torch.zeros(NUM_OF_MIXED_OPS, requires_grad=True)
self.f_weights_backup = torch.zeros(NUM_OF_MIXED_OPS, requires_grad=True)
self.weight_plus = torch.zeros(NUM_OF_MIXED_OPS, requires_grad=True)
self.weight_minus = torch.zeros(NUM_OF_MIXED_OPS, requires_grad=True)
# use linear transformation (weighted summation) to combine results from different edges
self.combined_feature_map = torch.zeros([BATCH_SIZE, NUM_OF_IMAGE_CHANNELS, IMAGE_HEIGHT, IMAGE_WIDTH],
requires_grad=True)
if USE_CUDA:
self.combined_feature_map = self.combined_feature_map.cuda()
for e in range(NUM_OF_MIXED_OPS):
with torch.no_grad():
self.edge_weights[e] = self.edges[e].weights
# https://stackoverflow.com/a/45024500/8776167 extracts the weights learned through NN functions
# self.f_weights[e] = list(self.edges[e].parameters())
# Refer to GDAS equations (5) and (6)
# if one_hot is already there, would summation be required given that all other entries are forced to 0 ?
# It's not required, but you don't know, which index is one hot encoded 1.
# https://pytorch.org/docs/stable/nn.functional.html#gumbel-softmax
gumbel = F.gumbel_softmax(self.edge_weights, tau=TAU_GUMBEL, hard=True)
self.chosen_edge = torch.argmax(gumbel, dim=0) # converts one-hot encoding into integer
# to collect and manage multiple different connections between a particular node and its neighbouring nodes
class Node(nn.Module):
def __init__(self, stride):
super(Node, self).__init__()
# two types of output connections
# Type 1: (multiple edges) output connects to the input of the other intermediate nodes
# Type 2: (single edge) output connects directly to the final output node
# Type 1
self.connections = nn.ModuleList([Connection(stride) for i in range(MAX_NUM_OF_CONNECTIONS_PER_NODE)])
# Type 2
# depends on PREVIOUS node's Type 1 output
self.output = torch.zeros([BATCH_SIZE, NUM_OF_IMAGE_CHANNELS, IMAGE_HEIGHT, IMAGE_WIDTH],
requires_grad=True) # for initialization
if USE_CUDA:
self.output = self.output.cuda()
# to manage all nodes within a cell
class Cell(nn.Module):
def __init__(self, stride):
super(Cell, self).__init__()
# all the coloured edges inside
# https://user-images.githubusercontent.com/3324659/117573177-20ea9a80-b109-11eb-9418-16e22e684164.png
# A single cell contains 'NUM_OF_NODES_IN_EACH_CELL' distinct nodes
# for the k-th node, we have (k+1) preceding nodes.
# Each intermediate state, 0->3 ('NUM_OF_NODES_IN_EACH_CELL-1'),
# is connected to each previous intermediate state
# as well as the output of the previous two cells, c_{k-2} and c_{k-1} (after a preprocessing layer).
# previous_previous_cell_output = c_{k-2}
# previous_cell_output = c{k-1}
self.nodes = nn.ModuleList([Node(stride) for i in range(NUM_OF_NODES_IN_EACH_CELL)])
# just for variables initialization
self.previous_cell = 0
self.previous_previous_cell = 0
self.output = torch.zeros([BATCH_SIZE, NUM_OF_IMAGE_CHANNELS, IMAGE_HEIGHT, IMAGE_WIDTH],
requires_grad=True)
if USE_CUDA:
self.output = self.output.cuda()
for n in range(NUM_OF_NODES_IN_EACH_CELL):
# 'add' then 'concat' feature maps from different nodes
# needs to take care of tensor dimension mismatch
# See https://github.com/D-X-Y/AutoDL-Projects/issues/99#issuecomment-869100416
self.output = self.output + self.nodes[n].output
# to manage all nodes
class Graph(nn.Module):
def __init__(self):
super(Graph, self).__init__()
stride = 0 # just to initialize a variable
for i in range(NUM_OF_CELLS):
if i % INTERVAL_BETWEEN_REDUCTION_CELLS == 0:
stride = REDUCTION_STRIDE # to emulate reduction cell by using normal cell with stride=2
else:
stride = NORMAL_STRIDE # normal cell
self.cells = nn.ModuleList([Cell(stride) for i in range(NUM_OF_CELLS)])
total_grad_out = []
total_grad_in = []
def hook_fn_backward (module, grad_input, grad_output):
print (module) # for distinguishing module
# In order to comply with the order back-propagation, let's print grad_output
print ( 'grad_output', grad_output)
# Reprint grad_input
print ( 'grad_input', grad_input)
# Save to global variables
total_grad_in.append (grad_input)
total_grad_out.append (grad_output)
# https://translate.google.com/translate?sl=auto&tl=en&u=http://khanrc.github.io/nas-4-darts-tutorial.html
def train_NN(forward_pass_only):
print("Entering train_NN(), forward_pass_only = ", forward_pass_only)
graph = Graph()
if USE_CUDA:
graph = graph.cuda()
# https://pytorch.org/docs/stable/fx.html?highlight=graph#torch.fx
print("before print_tabular()")
for name, module in graph.named_modules():
gm = torch.fx.symbolic_trace(module)
gm.graph.print_tabular()
print("after print_tabular()")
modules = graph.named_children()
print("modules = " , modules)
for name, module in graph.named_modules():
module.register_full_backward_hook(hook_fn_backward)
criterion = nn.CrossEntropyLoss()
# criterion = nn.BCELoss()
optimizer1 = optim.SGD(graph.parameters(), lr=LEARNING_RATE, momentum=MOMENTUM)
# just for initialization, no special meaning
Ltrain = 0
train_inputs = 0
train_labels = 0
if forward_pass_only == 0:
# do train thing for architecture edge weights
graph.train()
# zero the parameter gradients
optimizer1.zero_grad()
print("before multiple for-loops")
for train_data, val_data in (zip(trainloader, valloader)):
train_inputs, train_labels = train_data
# val_inputs, val_labels = val_data
if USE_CUDA:
train_inputs = train_inputs.cuda()
train_labels = train_labels.cuda()
for epoch in range(NUM_EPOCHS):
# forward pass
for c in range(NUM_OF_CELLS):
for n in range(NUM_OF_NODES_IN_EACH_CELL):
# not all nodes have same number of Type-1 output connection
for cc in range(MAX_NUM_OF_CONNECTIONS_PER_NODE - n - 1):
for e in range(NUM_OF_MIXED_OPS):
if c == 0:
x = train_inputs
else:
if n == 0:
# Uses feature map output from previous neighbour cell for further processing
x = graph.cells[c-1].nodes[NUM_OF_NODES_IN_EACH_CELL-1].connections[cc].combined_feature_map
else:
# Uses feature map output from previous neighbour node for further processing
x = graph.cells[c].nodes[n-1].connections[cc].combined_feature_map
if USE_CUDA:
x = x.cuda()
# combines all the feature maps from different mixed ops edges
graph.cells[c].nodes[n].connections[cc].combined_feature_map = \
graph.cells[c].nodes[n].connections[cc].combined_feature_map + \
graph.cells[c].nodes[n].connections[cc].edges[e].forward_f(x) # Ltrain(w±, alpha)
print("graph.cells[", c, "].nodes[", n, "].connections[", cc, "].edge_weights[", e, "].grad_fn = ",
graph.cells[c].nodes[n].connections[cc].edge_weights[e].grad_fn)
print("graph.cells[", c, "].output.grad_fn = ",
graph.cells[c].output.grad_fn)
# https://www.reddit.com/r/learnpython/comments/no7btk/how_to_carry_extra_information_across_dag/
# https://docs.python.org/3/tutorial/datastructures.html
# generates a supernet consisting of 'NUM_OF_CELLS' cells
# each cell contains of 'NUM_OF_NODES_IN_EACH_CELL' nodes
# refer to PNASNet https://arxiv.org/pdf/1712.00559.pdf#page=5 for the cell arrangement
# https://pytorch.org/tutorials/beginner/examples_autograd/two_layer_net_custom_function.html
# encodes the cells and nodes arrangement in the multigraph
if c > 1: # for previous_previous_cell, (c-2)
graph.cells[c].previous_cell = graph.cells[c - 1].output
graph.cells[c].previous_previous_cell = graph.cells[c - PREVIOUS_PREVIOUS].output
if n == 0:
if c <= 1:
graph.cells[c].nodes[n].output = graph.cells[c].nodes[n].connections[cc].combined_feature_map
else: # there is no input from previous cells for the first two cells
# needs to take care tensor dimension mismatch from multiple edges connections
graph.cells[c].nodes[n].output += \
graph.cells[c-1].nodes[NUM_OF_NODES_IN_EACH_CELL-1].connections[cc].combined_feature_map + \
graph.cells[c-PREVIOUS_PREVIOUS].nodes[NUM_OF_NODES_IN_EACH_CELL-1].connections[cc].combined_feature_map
else: # n > 0
# depends on PREVIOUS node's Type 1 connection
# needs to take care tensor dimension mismatch from multiple edges connections
print("graph.cells[", c ,"].nodes[" ,n, "].output.size() = ",
graph.cells[c].nodes[n].output.size())
print("graph.cells[", c, "].nodes[", n-1, "].connections[", cc, "].combined_feature_map.size() = ",
graph.cells[c].nodes[n-1].connections[cc].combined_feature_map.size())
graph.cells[c].nodes[n].output += \
graph.cells[c].nodes[n-1].connections[cc].combined_feature_map + \
graph.cells[c - 1].nodes[NUM_OF_NODES_IN_EACH_CELL - 1].connections[cc].combined_feature_map + \
graph.cells[c - PREVIOUS_PREVIOUS].nodes[NUM_OF_NODES_IN_EACH_CELL - 1].connections[cc].combined_feature_map
print("graph.cells[", c, "].nodes[", n, "].output.grad_fn = ",
graph.cells[c].nodes[n].output.grad_fn)
# 'add' then 'concat' feature maps from different nodes
# needs to take care of tensor dimension mismatch
# See https://github.com/D-X-Y/AutoDL-Projects/issues/99#issuecomment-869100416
graph.cells[c].output += graph.cells[c].nodes[n].output
print("graph.cells[", c, "].output.grad_fn = ",
graph.cells[c].output.grad_fn)
output_tensor = graph.cells[NUM_OF_CELLS-1].output
output_tensor = output_tensor.view(output_tensor.shape[0], -1)
if USE_CUDA:
output_tensor = output_tensor.cuda()
if USE_CUDA:
m_linear = nn.Linear(NUM_OF_IMAGE_CHANNELS * IMAGE_HEIGHT * IMAGE_WIDTH, NUM_OF_IMAGE_CLASSES).cuda()
else:
m_linear = nn.Linear(NUM_OF_IMAGE_CHANNELS * IMAGE_HEIGHT * IMAGE_WIDTH, NUM_OF_IMAGE_CLASSES)
outputs1 = m_linear(output_tensor)
if USE_CUDA:
outputs1 = outputs1.cuda()
print("outputs1.size() = ", outputs1.size())
print("train_labels.size() = ", train_labels.size())
Ltrain = criterion(outputs1, train_labels)
if forward_pass_only == 0:
# backward pass
Ltrain = Ltrain.requires_grad_()
Ltrain.retain_grad()
Ltrain.register_hook(lambda x: print(x))
Ltrain.backward()
# for c in range(NUM_OF_CELLS):
# for n in range(NUM_OF_NODES_IN_EACH_CELL):
# # not all nodes have same number of Type-1 output connection
# for cc in range(MAX_NUM_OF_CONNECTIONS_PER_NODE - n - 1):
# for e in range(NUM_OF_MIXED_OPS):
# if e == 0: # graph.cells[c].nodes[n].connections[cc].edges[e] == conv2d_edge:
# print("graph.cells[", c, "].nodes[", n, "].connections[", cc, "].edges[", e, "].f.weight.grad_fn = ",
# graph.cells[c].nodes[n].connections[cc].edges[e].f.weight.grad_fn)
print("starts to print graph.named_parameters()")
for name, param in graph.named_parameters():
print(name, param.grad)
print("finished printing graph.named_parameters()")
optimizer1.step()
else:
# no need to save model parameters for next epoch
return Ltrain
# DARTS's approximate architecture gradient. Refer to equation (8)
# needs to save intermediate trained model for Ltrain
path = './model.pth'
torch.save(graph, path)
print("after multiple for-loops")
return Ltrain
def train_architecture(forward_pass_only, train_or_val='val'):
print("Entering train_architecture(), forward_pass_only = ", forward_pass_only, " , train_or_val = ", train_or_val)
graph = Graph()
if USE_CUDA:
graph = graph.cuda()
criterion = nn.CrossEntropyLoss()
optimizer2 = optim.SGD(graph.parameters(), lr=LEARNING_RATE, momentum=MOMENTUM)
# just for initialization, no special meaning
Lval = 0
train_inputs = 0
train_labels = 0
val_inputs = 0
val_labels = 0
if forward_pass_only == 0:
# do train thing for internal NN function weights
graph.train()
# zero the parameter gradients
optimizer2.zero_grad()
print("before multiple for-loops")
for train_data, val_data in (zip(trainloader, valloader)):
train_inputs, train_labels = train_data
val_inputs, val_labels = val_data
if USE_CUDA:
train_inputs = train_inputs.cuda()
train_labels = train_labels.cuda()
val_inputs = val_inputs.cuda()
val_labels = val_labels.cuda()
for epoch in range(NUM_EPOCHS):
# forward pass
# use linear transformation ('weighted sum then concat') to combine results from different nodes
# into an output feature map to be fed into the next neighbour node for further processing
for c in range(NUM_OF_CELLS):
for n in range(NUM_OF_NODES_IN_EACH_CELL):
# not all nodes have same number of Type-1 output connection
for cc in range(MAX_NUM_OF_CONNECTIONS_PER_NODE - n - 1):
for e in range(NUM_OF_MIXED_OPS):
x = 0 # depends on the input tensor dimension requirement
if c == 0:
if train_or_val == 'val':
x = val_inputs
else:
x = train_inputs
else:
# Uses feature map output from previous neighbour node for further processing
x = graph.cells[c].nodes[n-1].connections[cc].combined_feature_map
# need to take care of tensors dimension mismatch
graph.cells[c].nodes[n].connections[cc].combined_feature_map += \
graph.cells[c].nodes[n].connections[cc].edges[e].forward_edge(x) # Lval(w*, alpha)
output2_tensor = graph.cells[NUM_OF_CELLS-1].output
output2_tensor = output2_tensor.view(output2_tensor.shape[0], -1)
if USE_CUDA:
output2_tensor = output2_tensor.cuda()
if USE_CUDA:
m_linear = nn.Linear(NUM_OF_IMAGE_CHANNELS * IMAGE_HEIGHT * IMAGE_WIDTH, NUM_OF_IMAGE_CLASSES).cuda()
else:
m_linear = nn.Linear(NUM_OF_IMAGE_CHANNELS * IMAGE_HEIGHT * IMAGE_WIDTH, NUM_OF_IMAGE_CLASSES)
outputs2 = m_linear(output2_tensor)
if USE_CUDA:
outputs2 = outputs2.cuda()
print("outputs2.size() = ", outputs2.size())
print("val_labels.size() = ", val_labels.size())
print("train_labels.size() = ", train_labels.size())
if train_or_val == 'val':
loss = criterion(outputs2, val_labels)
else:
loss = criterion(outputs2, train_labels)
if forward_pass_only == 0:
# backward pass
Lval = loss
Lval = Lval.requires_grad_()
Lval.backward()
for name, param in graph.named_parameters():
print(name, param.grad)
optimizer2.step()
else:
# no need to save model parameters for next epoch
return loss
# needs to save intermediate trained model for Lval
path = './model.pth'
torch.save(graph, path)
# DARTS's approximate architecture gradient. Refer to equation (8) and https://i.imgur.com/81JFaWc.png
sigma = LEARNING_RATE
epsilon = 0.01 / torch.norm(Lval)
for c in range(NUM_OF_CELLS):
for n in range(NUM_OF_NODES_IN_EACH_CELL):
# not all nodes have same number of Type-1 output connection
for cc in range(MAX_NUM_OF_CONNECTIONS_PER_NODE - n - 1):
CC = graph.cells[c].nodes[n].connections[cc]
for e in range(NUM_OF_MIXED_OPS):
for w in graph.cells[c].nodes[n].connections[cc].edges[e].f.parameters():
# https://mythrex.github.io/math_behind_darts/
# Finite Difference Method
CC.weight_plus = w + epsilon * Lval
CC.weight_minus = w - epsilon * Lval
# Backups original f_weights
CC.f_weights_backup = w
# replaces f_weights with weight_plus before NN training
for c in range(NUM_OF_CELLS):
for n in range(NUM_OF_NODES_IN_EACH_CELL):
# not all nodes have same number of Type-1 output connection
for cc in range(MAX_NUM_OF_CONNECTIONS_PER_NODE - n - 1):
CC = graph.cells[c].nodes[n].connections[cc]
for e in range(NUM_OF_MIXED_OPS):
for w in graph.cells[c].nodes[n].connections[cc].edges[e].f.parameters():
w = CC.weight_plus
# test NN to obtain loss
Ltrain_plus = train_architecture(forward_pass_only=1, train_or_val='train')
# replaces f_weights with weight_minus before NN training
for c in range(NUM_OF_CELLS):
for n in range(NUM_OF_NODES_IN_EACH_CELL):
# not all nodes have same number of Type-1 output connection
for cc in range(MAX_NUM_OF_CONNECTIONS_PER_NODE - n - 1):
CC = graph.cells[c].nodes[n].connections[cc]
for e in range(NUM_OF_MIXED_OPS):
for w in graph.cells[c].nodes[n].connections[cc].edges[e].f.parameters():
w = CC.weight_minus
# test NN to obtain loss
Ltrain_minus = train_architecture(forward_pass_only=1, train_or_val='train')
# Restores original f_weights
for c in range(NUM_OF_CELLS):
for n in range(NUM_OF_NODES_IN_EACH_CELL):
# not all nodes have same number of Type-1 output connection
for cc in range(MAX_NUM_OF_CONNECTIONS_PER_NODE - n - 1):
CC = graph.cells[c].nodes[n].connections[cc]
for e in range(NUM_OF_MIXED_OPS):
for w in graph.cells[c].nodes[n].connections[cc].edges[e].f.parameters():
w = CC.f_weights_backup
print("after multiple for-loops")
L2train_Lval = (Ltrain_plus - Ltrain_minus) / (2 * epsilon)
return Lval - L2train_Lval
if __name__ == "__main__":
run_num = 0
not_converged = 1
while not_converged:
print("run_num = ", run_num)
ltrain = train_NN(forward_pass_only=0)
print("Finished train_NN()")
# 'train_or_val' to differentiate between using training dataset and validation dataset
lval = train_architecture(forward_pass_only=0, train_or_val='val')
print("Finished train_architecture()")
print("lval = ", lval, " , ltrain = ", ltrain)
not_converged = (lval > 0.01) or (ltrain > 0.01)
run_num = run_num + 1
# do test thing
This could either mean that the computation graph is still detached (and your previous check missed sme activations) or that these parameters were never used in the forward pass and thus also won’t get any gradients.
I would probably try to scale down the use case while debugging these issues and remove torch.fx for now as it seems you are trying to fix several issues at once, which could be unnecessarily hard.